







循环神经网络
循环神经网络(RNN)是一个数学模型,是一个基础的思想的实现,用来做序列信息的预测,比如文本、翻译、推荐等。若要做实际的文本预测的话只用RNN还是不行,它的缺点很多,比如无法关注一个太长的句子。要用到基于RNN的LSTM、BiLSTM等之类的模型。
在【人工智能学习】【五】语言模型中介绍了如何将文本信息通过分词、建立字典来向量化。本篇文章在此基础上,对向量数据进行训练、预测,包括正向计算、损失计算、反向传播等前几篇文章都提到过的事。本篇文章要做的事,是用RNN预测输入数据的后面若干的字符,类似于输入法的提示功能。
首先明确两个问题:
- RNN的输入是根据时间序列输入的一个一个字符/词
- RNN的训练输出是根据输入数据往后移动一位字符/词
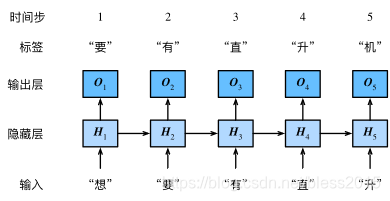
意思是若要训练“我想要带你去浪漫的土耳其”这句话,输入‘我’、‘想’、‘要’、‘带’、‘你’,要输出‘想’、‘要’、‘带’、‘你’、‘去’
这只是一个例子,是RNN能做的事情之一,不是唯一。本质上这还是一个预测模型,关于预测什么、如何预测是要看具体应用场景的。
RNN有几种输出形式
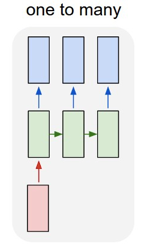

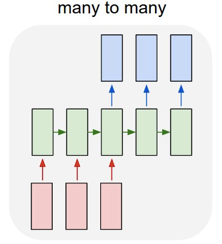
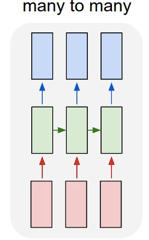
下面输出入,上面是输出。本篇文章介绍的是第四种,第四种的模型如下

是不是相当抽象,不理解大牛的想法,反正这张图我是看了半天,最后得出结论:依然看不懂。现在我对RNN有些理解后,看这张图还是觉得有迷惑性,网上说左边是RNN的模型图,后面是展开后的图。可是我觉得就应该是后面这张图,第一张就是负责让人看不懂的。(其实我想说上面这张图也很烂好吗,但是找了半天找不到别的,
A
A
A是啥啊,这么不负责任的标一个体现不出含义的
A
A
A和
h
1
h_1
h1、
h
2
.
.
.
h_2...
h2...,中间的A是隐含层,好歹用一个
H
H
H来表示hidden,然后上面的
h
h
h是输出,好歹用一个
y
y
y或者
o
o
o也行啊)
对着下面这个图看公式吧,但是这个图里又么有
X
X
X了,手动标记
X
X
X为输入,输出为
Y
Y
Y
RNN公式
H
t
=
f
(
X
t
W
x
h
+
H
h
−
1
W
h
h
+
b
h
)
H_t=f(X_tW_{xh}+H_{h-1}W_{hh}+b_h)
Ht=f(XtWxh+Hh−1Whh+bh)
Y
=
H
t
W
h
y
+
b
y
Y=H_tW_{hy}+b_y
Y=HtWhy+by
前面的文章【人工智能学习】【三】多层感知机中,神经元之间是相互独立的,神经元只和前后相连的神经元有计算上的联系。RNN特殊的地方是它神经元之间是有计算联系的,体现在工事中就是
H
h
−
1
W
h
h
H_{h-1}W_{hh}
Hh−1Whh这一项。
这个式子需要训练的变量有
W
x
h
W_{xh}
Wxh、
W
h
h
W_{hh}
Whh、
W
h
y
W_{hy}
Why、
b
h
b_h
bh、
b
y
b_y
by,来看下他们的结构。
设输入X的向量长度(inputsize)为100,隐含层神经元个数为256,输入向量也是100,那么
W
x
h
:
100
∗
256
W_{xh}:100*256
Wxh:100∗256
W
h
h
:
256
∗
256
W_{hh}:256*256
Whh:256∗256
W
h
y
:
256
∗
100
W_{hy}:256*100
Why:256∗100
b
h
:
1
∗
256
b_h:1*256
bh:1∗256
b
y
:
1
∗
100
b_y:1*100
by:1∗100
后面计算呢,依然是mini-batch,所以输入将会是一个 m i n i − b a t c h ∗ i n p u t s i z e mini-batch*inputsize mini−batch∗inputsize矩阵,后来再来看是如何做的,这里还是要说一下,这个输入不是随便一篇文章从头计算到尾,而是用到【人工智能学习】【五】语言模型里提到的采样。
one-hot向量
之前我们把句子转换成了向量,但那个向量里存储的是字符或词的所在字典里的索引位置,比如
[5,8,3,2,6]
one-hot是将项目的向量在做一步转换,在已知字典大小为10的情况下,上面的向量经过one-hot编码变成如下形式
[0,0,0,0,0,1,0,0,0,0,0] 5
[0,0,0,0,0,0,0,0,1,0,0] 8
[0,0,0,1,0,0,0,0,0,0,0] 3
[0,0,1,0,0,0,0,0,0,0,0] 2
[0,0,0,0,0,0,1,0,0,0,0] 6
这个矩阵有没有感觉很稀疏,0太多了。所以后来又有一种编码方式embedding,现在比较常用,篇幅有限不再解释。
代码
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype) # shape: (n, n_class)
print('第一步结束后的result',result)
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
print('第二步结束后的result',result)
return result
# 初始化一个x矩阵(1*2)的 用来做测试
x = torch.tensor([0, 2])
# 定义字典大小为10
vocab_size = 10
x_one_hot = one_hot(x, vocab_size)
第一步结束后的result
tensor([
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]
])
第一步结束后的result
tensor([
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.]
])
这个vocab_size字典长度是在做训练时,预先做好分词,创建字典后,已知的长度。
因为每次是小批量训练,会一次输入多个x向量,所以在封装一次
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
这里的
X
X
X是个二维batch-size*vocab-size大小的矩阵。
设
X
X
X=[[4.2.1.5],[0,3,9,6]]我们如果取X[:, 0],输入到one_hot函数中的矩阵为[4,0],X[:, i]这个操作会把取到的数据按行resize。顺便在记录下X.shape[1]里的shape[1],当X是2维及以上时,才会有shape[0]表示行的大小,shape[1]表示列的大小。如果X是1维的,那shape[0]就表示的数据长度,或者说表示列的大小。
实现
导入包
import torch
import torch.nn as nn
import time
import math
import sys
初始化参数
这里应该熟悉了,就是上面提到的
W
x
h
:
100
∗
256
W_{xh}:100*256
Wxh:100∗256
W
h
h
:
256
∗
256
W_{hh}:256*256
Whh:256∗256
W
h
y
:
256
∗
100
W_{hy}:256*100
Why:256∗100
b
h
:
1
∗
256
b_h:1*256
bh:1∗256
b
y
:
1
∗
100
b_y:1*100
by:1∗100
num_inputs, num_hiddens, num_outputs = 100, 256, 100
# num_inputs: d
# num_hiddens: h, 隐藏单元的个数是超参数
# num_outputs: q
def get_params():
def _one(shape):
param = torch.zeros(shape, dtype=torch.float32)
nn.init.normal_(param, 0, 0.01)
return torch.nn.Parameter(param)
# 隐藏层参数
W_xh = _one((num_inputs, num_hiddens))
W_hh = _one((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens, device=device))
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device))
return (W_xh, W_hh, b_h, W_hq, b_q)
定义模型
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
和我们的公式对比一下
H
t
=
f
(
X
t
W
x
h
+
H
h
−
1
W
h
h
+
b
h
)
H_t=f(X_tW_{xh}+H_{h-1}W_{hh}+b_h)
Ht=f(XtWxh+Hh−1Whh+bh)
假设输入
X
X
X torch.Size([2, 5]) 2*5的矩阵
num_hiddens=256
vocab_size=1024
则将
X
X
X经过one-hot后,输入尺寸变成[2, 1027]
output尺寸[2, 1027] 别忘了我们用的最后一张图的RNN(多对多)
state尺寸[2, 256]
state是体现RNN特点的一个值,即神经元之间存在联系,这个联系的值就是state。初始化为0,第一次次计算完后,state的值为 H t = f ( X t W x h + b h ) H_t=f(X_tW_{xh}+b_h) Ht=f(XtWxh+bh)(可见 H t H_t Ht这个值有两个地方用了,一个是给输出用,一个是是保存起来给下一个神经元了), H t H_t Ht作为下一次的state传入函数中计算。
然后是 Y Y Y, Y Y Y是神经元的输出,每次计算一个num_step后都会得到一个输出,通过
outputs.append(Y)
保存起来每次输出结果进行输出。
困惑度评价
把交叉熵得到的值再经过 e x e^x ex算一遍,网上说为的是提高数值的可读性。困惑度越低语言模型越好。
最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
梯度剪裁
RNN由于是按时间序列进行反向传播,传播的距离会比较长,容易产生梯度爆炸的问题。这时候要控制梯度大小。
有一种剪裁方式比较好理解,设定一个区间
[
−
1
,
1
]
[-1,1]
[−1,1],
g
r
a
d
=
m
i
n
m
a
x
[
−
1
,
1
]
grad=minmax[-1,1]
grad=minmax[−1,1],不知道这样写对不对的,就是不能比-1小,不能比1大。
另一种给定一个缩放阈值
α
\alpha
α,对经过一次反向传播后的所有参数的梯度求二范数,开根号,求出来加入是
n
n
n。如果
n
>
α
n>\alpha
n>α,那么所有梯度要缩小一个比例:
α
n
\frac{\alpha}{n}
nα
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
定义模型训练函数
- 采样,采用的采样方法不同会导致隐藏状态初始化方式发生变化
对数据集进行采样,得到X和Y,现在的X、Y值如下:(我没认真根据采样计算,这里只是为了突出X的结构和batch-size=2,num_step=5)
X是[[‘我’、‘想’、‘要’、‘带’、‘你’],[‘浪’、‘漫’、‘的’、‘土’、‘耳’]]
Y是[[‘想’、‘要’、‘带’、‘你’、‘去’],[‘漫’、‘的’、‘土’、‘耳’、‘其’]]
在程序中,如果batch_size=32,num_step=35,那么每次输入到rnn()函数中的 X X X尺寸为32*35
-
对X进行one-hot编码
-
rnn运算
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
(outputs, state) = rnn(inputs, state, params)
得到了输出outputs和state
- 将outputs做结构处理后,计算交叉熵
- 反向传播计算梯度
- grad_clipping梯度剪裁
- d2l.sgd更新参数
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
if is_random_iter:
data_iter_fn = d2l.data_iter_random
else:
data_iter_fn = d2l.data_iter_consecutive
params = get_params()
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
for X, Y in data_iter:
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else: # 否则需要使用detach函数从计算图分离隐藏状态
for s in state:
s.detach_()
# inputs是num_steps个形状为(batch_size, vocab_size)的矩阵
inputs = to_onehot(X, vocab_size)
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
(outputs, state) = rnn(inputs, state, params)
# 拼接之后形状为(num_steps * batch_size, vocab_size)
outputs = torch.cat(outputs, dim=0)
# Y的形状是(batch_size, num_steps),转置后再变成形状为
# (num_steps * batch_size,)的向量,这样跟输出的行一一对应
y = torch.flatten(Y.T)
# 使用交叉熵损失计算平均分类误差
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn(prefix, pred_len, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx))
模型调用
随机采样
num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, True, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
相邻采样
采用相邻采样仅在每个训练周期开始的时候初始化隐藏状态是因为相邻的两个批量在原始数据上是连续的
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
关于采样的内容在【人工智能学习】【五】语言模型
定义预测函数
将rnn作为参数传入,以便使这个函数可以复用。里面的循环是指你要调用多少次,预测多少个字符。
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx):
state = init_rnn_state(1, num_hiddens, device)
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
# 将上一时间步的输出作为当前时间步的输入
X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size)
# 计算输出和更新隐藏状态
(Y, state) = rnn(X, state, params)
# 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y[0].argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
torch实现
定义模型
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
# 这个rnn_layer只是隐含层
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
# 定义输出层
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
# 这里的X是一个三维的矩阵
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
# 这个hidden是一个三维的
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
定义训练函数
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance (state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
训练方法调用
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
定义预测函数
实现一个预测函数,与前面的区别在于前向计算和初始化隐藏状态
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
RNN的反向传播
待补充















 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









