






先来讲讲为什么出这篇文章吧。今年八月份的时候,去参加了ZJU的保研夏令营,就被面试问到了这个问题,结果…一开始,还说成它们是加密算法,也不知道自己的脑子🧠是怎么了,哎~~ 好在最后想起来也说了两个都是编码形式,但也无济于事。其中,记得老师还问我,base64是不是编码后长度都是一样的,我想都没想就掉入陷阱了!!!
其实在此之前的学习当中,我已经碰到这俩家伙好多次了,但是一直装作看不见。

终究是吃了“没文化”的亏了,要是当时答出来了,可能还真有可能入选top3(自我安慰,其实其他回答的也是“依托”)。我的jio大,呜呜呜… 话不多说,大家找好板凳,下面让我们直接开课!

utf-8
utf-8,其中的utf的英文是unicode tranformation format。Unicode称为统一码,也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,想要了解它历史的同学可以去自行baidu。令人惊讶的是,unicode 字符集几乎能够将全世界的字符涵盖在其中(还在不断扩充ing),通过为每个字符分配一个唯一的数字代码点从而实行,就比如:
- ‘A’ 的 Unicode 代码点是 U+0041
- ‘中’ 的 Unicode 代码点是 U+4E2D
- 𒍣 (一个楔形文字) 的Unicode 代码点是U+121A3
- 𓀀 (一个埃及象形文字) 的Unicode 代码点是U+13000
- ☃ (雪人符号)的Unicode 代码点是U+26C4
挺奇怪的哈,但其实也非常震惊。世界已知的字符有这么多,全被unicode囊括进去了,而且目前不管是utf-8、utf-16还是utf-32这样的表现形式,最多也才4字节!!!就4字节,世界全部字符!!!话说到这,其实大家也比较好奇,这utf-8、utf-16、utf-32都是些什么玩意,其实它们属于unicode 的三种编码形式,它们的主要区别在于表示字符时所使用的比特数和具体的编码规则。为了清晰,我们就列个表吧:
| 编码形式 | 每个字符的字节数 | 特点 | 应用场景 |
|---|---|---|---|
| UTF-8 | 1-4 字节 | 可变长度编码,兼容 ASCII,节省空间 | 常用于网页和网络传输 |
| UTF-16 | 2 或 4 字节 | 以 2 字节为单位,可变长度编码 | 常用于 Windows、Java 内部字符串 |
| UTF-32 | 4 字节 | 固定长度编码,直接使用 Unicode 码点 | 常用于网页和网络传输常用于需要简单处理字符的场景,例如底层实现 |
仔细观察“utf”三个字母的英文原意,其中的‘u’就看作是unicode字符集,‘t’的英文意为tranformation转变,‘f’就是format格式的意思mo,三者连在一起其实可以认为是“将unicode字符集转换成另一种编码形式”,为什么要转换成另一种形式呢?因为我们要将它存放在计算机里面鸭!!计算机这个傻子只能读懂二进制,所以我们要将原来的“U+…”的格式转换成比特、字节的形式。
好好好,那么后面的“-8”、“-16”、“-32”有是什么东东呢?可以看作是三种编码的名字吧,只不过它们的名字恰好都反映了自己的特性。
- “-8”:这里的8表示的是8比特,也就是1字节。也就是说,用utf-8去编码我们的字符的话,最后的大小是1字节的整数倍,额…其实就只有1、2、3、4,最多4字节mo,前面也提到了,目前unicode字符即使容纳这么多字符,也最多只用了4字节。
- “-16”:结合前面说的“-8”,这里就表示,使用utf-16去编码我们的字符的话,最后的大小是2字节的整数倍,当然其实目前只有两种情况,要么2字节,要么4字节。倘若后面unicode字符集扩大了,又囊括了别的字符,可能这里就会出现6字节、8字节…
- “-32”:使用utf-32进行编码的话,最后的大小是固定的4字节,而且是直接使用unicode码点进行编码的。
好好好好好好好好好!!!!!

这里我着重讲一下utf-8,另外俩的话,用的不比这个广泛哈,哥们也不想讲了,大家自己去查查吧,快懒死了。
- utf-8编码规则
如果第一个字节的最高位是0,那么表示占一个字节
如果第一个字节(leading byte)的最高三位是110,那么表示这个字符占2个字节(前面1的个数),第二个字节的最高2位是10
如果第一个字节(leading byte)的最高三位是1110,那么表示这个字符占3个字节,第2和第3个字节的最高2位是10
这里看下面的结构可能更清晰:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
发现什么没有!!这里有三个结论哈:
- 当表示1字节的时候,最高位为0;
- 多字节的时候,数第一个字节前面的‘1’的个数,碰到‘0’就别数了,这里的‘0’就相当于是个截断的意思,有多少个1就表示这个字符用utf-8编码之后会有多少字节;
- 另外注意到,在多字节表示的时候,除了第一个字节(leading byte)以外,其他字节的前2位都是‘01’,也就是说,一旦发现有个字节的前2位是‘01’,它就必须连在前面的字节后面,从而才能正确地表示一个字符。
- utf-8这种编码有极限长度吗?
其实从上面的结构表以及我们发现的结论来看,大家也可以自己推理一下,按照这样的标准,utf-8这种编码方式并不是无限的,它的最大字节数应该是7字节,也就是第一个字节是‘11111110’后续的6个字节都是以’01’开始。好在,目前的unicode字符集最多也才用到了4字节,离我们的极限还有着非常大的距离,大家也不要担心会不会不够的问题。

base64
先来看看这个名字哈,“base64”,基于64,“64”究竟是个什么东东,为什么要基于“64”进行编码呢?不要着急,我来为你揭晓关于“64”的谜团!!!
众所周知一个字节可表示的范围是 0 ~ 255,而伟大的ascll码恰好是可以用1字节进行表示的。在标准的ascll码当中, 0 ~ 127表示的是可见字符,而为了不浪费这1位,在扩展的ascll码当中,范围 128~255表示的是不可见字符。
在 ASCII 码中 0 - 31和 127 是控制字符,共 33 个。其余 95 个,即 32 - 126 是可打印字符,包括数字、大小写字母、常用符号等。当不可见字符在网络上传输时,比如说从 A 计算机传到 B 计算机,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。
为了解决这个问题,我们可以先对数据进行编码,比如 base64 编码,变成可见字符,也就是 ASCII 码可表示的可见字符,从而确保数据可靠传输。Base64 的内容是有 0 ~ 9,a ~ z,A ~ Z,+,/ 组成,正好 64 个字符,这些字符是在 ASCII 可表示的范围内,属于 95 个可见字符的一部分。
看到这里,大家就知道“64”这个数字为何而来了吧。所以,base64这个编码方式就是基于 64 个可打印字符来表示二进制数据的。下面放张图给大家展示一下:
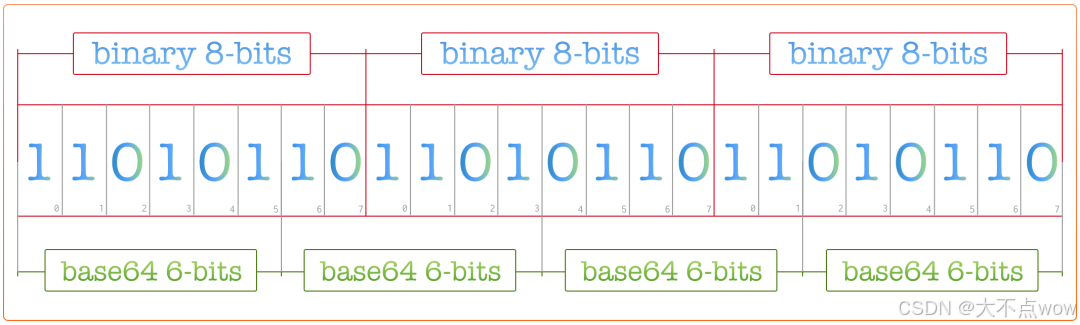
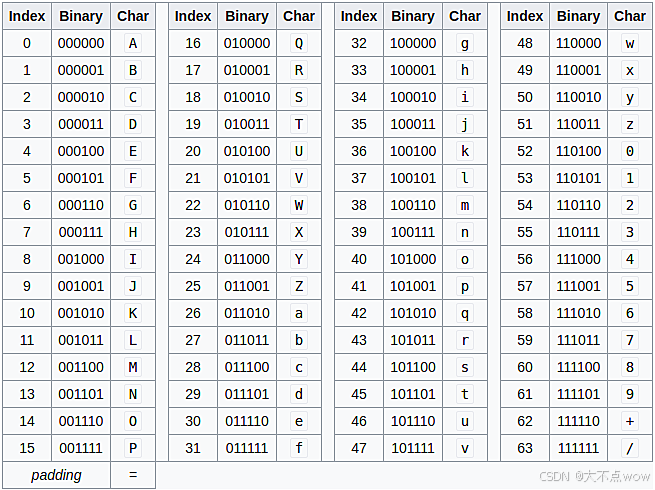
有关Base64 相应的索引表如下:
我们以编码 Man 字符串为例,来直观的感受一下编码过程。Man 由 M、a 和 n 3 个字符组成,它们对应的 ASCII 码为 77、97 和 110。
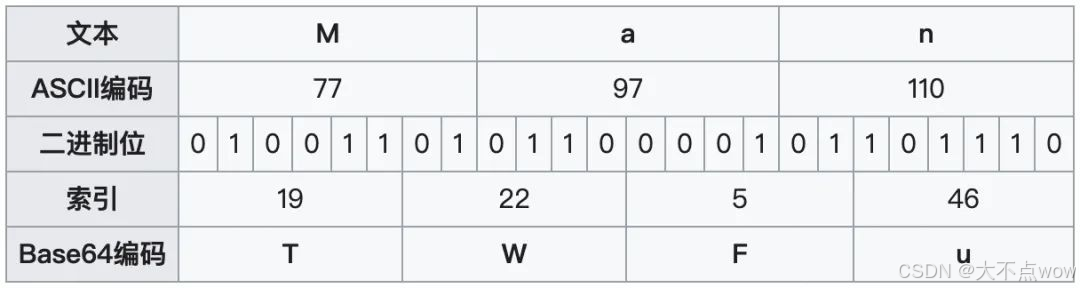
由图可知,Man (3字节)编码的结果为 TWFu(4字节),很明显经过 base64 编码后体积会增加 1/3。Man 这个字符串的长度刚好是 3,我们可以用 4 个 base64 单元来表示。但如果待编码的字符串长度不是 3 的整数倍时,应该如何处理呢?
如果要编码的字节数不能被 3 整除,最后会多出 1 个或 2 个字节,那么可以使用下面的方法进行处理:先使用 0 字节值在末尾补足,使其能够被 3 整除,然后再进行 base64 的编码。
以编码字符 A 为例,其所占的字节数为 1,不能被 3 整除,需要补 2 个字节,具体如下图所示:

接着我们来看另一个示例,假设需编码的字符串为 BC,其所占字节数为 2,不能被 3 整除,需要补 1 个字节,具体如下图所示:
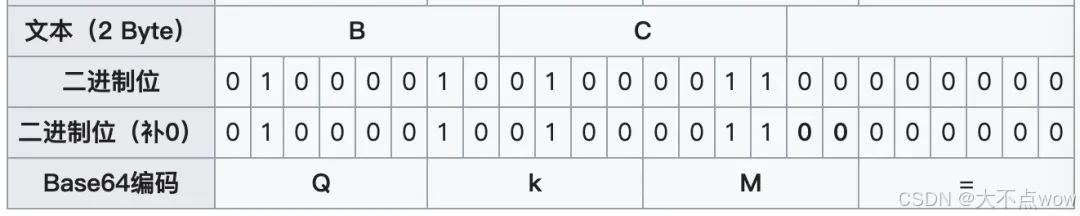
由上图可知,字符串 BC 经过 base64 编码后的结果是 QkM=,该结果后面的 1 个 = 代表补足的字节数。
正也是因为有如此的补充规则,我们通常可以发现base64编码之后会有1或者2个等于号 = 出现。这里有个注意点是:就是base64中的A 和 =,只有当6个0都是填补字节产生的时候,才是 = ,其他都是A。举个经典例子,单个ascll码为0的控制字符(NUL)进行base64编码的时候,它的结果是什么?答案是:AA== ,没想明白的同学仔细理解一下,再看看base64的索引表,或者按照我们的流程自己试一试哦😲 (两个NUL编码后为AAA= ;三个NUL编码后为AAAA)
那么,就讲到这里,解散!!!

其中有关base64编码的介绍,参考整合了文章https://blog.csdn.net/6346289/article/details/115743752

















 4600
4600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









