






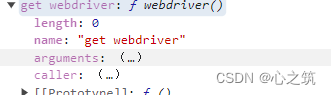
好多网站检测自动化的时候必不可少的要检测webdriver,正常的浏览器中返回的值是这样的

这个属性是定义在原型上的Navigator.prototype.webdriver,其中webdriver是通过get方法获取到的
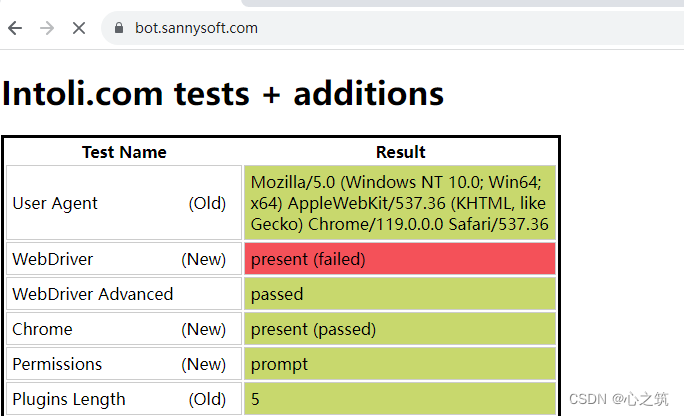
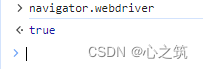
如果通过selenium访问网站之后,会是这样的
查阅了大佬们的帖子后,发现一个有用的库selenium-stealth,这个可以隐藏webdriver特征,于是乎说干就干
from selenium import webdriver
from selenium_stealth import stealth
import time
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
# options.add_argument("--headless")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, executable_path=r"chromedriver.exe")
stealth(driver,
languages=["zh-CN", "zh"],
vendor="Google Inc.",
platform="Win32",
fix_hairline=True,
)
url = "https://bot.sannysoft.com/"
# url = "https://nowsecure.nl/"
driver.get(url)
time.sleep(100)
driver.quit()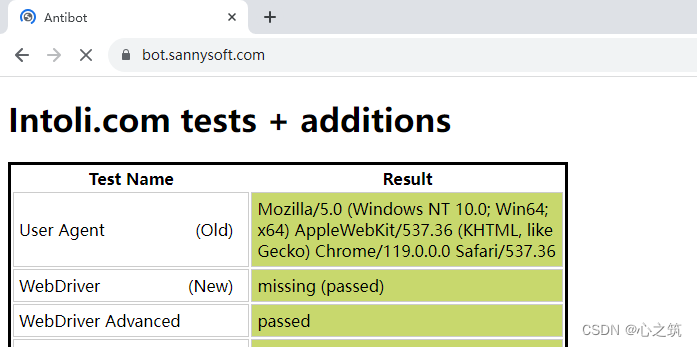
呦呵,貌似结果还不错,不过我们在深入的看一下他这个库的源代码

原来是这样搞的,这就不禁的倒吸一口冷气,这不是妥妥的被检测么

暴力美学就这么玩么,就这样删了,一了百了?还是要梳理一下,这个是通过get方法实现的,必须还是要从get方法上下手,在原型上重新定义get方法,比如这样。
function get_webdriver() {
return false;
}
Object.defineProperty(Navigator.prototype, 'webdriver', {
get: get_webdriver
})不过这样还是会被检测到,比如
![]()
再比如

这里就留一个作业吧,大佬们肯定都会,我就不班门弄斧了,成品是这样的
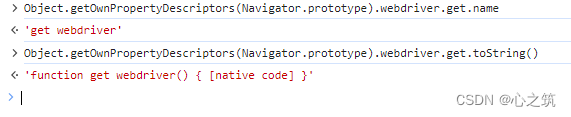
还有一个

总结一下
1.tostring要保护好
2.get方法不能丢
3.方法名称要搞对
否则妥妥的检测点















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









