









Linear regression 线性回归【付代码连接】
这是我做Machine Learning的第一篇日志,希望借此来好好整理一下自己关于Linear regression 的认识。
对于线性回归,大家可能立马会想到直角坐标系中的直线回归。不错,那正是最简单的回归曲线。

当然,线性回归不单单指一元一次方程上的回归,好包括多元多次方程,甚至包含高斯函数为kernel的分布方程和Sigmoidal function 做kernel的回归方程。因此,并没有一般人想象的那么简单。但也不是非常难,很多都是对简单的一元一次回归稍加拓展。下面我们来进行详细讲述线性回归(主要还是多项式上进行回归)。
线性回归主要是通过用多个函数对原函数进行模拟,尽可能使模拟函数的误差最低。这里必须了解一个误差方程,这个就是用来衡量这个误差的。
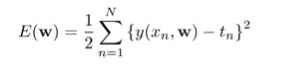
其中y(x,w)是我们的模拟函数,t是原始数据。w是模型中的参数,在这个算法中对应一个向量。N是样本的数目。就是对所有样本variance求和并除以2.
为了对这个函数进行最小化,最直接的想法就是对这个误差E(w)求导,然后求出倒数的最小值。这就是Batch gradient descent algorithm(批处理梯度下降)和 Stochastic gradient descent algorithm (随机梯度下降,也叫Incremental gradient descent)的主要思路。
Batch gradient descent algorithm
批处理梯度下降的基本公式如下:
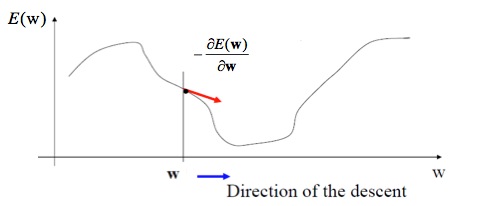
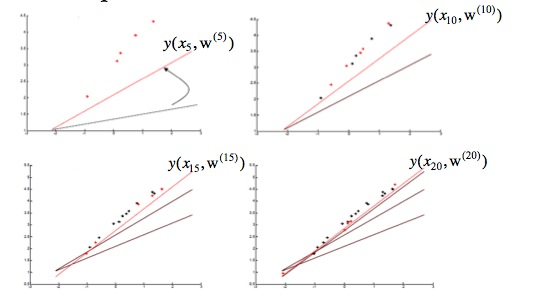
其中,w对应一项参数,wi相当于多项式x^i的系数。每次iteration的过程中,都根据所有数据值改变Wi。从而得到最终收敛的Wi。其过程图像如下图:
每一次迭代,都是根据所有函数值,来对E(w)进行减小,直到E(w)取最小值时候停止。Stochastic gradient descent algorithm
随机梯度下降的基本公式如下:
如果编过程序的会发现,Batch和Stochastic主要就是循环嵌套的顺序变化了一下,其他基本一致。Batch是对每一个Wi,用所有数据对其进行修正,而Stochastic是用一个数据,来对所有Wi进行修正。其意义就是每次用一个数据,如果数据量足够多,那么最后的你和效果也将会很好。下面是一个例子,可以看到不同样本数目下拟合效果的差异。当数据量越多,数据间差异很小的时候,Stochastic往往会取到很好的效果。
- Maximum Likelihood Regression
Maximum Likelihood Regression的推导过程相当之麻烦,不过简单来看,就是通过假设一个模型,推导出fiting函数和数据原本属性之间的关联性。然后通过线性代数把这个模型简单的表示出来。
这里可以根据你所选样本的维度,确定phi的次数,从而很容易得到PHI矩阵。然后代入上面公式,直接计算出Wml。这个用起来非常方便。
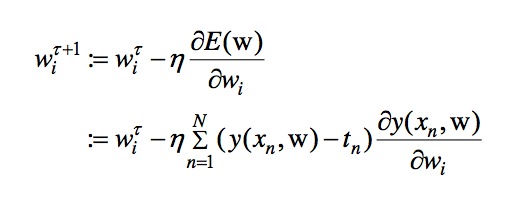
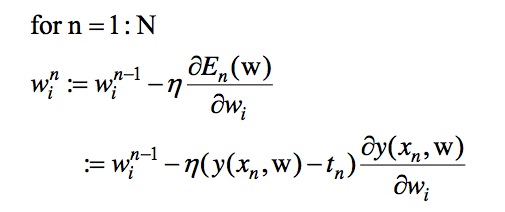

实际上,对于linear regression,可以选择不同的kernel function(or basis function)PHI来进行计算。
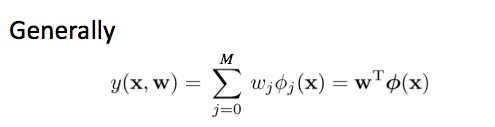
这里,PHI常见的函数有Polynomial(x^n),Gausian (exp(-(x-u)^2/(2*lamda^2)))和Sigmoidal(1/(1+exp(-u))).
对于这一课程,我也做了一些练习。练习的代码我最近会整理一下,发到GitHub https://github.com/charlesxu90/MachineLearning上,如果需要的人可以照着代码学习,或许会更方便些。















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









