






异常检测-高维数据-datawhale-task5
集成是⼦空间思想中常⽤的⽅法之⼀,可以有效提⾼数据挖掘算法精度。集成⽅法将多个算法或多个基
检测器的输出结合起来。其基本思想是⼀些算法在某些⼦集上表现很好,⼀些算法在其他⼦集上表现很
好,然后集成起来使得输出更加鲁棒。集成⽅法与基于⼦空间⽅法有着天然的相似性,⼦空间与不同的
点集相关,而集成⽅法使⽤基检测器来探索不同维度的⼦集,将这些基学习器集合起来。
feature bagging
总体思路
feature bagging与分类问题中的随机森林(random forest)很像,先将训练数据随机划分
(每次选取所有样本的(d/2)~(d-1)个特征,d代表特征数),得到多个子训练集,再在每个训练集上训练一个独立的模型(默认为LOF)并最终合并所有的模型结果(如通过平均)。

分数标准化和组合⽅法
需要将来⾃各种检测器的分数转换成可以有意义的组合的归⼀化值。分数标准化之后,还要选择⼀个组合函数将不同基本检测器的得分进⾏组合,最常⻅的选择包括平均和最⼤化组合函数。
孤立森林
参考
目前学术界对异常(anomaly detection)的定义有很多种,在孤立森林(iForest)中,异常被定义为“容易被孤立的离群点 (more likely to be separated)”,可以将其理解为分布稀疏且离密度高的群体较远的点。 在特征空间里,分布稀疏的区域表示事件发生在该区域的概率很低,因而可以认为落在这些区域里的数据是异常的。孤立森林是一种适用于连续数据(Continuous numerical data)的无监督异常检测方法,即不需要有标记的样本来训练,但特征需要是连续的。对于如何查找哪些点容易被孤立(isolated),iForest使用了一套非常高效的策略。在孤立森林中,递归地随机分割数据集,直到所有的样本点都是孤立的。在这种随机分割的策略下,异常点通常具有较短的路径。
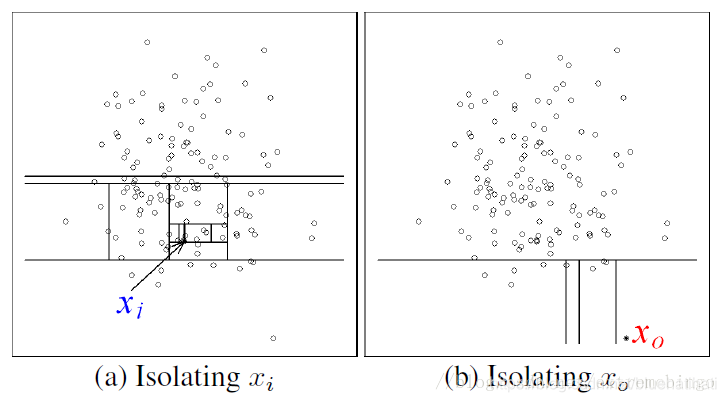
上图
x
i
x_i
xi是正常点,
x
o
x_o
xo是异常点,很明显的可以看出异常点只需要少数几次分割就被孤立出来了。这里的分割方式采用的是,随机选择一个特征以及拆分的值(这个值位于该特征的最小值和最大值之间)
孤⽴森林根据路径⻓度来估计每个样本点的异常程度。
在孤立森林中,小数据集往往能取得更好的效果。样本数较多会降低孤立森林孤立异常点的能力,因为正常样本会干扰隔离的过程,降低隔离异常的能力。子采样就是在这种情况下被提出的。孤立树的独有特点使得孤立森林能够通过子采样建立局部模型,减小对模型效果的影响。
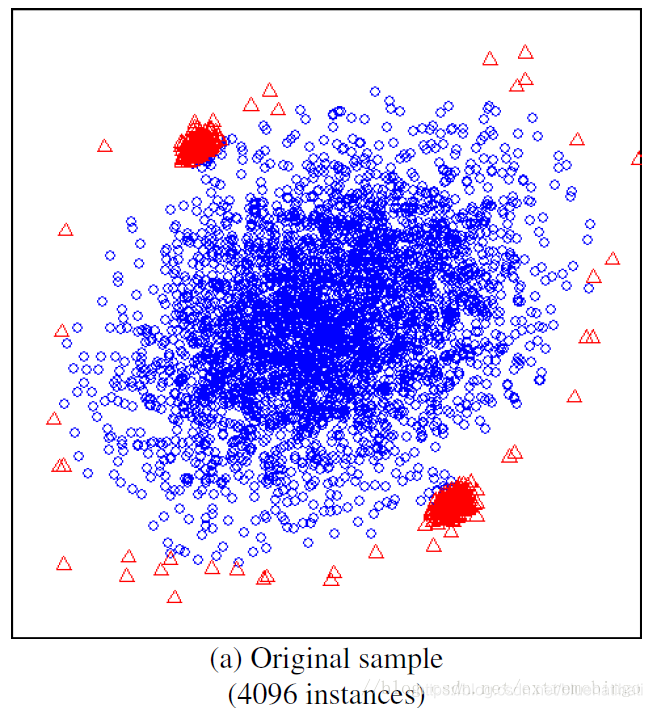
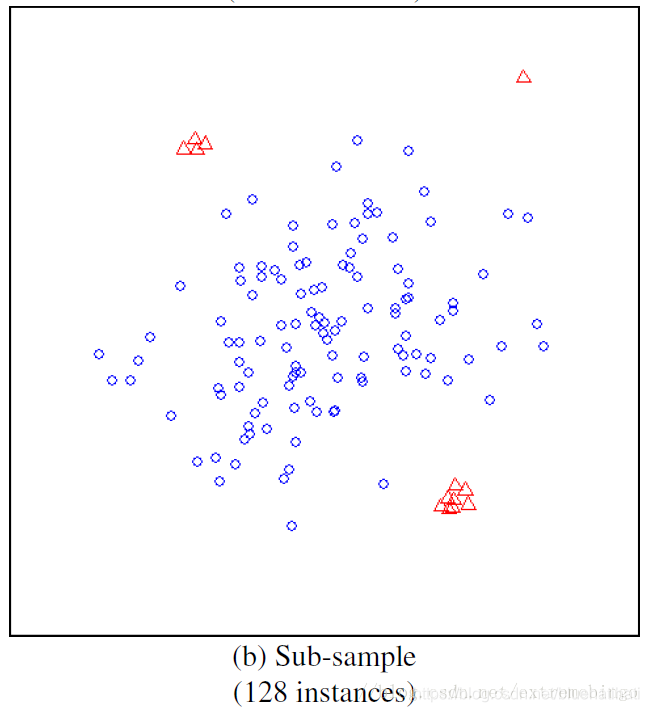
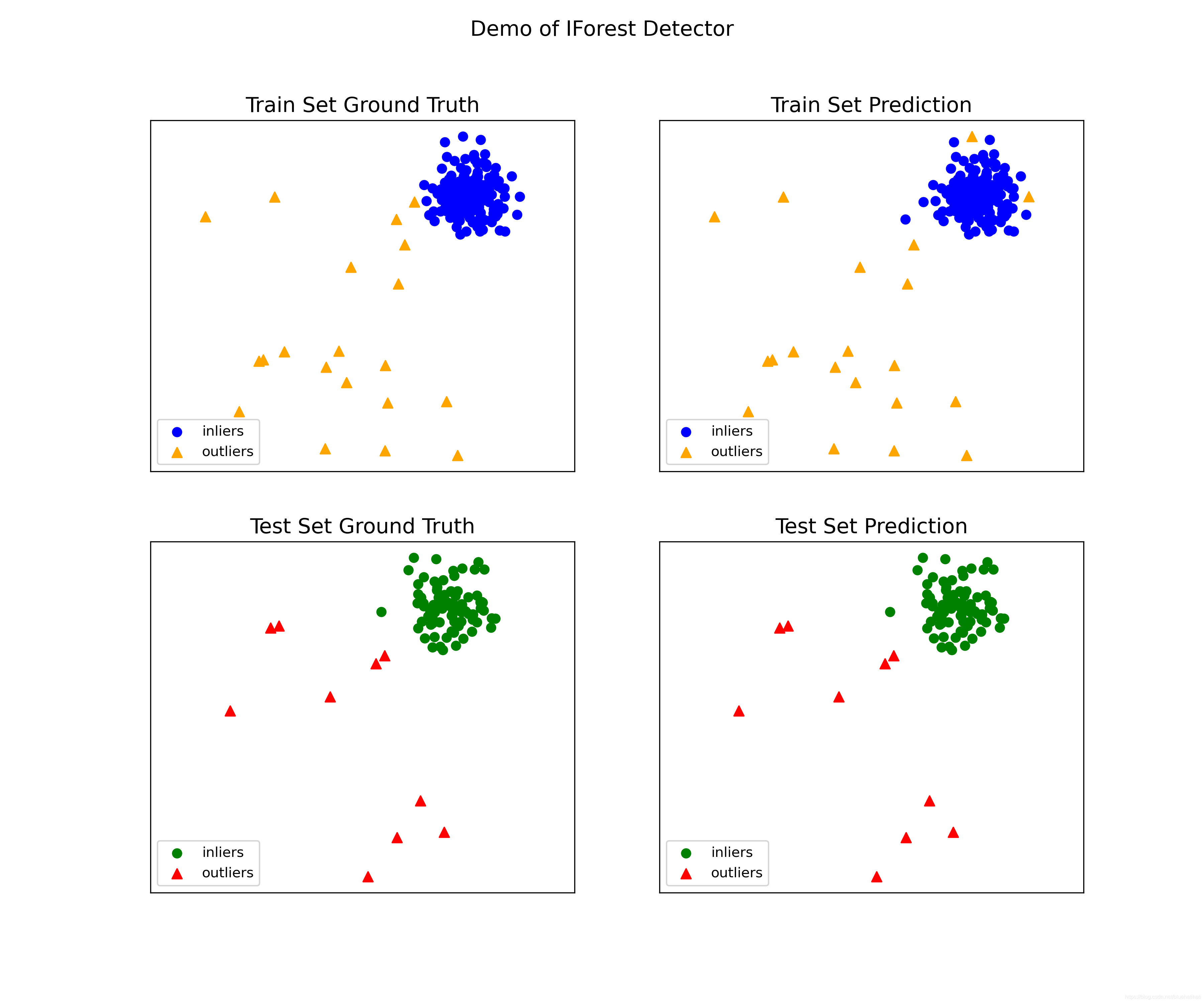
练习
使⽤PyOD库⽣成toy example并调⽤feature bagging
使⽤PyOD库⽣成toy example并调⽤Isolation Forests
# -*- coding: utf-8 -*-
from __future__ import print_function
import os
import sys
from pyod.models.iforest import IForest
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
# Generate sample data
X_train, y_train, X_test, y_test = \
generate_data(n_train=n_train,
n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42)
# train IForest detector
clf_name = 'IForest'
clf = IForest()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
# visualize the results
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









