







There are some specific trends noticeable in the way we do UI-based test automation. Technology has advanced, new interfaces have been created, and as a result, to counter that, new tools have been created that changed our way of doing test automation.
Evolution
Let us go back in time a little to see how the test automation tools and frameworks have evolved.
- The crux of any automation framework is its core engine.
- The traditional record-and-playback set of tools sit on top of this core framework.
- The rigidity and difficulty (amongst other factors) in customizing the standard record and playback scripts resulted in the new layer being added – that of the Custom Frameworks.
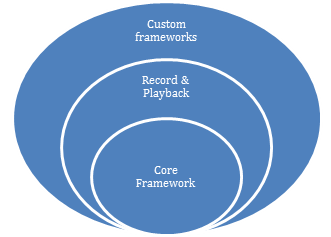
What are these
Custom Frameworks? These are nothing different than writing customized scripts to do more optimal record and playback. We know these frameworks by various different names, however, most commonly as depicted in the picture below.
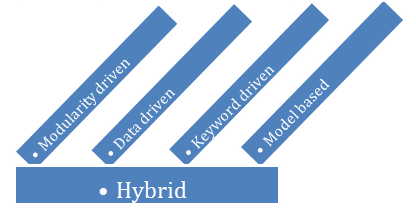
I am not going to get into the specifics of the above mentioned framework. But it is important to note that most often, when one starts to build a Custom Framework using either of the 4 mentioned types, eventually you end up with a Hybrid solution – which is a combination of the different frameworks.
The Custom Frameworks have been around for a considerable time now, and there are more than a bunch of tools and utilities to support this. However, there has been a need for writing tests in a new lingo. Something that will be easier for non-coders (example: Business Analysts) to read, understand, and maybe also contribute to.
Thus arose a new type of methodology and framework for building our Automated Tests - BDD – Behavior Driven Development. There are many tools in the market that allow BDD, namely, Cucumber, JBehave, RSpec, Twist, etc.
Interesting point to note is that the BDD layer sits on top of the Customized frameworks. So essentially we are building up layer upon layer. This is important, because we don’t want to reinvent the wheel. Instead, we want to keep reusing what we have (as much as possible), till we reach a point where new design and rewrite becomes necessary. But that is a separate discussion.
The BDD frameworks have also been around for some time now. When thinking about this pattern, the question that comes in my mind is – WHAT IS NEXT?

UI Advancements
To answer the question – “WHAT IS NEXT?” we need to understand the nature of UI advancements that have been happening in the past decade or two.
How many of us remember the CRT monitors we used to work on a few years ago? These monitors itself went through a big change over the past 2 decades. Then arrived the amazing, sleek, flat panel LCDs. The benefits of using the LCD monitors over CRT are well known.
What about the first generation of the big, clunky, power hungry, laptops? Compare that with the laptops available today, the change in the processing speed, the portability, battery life, and of course, in the context of this discussion, the high color and resolution available for us. Following this came the tablet PCs, which probably did not take off as well as one would have thought. However, this is a huge change in a pretty fast time isn’t it?
The latest in this portable computer generation is the Netbook PCs – ultra portable, pretty powerful, long battery life, still the same good UI capabilities.
Another category of devices has started changing the way we work.
For example, in the images shown below, the woman is browsing a wrist watch catalog with the help of a completely different interactive interface – which is controlled (browse, zoom, select, etc.) using her hand gestures.
 |
| Source |
Another example, the person in the right image shown below is editing the images directly using his hand, instead of any special device in his hand.
 |
| Source |
Another example, the child shown below is drawing an image with the help of a completely different interactive interface – which is controlled (browse, zoom, select, etc.) using her hand gestures.
 |
| Source |
Last example, the person in the image shown below is editing the images directly using his hand, instead of any special device in his hand.
 |
| Source |
You would ask how is this affecting the end user? How is this related to Test Automation?
Well, the answer is simple. These changes in UI interfaces have resulted in a boom in the software industry. Enabling or writing new software for mobile phones, or portable devices has become a new vertical in software development and testing.
Look at the smart phones (iPhones, Androids, etc.). There are so many more things possible on portable devices today, that the possibilities of what you can do are limitless. You can interact with them using regular buttons, or touch-based gestures, or stylus.
See how the Internet has evolved. On all the major portals, you are now able to create your own customized page, based on your preference. And all this is done not by major configuration changes, or talking to a sys-admin. They are done simply by doing some mouse gestures and actions. Example: In the below image, the Yahoo page has widgets which you can configure and arrange in the order of your preference, so that you are able to see what you want to see.
WHAT IS NEXT?
The whole world appears to be moving towards providing content or doing actions based on “interactions”.
If you recall the movie, “The Minority Report”, the technology depicted there is simply amazing. The movie, portrayed in the year 1950, shows the actors interacting with images, videos, voices, all using gestures. This technology was developed by MIT labs for the movie, and with the work that has happened in the past few years, this technology was demonstrated in
TED talks by John Underkoffler. He in fact believes this technology would become mainstream in the next couple of years for everyone’s use. He called this technology the “Spatial operating environment”.
In simpler terms, I call this “ Gesture Based Technology”. This is the future that we are already very close to!
How does this affect the software test automation?
Well, this affects us in a major way.
- We eventually will be developing software to support this technology.
- If we are developing software, that means we need to test it.
- This also means that we need to do automation for it.
It is imperative for us to start thinking about how will we, as testers, test in this new environment?
What tool support do we need to test this effectively?
Lastly, let’s think BIG - why can’t we create / write our automation tests using similar interfaces?
UDD – UI Driven Development
If a user of a system can interact with it using gestures, why can’t we testers change the way we write automated tests? Why do we have to rely on coding, or writing tests in BDD format? If a picture speaks a thousand words, why can we raise the bar and write tests using a different, interactive format?

I envision the UDD framework to have the following components:

Some of these components are self-explanatory. However, there are some key components here which I would like to talk about.
Plugin Manager
This complete framework would be built on plugins. There would be a set of core plugins that make this environment, and various other plugins developed and contributed by the community based on their need, requirement and vision.
Another important aspect of this environment is that if a new plugin needs to be added, we would not need to restart the complete framework. A ‘hot-deployment’ mechanism would be available to enable additions of the new plugins in the environment.

Sample plugins include:
- xPath utilities
- Recording engine – generate code in the language specified
- Custom reporters / trend analysis
- Test data generators
- Schedulers / integration with CI (Continuous Integration) systems
- Language / driver support – I believe it should be easy to change the underlying framework at the click of a button (provided the necessary plugins are available). This way the admin user can choose to change from say using Selenium to Sahi just by choosing which UI framework is to be used. Similarly, it should be possible to select which language is used for the code generation.
- Integration with external tools and repositories – example: file diff / compare tools, etc.
Discovery
This to me is a very essential and critical piece because we want to make sure we do not need to reinvent the wheel. We would like to reuse our existing frameworks as much as possible and make the transition to UDD as seamless as possible.
This component should be able to reverse engineer the existing code base, and create an UI object hierarchy available in a palette / repository.
Example: After running the discovery tool against the existing source repository, the UI objects will be created like this:

Author
To create new objects / tests scripts, the test author would use the UI objects from the palette / repository, and, ‘simply’ drag-&-drop various UI objects to create new objects / test scripts. All the ‘intelligent’ code refactoring and restructuring will happen automatically in the backend. Refer to the picture below for reference.
Note: We can do this to a certain extent at present. Using reverse engineering tools, we can create class diagrams / UML diagrams from existing code base.
In the context of UDD, these are at present dummy objects. We need to make this proper UI driven objects, which when moved across, would result in the framework making appropriate modifications in the underlying code-base, without the user having to manually intervene.

This provides a higher level and also a pictorial view for the people looking at these tests.
That said, when new functionality needs to be added in the code base, then the test author can simply write code for the same, and the UDD framework will create appropriate UI objects out of it, and also publish it to the repository for everyone’s use.
Execution Engine
The execution engine provides a lot of flexibility in terms of how the tests should be run. There are various options:
- Run the tests within UDD framework
- Create a command for the set of tests the user wants to run, which the user can simply copy and paste in the command prompt and execute the tests directly without having to worry / think about what command needs to be run.
- Provide ability to execute the tests on the same machine, remote machines or combinations so desired.
- Can be triggered via CI tools.
Reporting Engine
We are used to seeing the default, yet quite comprehensive reports generated by the various unit testing frameworks (jUnit, nUnit, TestNG, etc.).
However, what is lacking in this is the ability to consolidate reports from various different runs and archive them, create trend analysis and charts of various types which may be interesting to track the health of the system.
However, what is lacking in this is the ability to consolidate reports from various different runs and archive them, create trend analysis and charts of various types which may be interesting to track the health of the system.
There should be a default set of Reporting plugins which provide this type of mechanism out of the box. Also, since this is plugin based architecture, the community can contribute to writing customized reporters to cater to specific requirements.
How do we get there?
I have shared what my vision is for the Future of Test Automation. The next important question is what can we do to help us get ready for the future, whatever it may be?
If we can follow a few practices when we do test automation, we can be in a good state to adopt what the future would have to offer.
|
Test code should be of Production quality!
|
Use private / protected member variables / methods. Make them public only when absolutely essential.
|
|
Import only those classes that you need. Avoid import abc.*
|
Keep test intent separate from implementation.
|
|
Use xPaths with caution. Do NOT use indexes.
|
Do not simply copy / paste code from other sources without understanding it completely.
|
|
Keep test data separate from test scripts.
|
Duplicating code is NOT OK.
|
Posted
25th August 2010 by
Anand Bagmar















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}