







参考资料:
1)
2)原论文:https://arxiv.org/abs/1904.12787
3)参考博文:Graph Matching Networks for Learning the Similarity of Graph Structured Objects - xd_xumaomao - 博客园
(PyG生成一张图)这个还没写
一、背景
使用 距离来表示两个图之间的相似性
f(G1,G2)=−d(G1,G2), 其中G1,G2表示两个图
论文中提出了两个图,三个图的相似性计算方法
二、编码
1、
简单理解就是将图编程向量,通过计算向量之间的距离来计算图之间的距离
d(G1,G2)=dH(embed(G1),embed(G2)),
其中embed是将图映射到H维想两种,dH 是距离矩阵(使用的是欧几里得距离)
![]()
2、图输入:顶点V,边E。
点特征向量:每个节点都有特征i∈V,这就形成了特征向量xi
边特征向量:每个边都有 (i,j)∈E,形成了边特征向量编码xij , 如边的类型或者属性
3、嵌入模型由三部分组成
1)一层编码器
将xi和xij映射到隐层表示空间中,使用MLPs全连接层来对边和顶点节点进行表示,
通过两个独立的MLP分别对待比对的两张图片进行编码。
需要注意的是这个编码器是对于每个节点和每条边进行单独编码的,并不涉及到节点之间或者边之间信息的交互

2)传播层

这里fmessage是一个MLP,输入是括号里面特征的拼接,该层的作用是对图中编码后的边特征和边两边的节点特征进行联合编码。
fnodefnode可以是MLP或RNN,这层的作用是以节点为中心对它的一阶邻域信息进行聚集(accumulate)。为了聚集节点的一阶领域信息这里采用了sum,也可以是mean, max 或attention-based weighted sum。
总的来说传播层的作用就是以节点为中心通过多个传播层来聚集节点的一阶领域信息。
3)信息聚合
简单表示:
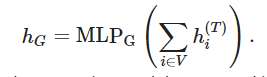















 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









