







一般使用引号(包括单引号和双引号以及三引号)来创建字符串,创建字符串很简单,只要为变量分配⼀个值即可




可以看到python中,单引号和双引号没有任何区别,三引号用于多行字符串的书写;但是当要输出单引号时,此时就不能用单引号来定义字符串了


字符串的输出与输入

在python中用input()函数来输入字符串


注意:input 函数输入的类容默认都是字符串,如果要转换成其他类型,需要用到字符转换函数;
字符串的拼接
1)逗号拼接/加号拼接
a = 'are'
b = 'you'
c = 'ok'
d = a, b, c#这样的结果是个元组
print(a, b, c) #逗号拼接,默认在中间会插入空格
d = a + b + c
print(d)
a = 123
b = 456
print(a, b)
print(a + b)#对数字拼接时,此时执行加法运算结果如下:
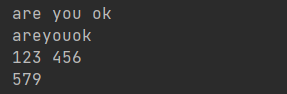
需要注意,加号无法拼接不同类型的变量,如加号在拼接数字和字符串是会被认为执行加法运算,结果会报错,如下:
c = 'nihao'
print(a + c)
其次,使用 加号拼接str和unicode会有UnicodeDecodeError,该问题仅在 python2 中会遇到,因为python2当中的string编码为ascii,若要使用Unicode,需要在字符串前面加一个u;而到了python3中,所有的字符串编码都默认是Unicode了
#code
a = '中文'
b = u'中文'
print a, b
print a + b
#output
中文 中文
Traceback (most recent call last):
File "test.py", line 5, in <module>
print a + b
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)2)直接拼接
该方法只能用于字符串的拼接,不能用于变量拼接
#code
print('abc''xyz')
#output
adcxyz3)使用 % 或者 format 拼接-常用
该方法借鉴于C语言的printf函数,多个变量是倾向于使用这种方法,因为它的可读性更强
a = 'are'
b = 'you'
c = 'ok'
d = 'hi%s' %a
print(d)
print('abc{0}{1}{2}' .format(a, b, c))
![]()
4)使用字符串函数 join 拼接
该方法多用于列表,元组,或者较大的字符串拼接操作,join是字符串的函数
a = 'are'
b = 'you'
c = 'ok'
d = (a, b, c)#元组
e = [a, b, c]#列表
f = ''
print(f.join(d))
print(f.join(e))字符串切片
切片是对操作的对象截取一部分的操作,字符串、列表和元组都支持切片操作
语法:
序列[开始位置下标:结束位置下标:步长]注意:切片的范围为左闭右开;步长是选取间隔,正负数都可以,默认为1


最后一次,由于步长为-1表示从右往左选取,而步长为-5~-3表示从左往右选取,所以截取的结果为空
字符串的操作方法
1.查找
所谓字符串查找方法即是查找子串在字符串中的位置或者出现的次数
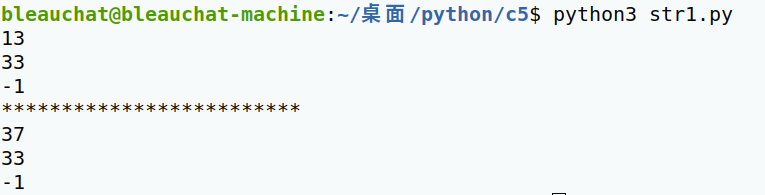
- find() 检查某个子串是否出现在这个字符串中,如果存在则返回子串的下标,否则返回-1
语法:
字符串序列.find(子串, 开始位置下标,结束位置下标)注意:开始和结束下标可以省略,省略表示在整个字符串内查找
- index() 检查某个子串是否出现在这个字符串中,如果存在则返回子串的下标,否则报错
语法:
字符串序列.index(子串, 开始位置下标,结束位置下标)注意:开始和结束下标可以省略,省略表示在整个字符串内查找


- count() 检查子串在字符串中出现的次数并返回
语法:
字符串序列.count(子串, 开始位置下标,结束位置下标)注意:开始和结束下标可以省略,省略表示在整个字符串内查找


- rfind() 与find用法相同,只不过是从右侧开始查找
- rindex() 与index()用法相同,但查找方向从右侧开始



2.修改
所谓修改就是通过函数修改字符串中的数据
- replace() 替换,返回替换后的字符串
语法:
字符串序列.replace(旧子串,新子串,替换次数)注意:替换次数可以省略,省略代表全部替换


可以看到原字符串并没有改变,这说明字符串是不可变类型
- split() 按照指定字符分割字符串,返回一个列表
语法:
字符串.split(分割字符,分割次数) #返回的列表长度为分割次数+1,并且丢失分割字符

注意:如果分割字符是原字符串的子串,分割后原子串后丢失
- join() 用一个字符或子串作为连接符将序列合并为一个字符串,并返回该字符串
语法:
字符或子串.join(多字符串组成的序列)

- capitalize() 将字符串的第一个字符转换为大写,其余全都为小写,并返回


- title() 将字符串的每个单词的首个字符转换为大写,其余全都为小写,并返回


- lower() 将字符串中的大写转换为小写并返回
- upper() 将字符串中的小写转换为大写并返回


- lstrip() 删除字符串左侧空白字符并返回
- rstrip() 删除字符串右侧空白字符并返回
- strip() 删除字符串两侧的空白字符并返回


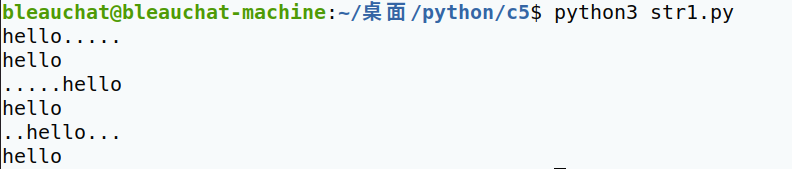
- ljust() 将字符串左对齐,并使用指定的字符(默认为空格)填充到对应长度的新字符串,然后返回
- rjust() 将字符串右对齐,并使用指定的字符(默认为空格)填充到对应长度的新字符串,然后返回
- center() 将字符串中间对齐,并使用指定的字符(默认为空格)填充到对应长度的新字符串,然后返回
语法:
字符串.ljust(长度, 填充字符)
字符串.rjust(长度, 填充字符)
字符串.center(长度, 填充字符) #当原字符串长度不够时才会填充
3. 判断
判断真假,返回的是布尔类型:True或False
- startswith() 检查字符串是否以指定的子串开头,如果是返回True,否则返回False
- endswith() 检查字符串是否以指定的子串开头,如果是返回True,否则返回False
语法:
字符串.startswith(子串,开始位置下标,结束位置下标)
字符串.endswith(子串,开始位置下标,结束位置下标)
#不带后两个参数表示搜索整个字符串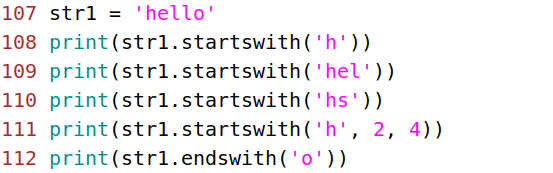

- isalpha() 如果字符串至少有一个字符且所有的字符都是字母则返回True,否则返回False
- isdigit() 如果字符串只包含数字则返回True,否则返回False
- isalnum() 如果字符串至少有1个字符并且所有的字符都是字母或数字则返回True,否则返回False
- isspace() 如果字符串中只包含空格则返回True,否则返回False


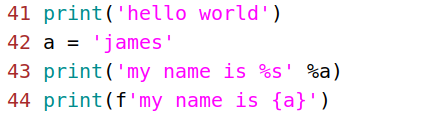
python 格式化字符串的3种方法
1)使用 %占位符 的格式
age = 23
name = 'tom'
info = 'age is %d, name is %s' %(age, name)
print(info)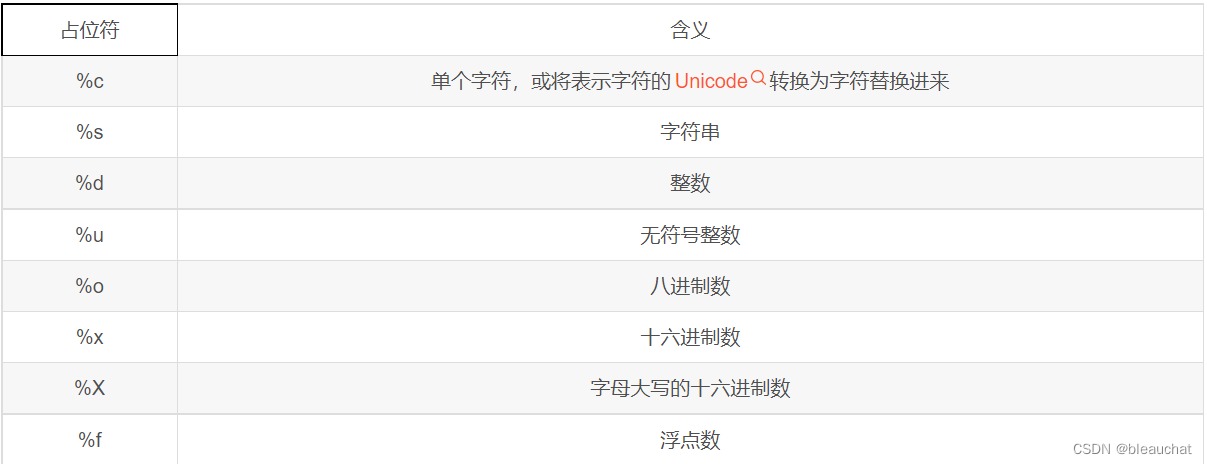
2)format 方法
age = 23
name = 'tom'
info = 'age is {0}, name is {1}' .format(age, name)#{0}对应第1个参数
print(info)3)f’str
age = 23
name = 'tom'
info = f'age is {age}, name is {name}'#f'{变量名}'
print(info)这三种方式在格式化输出输入一节也有介绍,这里做个总结;















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









