







第一节:文本分类的任务
1,为目标文本分配类别,主题,或者流派
2,垃圾邮件识别
3,作者身份识别
4,年龄,性别的识别
5,语言的识别
6,情感分析
文本分类的定义:输入:1,文档d,2,类的一个混合的集合 C = {c1,c2,c3....cj};输出:一个预测类c,这个类属于集合C .
分类的方法:1、手写规则,规则是由单词和其他特征组合而成,精度很高,但是成本昂贵。2,、有指导的机器学习,输入文档d和类的一个混合集合,还有一个文档训练集合,用手工的方式标注文档(d1,c1)...(dm,cm);输出一个学习过的分类器gama:可以将d分类到某一类c中去,即d->c。这样的分类器有:朴素贝叶斯分类器,线性回归分类器,支持向量机分类器,K-紧邻分类器,Naive Bayes,Logistic regression,Support_vector machine,K-Nearest Neighbors。
第二节:朴素贝叶斯
朴素贝叶斯,基于贝叶斯公式和词袋原理,词袋原理忽略了单词的位置等其他特征,他表示的就是单词在文本出现的次数。
我们最后计算的目的就是计算文档d在类c中的概率。文档d 可以用那些特征词来代替。
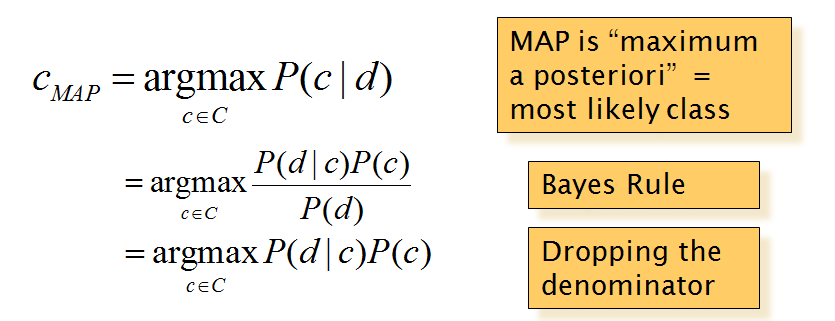
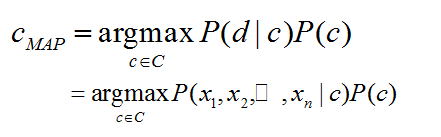
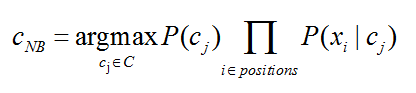
未完待续。。。。















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









