







 本文探讨了如何利用NeuralCoref解决多轮对话中的指代消解问题,通过建立问答系统字典映射,并结合共指消解技术,实现代词的正确解析,从而提升聊天机器人的对话能力。示例代码显示了NeuralCoref在处理代词时的效果,并指出需要处理物主代词的语法恢复和从上下文中提取问题的挑战。
本文探讨了如何利用NeuralCoref解决多轮对话中的指代消解问题,通过建立问答系统字典映射,并结合共指消解技术,实现代词的正确解析,从而提升聊天机器人的对话能力。示例代码显示了NeuralCoref在处理代词时的效果,并指出需要处理物主代词的语法恢复和从上下文中提取问题的挑战。
多轮对话对于目前的聊天机器人来说依然是一个难题,比如下面这个:
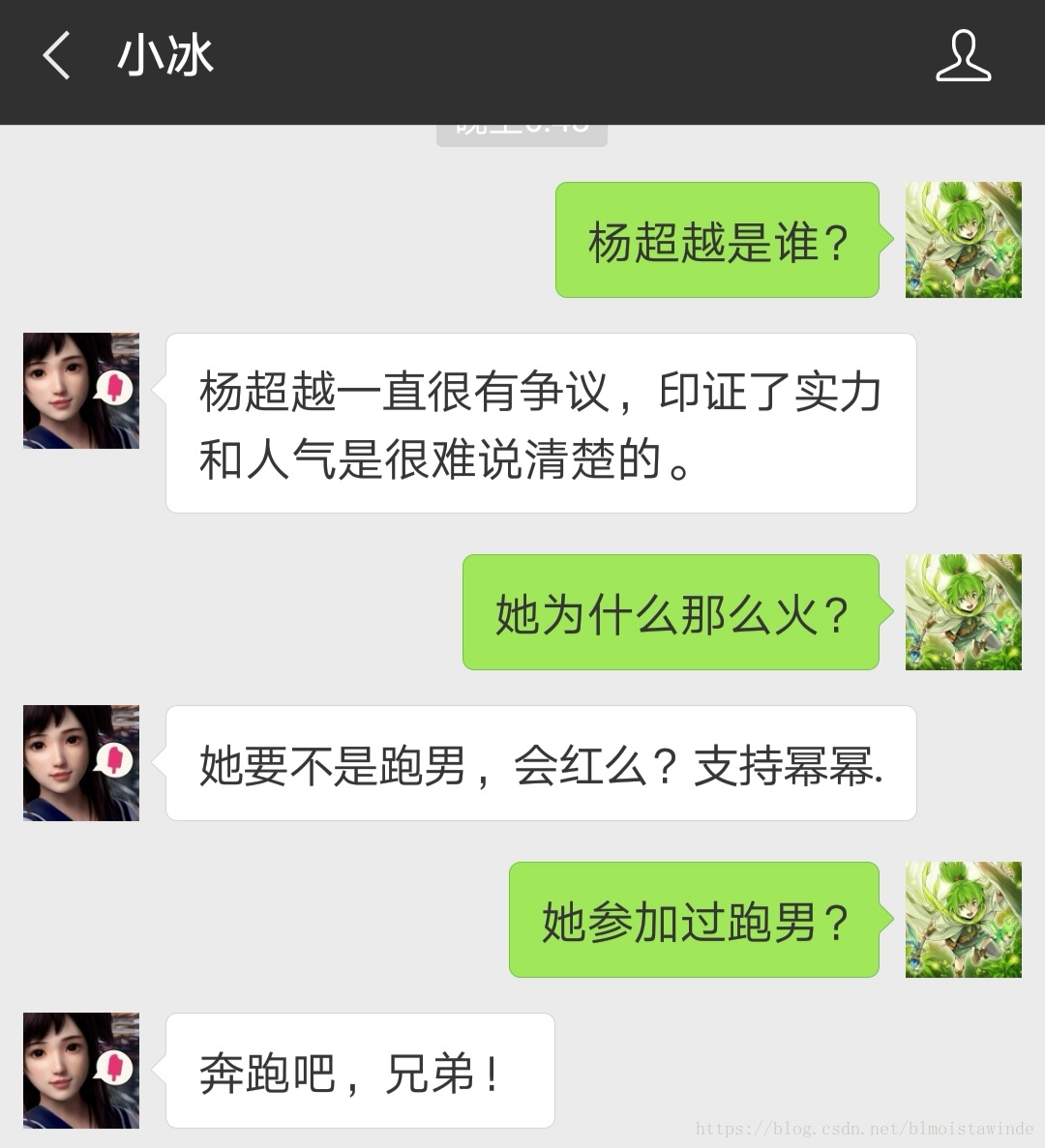
显然当我问小冰第二个问题的时候,小冰并不知道我说的“她”指的是杨超越。从回答来看,小冰甚至把“她”当作了Angela Baby? 第三个问题就更不说了。
这里没有半点贬低小冰的意思,我也相信未来的某位读者看到这里时,小冰已经不会犯这样的错误了。不过就写作时来说,小冰应该只纯粹利用了我当前的问句进行回答,导致多轮对话几乎不能正常进行。
指代消解是有希望帮助解决这个问题的一个技术,下面就利用我们刚刚学过的NeuralCoref【NeuralCoref: python的共指消解工具,向代词指代的问题进军!】来写一个“能多轮对话的问答对话机器人”demo吧。
上代码
import warnings
warnings.filterwarnings("ignore")
import spacy
nlp = spacy.load('en_coref_sm')
为了简洁地展现共指消解的应用,这里将把问答系统部分的难度降到最低,直接有了问题-答案的字典映射。
QA = {
"Who is Abraham Lincoln?":"An American statesman and lawyer who served as the 16th President of the United States.",
"When was Abraham Lincoln born?":"February 12, 1809.",
"Where is Abraham Lincoln's hometown?":"Hodgenville, Kentucky"}
这些问题没有办法应付代词,然而人在有上下文的对话中使用代词是再自然不过的事了。用共指消解就可以解决这个问题。我们会把每一次的问答记录都记录在上下文中,这样我们就可以用共指消解把之前提到的对象再搬到后面的代词里来,使得有代词的问题也可以与原始模板匹配。
让我们先实验一下这个想法是否可行。
para =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









