









**
2024年青少年粤港澳大湾区比赛A轮模拟测试 python小学组
**
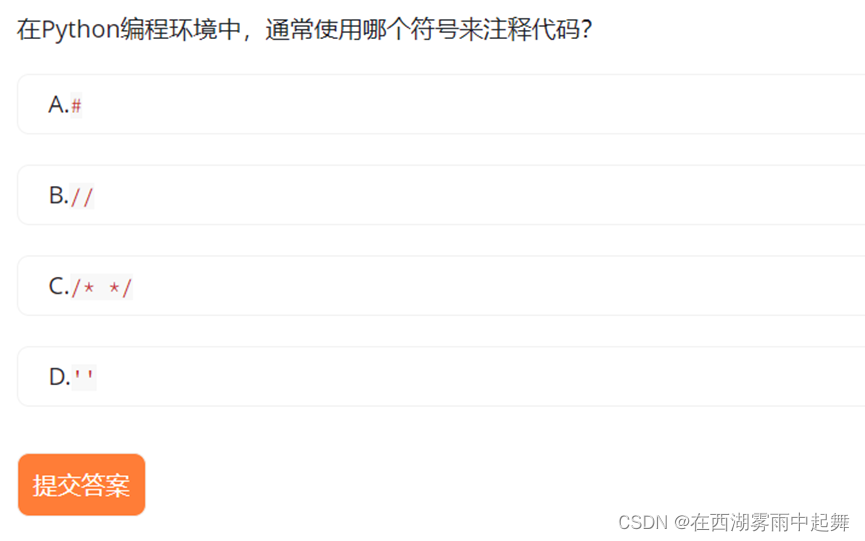
第一题答案 : A
第二题答案:B
认识python当中的函数
在 Python 编程中,函数是一种将特定代码段封装起来,使其可以被反复调用的结构。函数可以接收输入参数,进行一些计算或操作,并返回结果。使用函数可以使代码更模块化、可读性更高、并且易于维护和重用。
函数的定义
在 Python 中,函数使用 def 关键字来定义。基本语法如下:
def 函数名(参数列表):
函数体
return 返回值
def关键字用于定义函数。函数名是函数的名称,用于标识函数。参数列表是可选的,表示函数可以接受的输入参数,用逗号分隔多个参数。函数体是函数执行的代码块,包含具体的操作或计算。return语句用于返回函数的结果,如果没有return语句,函数将返回None。
举例说明
以下是一个简单的函数示例:
def add(a, b):
return a + b
这个函数名为 add,它接收两个参数 a 和 b,并返回它们的和。调用这个函数时,可以传递不同的参数值:
result = add(3, 5)
print(result) # 输出 8
使用函数的好处
- 代码重用:函数可以多次调用,无需重复编写相同的代码。
- 模块化:将代码划分为独立的函数,可以使程序结构更清晰、逻辑更明确。
- 可读性:使用函数可以减少代码的复杂度,提高可读性,使代码更易于理解。
- 易于维护:函数封装了特定的功能或逻辑,修改或调试时可以集中在某个函数内,不会影响其他部分。
示例
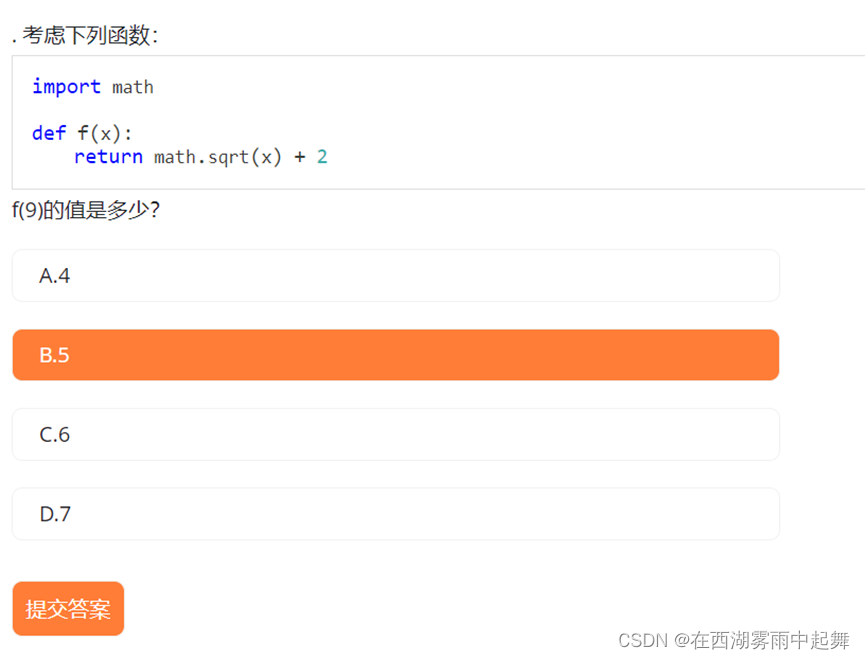
让我们回到前面的例子,解释其中的函数 f(x) 是如何工作的:
import math
def f(x):
return math.sqrt(x) + 2
result = f(9)
print(result) # 输出 5
- 这里定义了一个函数
f,接收一个参数x。 - 在函数体内,调用
math.sqrt(x)计算x的平方根,并加上 2。 - 最后,通过
return返回计算结果。
调用 f(9) 时,x 的值为 9,函数计算 math.sqrt(9) 即 3,再加上 2,得到 5,并返回结果。因此,print(result) 输出 5。
接下来介绍这个题目
首先,我们来看函数的定义:
import math
def f(x):
return math.sqrt(x) + 2
这个函数 f(x) 的定义是取输入参数 x 的平方根,再加上 2。我们需要计算 f(9) 的值。
根据函数定义,计算步骤如下:
- 计算
math.sqrt(9),即 9 的平方根。 - 将平方根的结果加上 2。
让我们一步步计算:
- 9 的平方根是 3。
- 将 3 加上 2,得到 5。
因此,f(9) 的值是 5。
正确答案是 B. 5。

当然,以下是对各个选项的详细解释:
A. .txt
.txt 文件扩展名表示纯文本文件。文本文件通常用于存储没有任何格式的纯文本信息。虽然 Python 脚本的代码可以保存在 .txt 文件中,但这种文件不会被 Python 解释器识别为可执行的 Python 脚本。因此,这不是标准的 Python 脚本文件扩展名。
B. .py
.py 文件扩展名是用于 Python 脚本文件的标准扩展名。这种文件包含了 Python 代码,可以被 Python 解释器执行。编写的 Python 脚本通常保存在扩展名为 .py 的文件中。例如,一个名为 script.py 的文件可以包含并运行 Python 代码。
C. .python
.python 不是标准的文件扩展名。虽然它表明文件可能与 Python 有关,但 Python 解释器不会自动识别这种扩展名为可执行的 Python 脚本文件。因此,这不是用于 Python 脚本的正确扩展名。
D. .script
.script 也不是用于 Python 脚本的标准文件扩展名。尽管它可能暗示该文件包含脚本代码,但它不被 Python 解释器默认识别为 Python 脚本文件。因此,这也不是用于 Python 脚本的正确扩展名。
结论
在通常情况下,表示一个 Python 脚本文件的扩展名是 .py。
因此,正确答案是:
B. Py
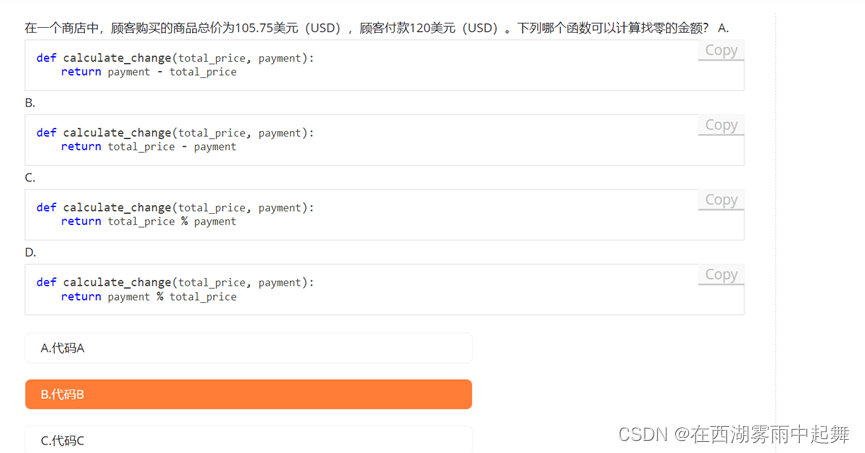
好的,让我们重新审视所有选项,并确定哪个选项正确地计算了找零的金额。
选项 A
def calculate_change(total_price, payment):
return payment - total_price
这个选项正确地用 payment 减去 total_price,并返回结果,这是计算找零金额的正确方式。
选项 B
def calculate_change(total_price, payment):
return total_price - payment
这个选项用 total_price 减去 payment,这会给出一个负数,并不符合计算找零金额的需求。
选项 C
def calculato change(total_price, payment):
return total_price % payment
这个选项中函数名拼写错误(calculato change 而不是 calculate_change),并且使用了取模运算符 %,这会返回 total_price 除以 payment 的余数,不是我们需要的操作。
选项 D
def calculato change(total_price, payment):
return payment s total price
这个选项中函数名拼写错误(calculato change 而不是 calculate_change),并且 payment s total price 有语法错误。
结论
正确计算找零金额的代码是选项 A:
def calculate_change(total_price, payment):
return payment - total_price
因此,正确答案是:
A. 代码A
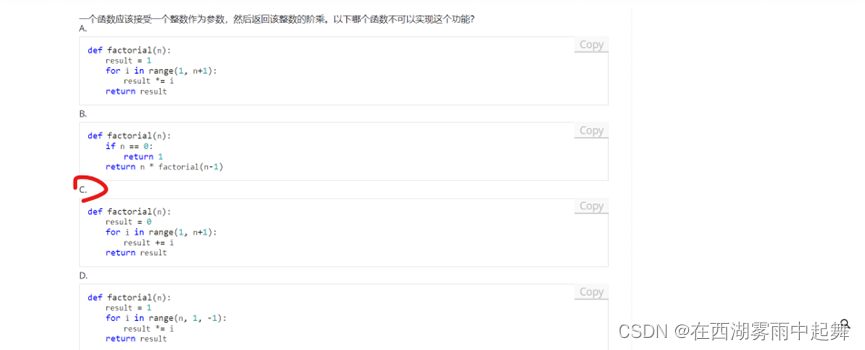
我们需要检查每个选项的代码,看看它们是否能够正确计算给定整数的阶乘。阶乘的定义是对于一个正整数 ( n ),阶乘 ( n! ) 是从 1 到 ( n ) 的所有正整数的乘积。
选项 A
def factorial(n):
result = 1
for i in range(1, n+1):
result *= i
return result
这个选项定义了一个函数 factorial,初始化 result 为 1,然后在从 1 到 n(包括 n)的范围内循环,将 result 依次乘以每个 i。这个实现是正确的。
选项 B
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
这个选项定义了一个递归函数 factorial。如果 n 等于 0,返回 1(因为 0! = 1);否则,返回 n 乘以 factorial(n-1)。这个实现也是正确的。
选项 C
def factorial(n):
result = 1
for i in range(n):
result *= i
return result
这个选项定义了一个函数 factorial,初始化 result 为 1,然后在从 0 到 n-1 的范围内循环,将 result 依次乘以每个 i。这段代码有一个错误,因为它从 0 开始循环,因此 result 将被乘以 0,结果总是 0。这个实现是错误的。
让我们重新解释选项 D 并考虑其正确性。
选项 D
def factorial(n):
result = 1
for i in range(n, 1, -1):
result *= i
return result
这个选项定义了一个函数 factorial,初始化 result 为 1,然后在从 n 到 2 的范围内(包括 n 和 2)循环,将 result 依次乘以每个 i。这实际上是一个正确的实现,因为它正确地计算了从 n 到 1 的乘积。
让我们再次审视所有选项,看看哪个不能正确计算阶乘。
选项 C
def factorial(n):
result = 1
for i in range(n):
result *= i
return result
这个选项有一个问题:循环从 0 开始,这会导致结果始终为 0,因为 result 会被乘以 0。
结论
不可以正确计算阶乘的代码是选项 C。
因此,正确答案是:
C. 代码C
列表解析(List Comprehension)是一种简洁的方式来创建列表。它的基本语法是:
[表达式 for 元素 in 可迭代对象]
我们来逐一分析每个选项,看看哪些是正确的列表解析表达式。
选项 A
[x for x in range(5)]
这是一个典型的列表解析表达式,它会生成一个列表 [0, 1, 2, 3, 4]。这是正确的列表解析表达式。
选项 B
[for x in range(5): x]
这个表达式试图在列表解析中使用类似于循环体的语法,这是不正确的。列表解析中不能使用冒号和循环体。这个表达式是错误的。
选项 C
(x for x in range(5))
这是一个生成器表达式(Generator Expression),不是列表解析。生成器表达式返回的是一个生成器对象,而不是列表。虽然它语法上是正确的,但它不是一个列表解析表达式。
选项 D
{x for x in range(5)}
这是一个集合解析(Set Comprehension),它会生成一个集合 {0, 1, 2, 3, 4}。虽然它语法上是正确的,但它不是一个列表解析表达式。
结论
只有选项 A 是正确的列表解析表达式。
因此,正确答案是:
A. [x for x in range(5)]
在一个包含 ( n ) 个元素的数组中寻找最大元素的算法通常使用枚举法(也称为线性搜索)。我们需要遍历数组中的每一个元素,以找到其中的最大值。
分析复杂度
- 最坏情况:我们必须检查数组中的每一个元素,以确保找到最大元素。因此,算法的时间复杂度是 ( O(n) ),其中 ( n ) 是数组的长度。
选项分析
A. O(1):常数时间复杂度。这表示操作的执行时间不依赖于输入大小。这不适用于我们的情况,因为我们必须检查每一个元素。
B. O(n):线性时间复杂度。这表示操作的执行时间随着输入大小线性增长。对于一个 ( n ) 元素的数组,查找最大值需要遍历所有元素,因此这个复杂度是正确的。
C. O(log n):对数时间复杂度。这表示操作的执行时间随着输入大小的对数增长。常见于二分查找等算法,但不适用于线性搜索。
D. O(n^2):二次时间复杂度。这表示操作的执行时间随着输入大小的平方增长,常见于一些简单的排序算法如冒泡排序。不适用于线性搜索。
结论
对于使用枚举法寻找数组中最大元素的算法,其时间复杂度是 ( O(n) )。
因此,正确答案是:
B. O(n)
字典(Dictionary)是 Python 中一种非常重要的数据结构,它提供了一种灵活的方式来存储和组织数据。字典以键-值对(key-value pairs)的形式存储数据,可以根据键来快速查找和访问对应的值。在 Python 中,字典使用花括号 {} 来创建,每个键值对之间用逗号 , 分隔。
字典的特点:
- 无序性:字典中的键值对是无序的,即它们的存储顺序不是固定的。
- 可变性:字典中的元素可以被增加、删除或修改。
- 唯一性:字典中的键是唯一的,每个键只能对应一个值。
- 灵活性:字典可以存储任意类型的数据,包括数字、字符串、列表、元组、甚至是其他字典。
创建字典:
# 创建一个空字典
my_dict = {}
# 创建一个包含键值对的字典
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# 使用 dict() 函数创建字典
my_dict = dict(name='John', age=30, city='New York')
访问字典中的值:
# 使用键来访问对应的值
print(my_dict['name']) # 输出 'John'
# 使用 get() 方法访问值,避免键不存在时引发 KeyError 错误
print(my_dict.get('age')) # 输出 30
添加或修改键值对:
# 添加新的键值对
my_dict['email'] = 'john@example.com'
# 修改已有键的值
my_dict['age'] = 31
删除键值对:
# 使用 del 关键字删除指定键值对
del my_dict['city']
# 使用 pop() 方法删除指定键值对,并返回删除的值
age = my_dict.pop('age')
遍历字典:
# 遍历键值对
for key, value in my_dict.items():
print(key, value)
# 遍历键
for key in my_dict.keys():
print(key)
# 遍历值
for value in my_dict.values():
print(value)
字典的应用场景:
- 存储和表示结构化数据,如用户信息、商品信息等。
- 缓存数据,以提高程序的性能。
- 记录某些数据的出现次数,用于统计和分析。
总的来说,字典是 Python 中非常有用的数据结构,它在许多场景下都能发挥重要作用。
题目解释
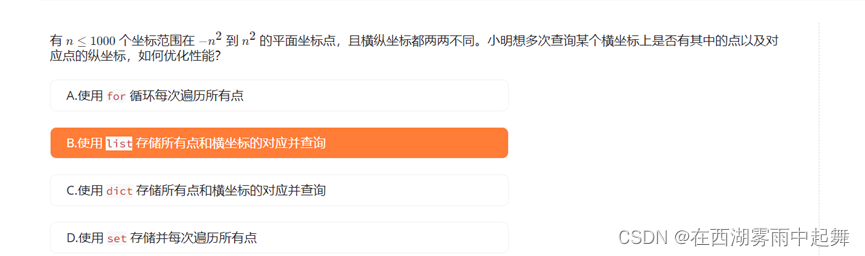
对于这个问题,我们希望在给定一组平面坐标点和多次查询的情况下,优化性能以加快查询速度。让我们逐一分析每个选项,看看哪个是最佳的选择。
选项 A:使用 for 循环每次遍历所有点
这个方法会导致每次查询都需要遍历整个点集,时间复杂度是 (O(n)),其中 (n) 是点的数量。对于大量的查询,这种方法效率低下,不是一个好的选择。
选项 B:使用列表存储所有横纵坐标的对,并查询
这种方法在查询时需要遍历整个列表,时间复杂度也是 (O(n))。虽然它可以存储所有的点信息,但在查询时效率不高,因此不是最佳选择。
选项 C:使用字典存储所有点和横坐标的对,并查询
字典(Python 中的 dict)是一种键值对的数据结构,可以提供 (O(1)) 的平均时间复杂度的查询。我们可以使用字典来存储横坐标与对应的点信息,这样在查询时可以快速找到对应的纵坐标。这是一个高效的选择,因为平均查询时间复杂度是 (O(1))。
选项 D:使用集合存储所有点,并每次遍历所有点
使用集合存储所有点不会提供任何优势,因为查询时仍然需要遍历整个集合来查找对应的纵坐标。时间复杂度是 (O(n)),不是最佳选择。
结论
选项 C 使用字典存储所有点和横坐标的对,并使用字典的快速查询特性,是最佳的选择。它提供了 (O(1)) 的平均查询时间复杂度,适用于大量的查询操作。
因此,正确答案是:
C. 使用 dict 存储所有点和横坐标的对,并查询

冒泡排序算法是一种简单的排序算法,它通过比较相邻的元素并交换它们来将较大的元素逐渐“浮”到数组的顶部。在每次遍历数组时,会将当前最大的元素沉到最后的位置。这个过程会持续 (n-1) 轮,其中 (n) 是列表的长度。因为每一轮都会将一个最大的元素放到正确的位置上,所以在最坏的情况下,我们需要进行 (n-1) 次交换。
现在让我们来看看给定的列表 [3, 5, 3, 2, 8, 5]。我们将使用冒泡排序算法对它进行排序,同时记录每次交换的次数。
第一轮:
- 交换
3和5:[3, 3, 5, 2, 8, 5] - 交换
5和2:[3, 3, 2, 5, 8, 5] - 交换
5和8:[3, 3, 2, 5, 5, 8]
第二轮:
- 交换
3和3:[3, 2, 3, 5, 5, 8] - 交换
3和2:[2, 3, 3, 5, 5, 8]
第三轮:
- 交换
2和3:[2, 3, 3, 5, 5, 8]
在这个例子中,我们进行了 5 次交换。所以,最小的交换次数是 5。
因此,正确答案是:
C. 5
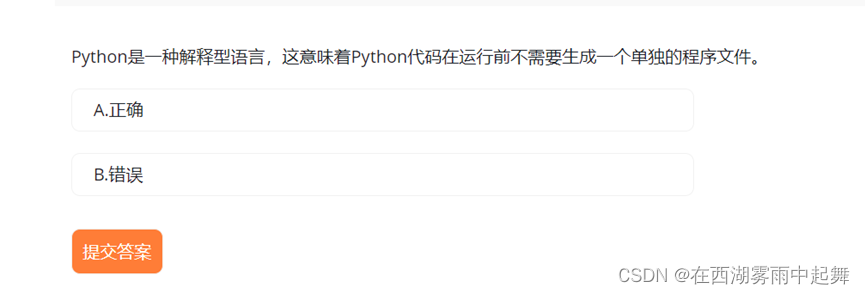
正确。 Python 是一种解释型语言,这意味着 Python 代码在运行前不需要生成一个单独的程序文件。相反,Python 解释器会逐行解释和执行代码。因此,选项 A 正确。
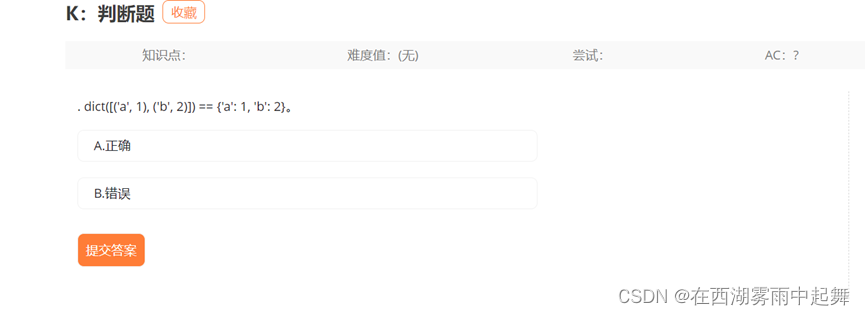
这个字典表达式中有一个错误,正确的形式应该是 {'a': 1, 'b': 2}。
所以,选项 B 是正确的。
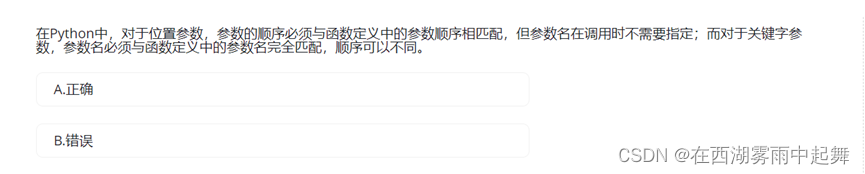
这句话描述了 Python 函数的两种参数传递方式:位置参数和关键字参数。
-
位置参数:当函数定义中没有指定参数名,调用函数时需要按照函数定义的顺序依次传递参数。在调用时,参数的顺序和数量必须与函数定义中的参数顺序和数量相匹配。
-
关键字参数:当函数定义中指定了参数名,调用函数时可以按照任意顺序传递参数,只需指定参数名即可。这种方式使得函数调用更加灵活,参数的顺序可以自由调整。
所以,描述中的内容是正确的。
因此,选项 A 正确。

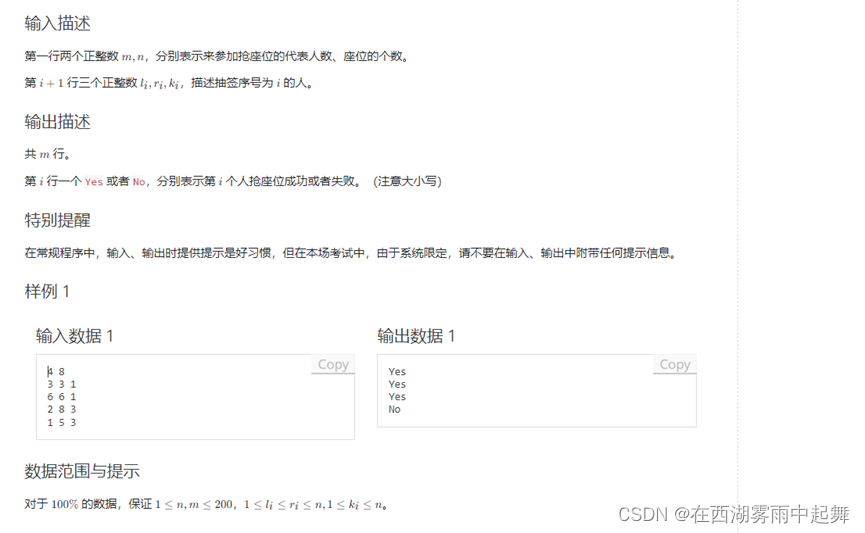
题目解释:
题目描述:
小P的班级要重新排座位了,于是他的朋友推举他为代表参加抢座位大会。座位一共有r个,编号从1到r。有m个人作为代表参加抢座位大会,抽签决定了选座位的顺序。每个人选座位时,都希望座位尽量靠前,并且在编号4到r之间,如果在这个范围内剩余的座位不是他要的个数,则抢座位失败。
输入描述:
第一行两个正整数m和r,表示参加抢座位的代表人数和座位的个数。接下来m行,每行描述抽签序号为i的人,其中第一个整数表示抽签序号i,第二个整数表示这个人要抢的座位个数,接下来的整数表示这个人想要的座位编号。
输出描述:
m行,每行一个Yes或者No,表示第i个人抢座位成功或者失败。
示例:
输入:
4 8
1 2 2 3
2 2 3 4
3 2 4 5
4 1 6
输出:
Yes
Yes
No
No
解释:
- 第一个人要抢2个座位,成功抢到座位2和3。
- 第二个人要抢2个座位,成功抢到座位4和5。
- 第三个人要抢2个座位,但剩余的座位只有6一个,所以失败。
- 第四个人要抢1个座位,但剩余的座位已经没有了,所以失败。
解题过程
好的,下面是不使用函数的Python实现该题的代码:
# 输入处理
m, r = map(int, input().split())
seats = [0] * (r + 1) # 初始化座位情况,0表示座位为空,1表示已经被占用
result = []
# 逐个处理每个代表参加抢座位大会的情况
for _ in range(m):
representative = list(map(int, input().split()))
idx, num_seats, *desired_seats = representative
allocated_seats = []
# 逐个尝试选座位,直到需要的座位数满足或者无法满足要求
for seat in desired_seats:
# 判断是否座位编号在4到r之间,且座位未被占用
if 4 <= seat <= r and seats[seat] == 0:
allocated_seats.append(seat)
seats[seat] = 1 # 标记座位已被占用
num_seats -= 1 # 每成功选一个座位,需要的座位数减1
if num_seats == 0: # 如果需要的座位数已经满足,则跳出循环
break
# 判断最终是否成功抢到足够的座位
if num_seats == 0:
result.append("Yes")
else:
result.append("No")
# 输出结果
for res in result:
print(res)
这段代码实现了同样的逻辑,但是没有将功能封装为函数,而是直接在主程序中编写了逻辑处理。
每一步的过程解释点
当我们编写一个程序时,通常需要按照一定的步骤来完成任务。下面我将详细解析上面的代码,以便你更好地理解每一步:
-
输入处理:
m, r = map(int, input().split())这行代码通过
input()函数获取用户输入的两个整数,使用split()方法将输入的字符串分割成一个字符串列表,然后使用map()函数将字符串列表中的每个元素转换为整数,并将结果分配给变量m和r,分别表示参加抢座位的代表人数和座位的总数。 -
初始化座位状态列表:
seats = [0] * (r + 1)这行代码创建了一个长度为
r+1的列表,列表中的每个元素初始值都是0,表示座位未被占用。 -
初始化结果列表:
result = []这行代码创建了一个空的列表,用于存储每个代表是否成功抢到座位的结果。
-
循环处理每个代表的情况:
for _ in range(m): representative = list(map(int, input().split())) idx, num_seats, *desired_seats = representative这段代码通过
for循环,对每个代表进行处理。在循环内部,首先通过input()获取一行输入,并使用split()将其分割成字符串列表,然后使用map()将列表中的每个字符串转换为整数,最后使用list()将结果转换为列表并赋值给representative。idx表示抽签序号,num_seats表示该代表要抢的座位数量,desired_seats表示该代表希望抢到的座位编号列表。 -
尝试选座位:
for seat in desired_seats: if 4 <= seat <= r and seats[seat] == 0: allocated_seats.append(seat) seats[seat] = 1 num_seats -= 1 if num_seats == 0: break这段代码在内部循环中遍历该代表希望抢到的座位编号列表
desired_seats。对于每个座位,首先检查其编号是否在4到r之间并且该座位未被占用。如果满足条件,则将该座位加入到已分配座位列表allocated_seats中,并将该座位标记为已占用。如果成功选到一个座位,则将num_seats减1。如果已经成功选到足够数量的座位,则跳出内部循环。 -
判断是否成功抢到座位:
if num_seats == 0: result.append("Yes") else: result.append("No")这段代码在每个代表的处理结束后判断是否成功抢到足够数量的座位。如果成功抢到,则将 “Yes” 添加到结果列表
result中,否则将 “No” 添加到结果列表中。 -
输出结果:
for res in result: print(res)这段代码循环遍历结果列表
result,并逐行输出每个代表是否成功抢到座位的结果。
通过这样的步骤,我们完成了对每个代表参加抢座位大会的情况进行处理,并输出了最终的结果。















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









