







 本文介绍了一种新型图匹配网络模型,用于解决图结构对象的相似性检索和匹配问题。该模型通过图神经网络生成图嵌入,利用交叉图注意力机制计算图对的相似度得分,实验证明其在不同领域,尤其是软件漏洞检测中表现出色。
本文介绍了一种新型图匹配网络模型,用于解决图结构对象的相似性检索和匹配问题。该模型通过图神经网络生成图嵌入,利用交叉图注意力机制计算图对的相似度得分,实验证明其在不同领域,尤其是软件漏洞检测中表现出色。
Graph Matching Networks for Learning the Similarity of Graph Structured Objects笔记
摘要
文章处理了检索和匹配图结构对象的挑战性问题。文章两个贡献:1. 证明了解决各种基于结构数据的监督预测问题高效模型graph neural networks 可以用来训练来生成向量空间中的图嵌入表示,有利于做相似推理。2. 我们提出了一个崭新的图匹配网络模型,将一对图作为输入,计算相似分数。通过一种新的基于交叉图注意力的匹配机制,对图像进行联合推理。我们证明了我们的模型在不同领域的有效性,包括基于控制流图的功能相似度搜索这一具有挑战性的问题,它在软件系统漏洞检测中起着重要的作用。
贡献
- 我们证明了GNNs可以用来生成图嵌入,用于相似度学习
- 我们提出了图匹配网络(graph matching matching),可以通过交叉图注意力匹配来进行计算相似度。
- 实验表明提出的相似度学习模型可以在一系列应用上实现好的性能,比无结构模型和建立的手工设计基准上实现了更好的性能。
深度图相似学习
给定:
- G 1 = ( V 1 , E 1 ) , V 1 为 顶 点 集 , E 1 为 边 集 G_1=(V_1,E_1),V_1为顶点集,E_1为边集 G1=(V1,E1),V1为顶点集,E1为边集
- G 2 = ( V 2 , E 2 ) G_2=(V_2,E_2) G2=(V2,E2)
计算: 相似度得分: s ( G 1 , G 2 ) s(G_1,G_2) s(G1,G2)
- 结点特征: x i x_i xi
- 边特征: e i j e_{ij} eij
3.1 图嵌入模型
模型包含3个部分:(1)编码器
(2)传播层
(3)聚合器
编码器
使用独立的MLP将点和边特征去初始化结点和边的向量表示
h
i
(
0
)
=
M
L
P
n
o
d
e
(
x
i
)
,
∀
i
∈
V
h_i^{(0)}=MLP_{node}(x_i),{\forall} i\in V
hi(0)=MLPnode(xi),∀i∈V
e
i
j
=
M
L
P
e
d
g
e
(
x
i
j
)
,
∀
(
i
,
j
)
∈
E
e_{ij}=MLP_{edge}(x_{ij}),\forall (i,j)\in E
eij=MLPedge(xij),∀(i,j)∈E
传播层
将顶点表示集合
{
h
i
(
t
)
}
i
∈
V
\{h_i^{(t)}\}_{i\in V}
{hi(t)}i∈V映射到新的顶点表示
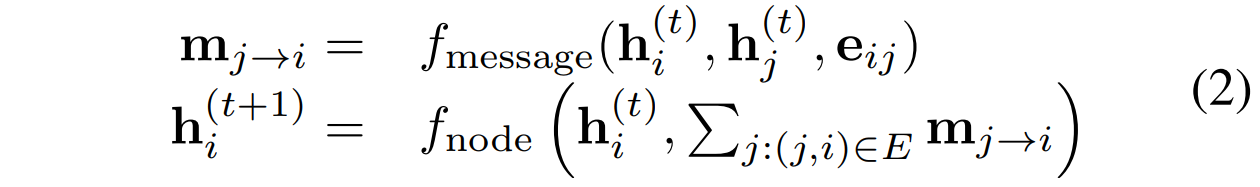
- f m e s s a g e f_{message} fmessage是传统串接的input上的MLP
-
f
n
o
d
e
f_{node}
fnode是MLP或者是循环神经网络为核心的网络。
领域的信息聚合可使用简单的 s u m , m e a n , m a x sum,mean,max sum,mean,max或者是用基于attention的权重聚合。
聚合器
经过
T
T
T轮传播之后我们将节点表示集
{
h
i
T
}
\{h_i^{T}\}
{hiT}作为输入,计算图水平的表示
h
G
=
f
G
(
{
h
i
(
T
)
}
)
h_G=f_G(\{h_i^{(T)}\})
hG=fG({hi(T)}),我们用下面的聚合模型
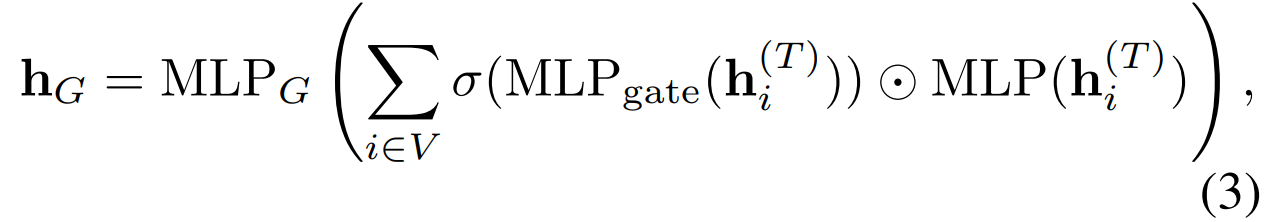 这里用的是门向量去过滤掉不相关的信息。经验上来说,这比简单的相加更加有效。
这里用的是门向量去过滤掉不相关的信息。经验上来说,这比简单的相加更加有效。
将配对的
(
G
1
,
G
2
)
(G_1,G_2)
(G1,G2)经过计算得到图表示
h
G
1
,
h
G
2
h_{G_1},h_{G_2}
hG1,hG2,在经过向量空间中的相似度度量函数(欧式距离,cosine,海明相似度)计算相似度。
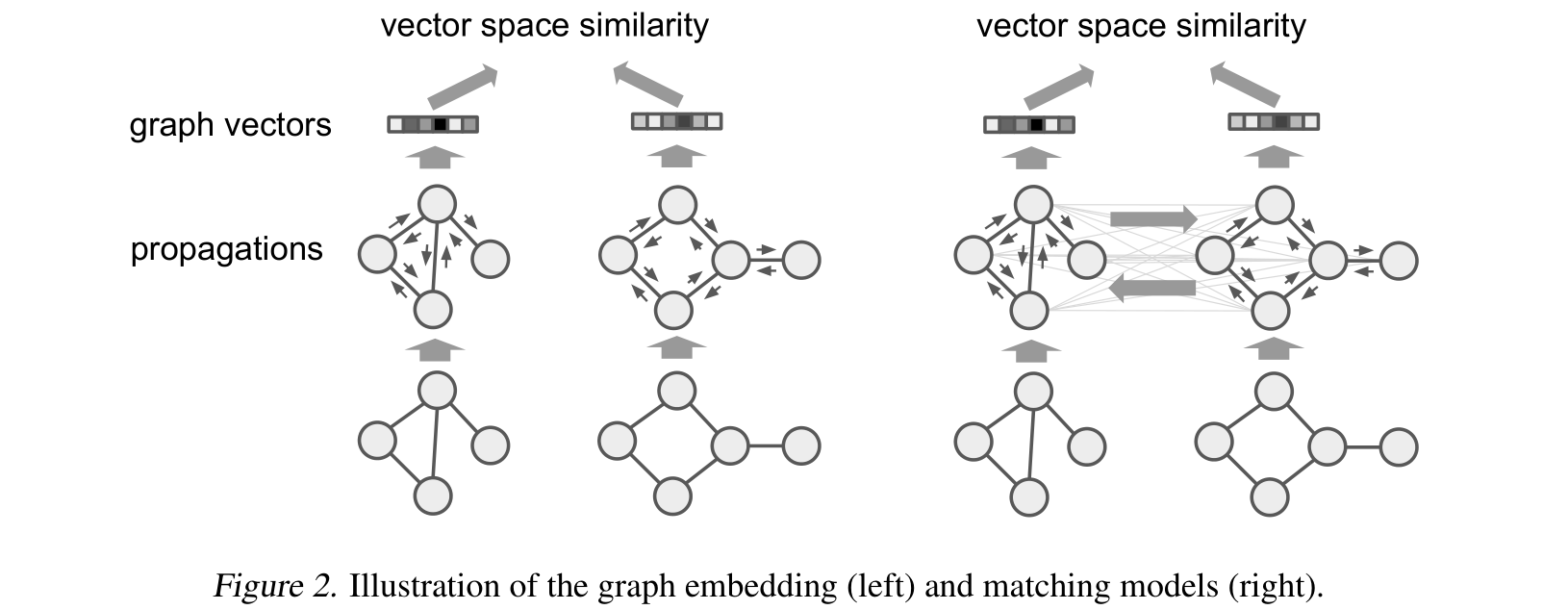
3.2 图匹配网络(GMN)
与嵌入模型相比,这些匹配模型联合计算对上的相似度评分,而不是首先独立地将每个图映射到一个向量。
提出的模型不仅仅考虑单个图中的边的信息聚合,而且考虑一个图中的一个顶点与另一个图的其他顶点的匹配度向量。即:
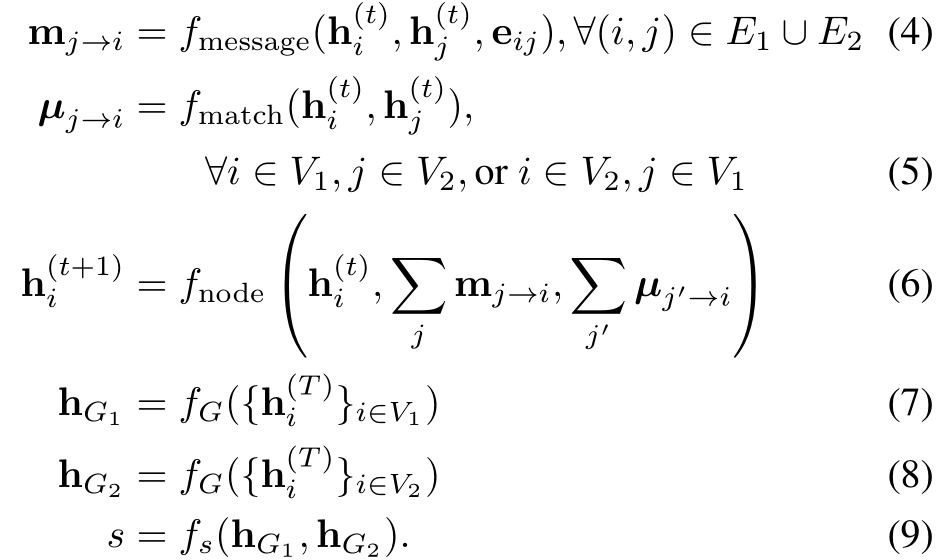
- f m e s s a g e f_{message} fmessage用来计算边信息 ( i , j ) ∈ E 1 ∪ E 2 (i,j)\in E_1\cup E_2 (i,j)∈E1∪E2
- f n o d e e f_{nodee} fnodee是MLP或者是循环神经网络为核心的网络。
-
f
m
a
t
c
h
f_{match}
fmatch表示图交叉信息,我们用attention模型计算
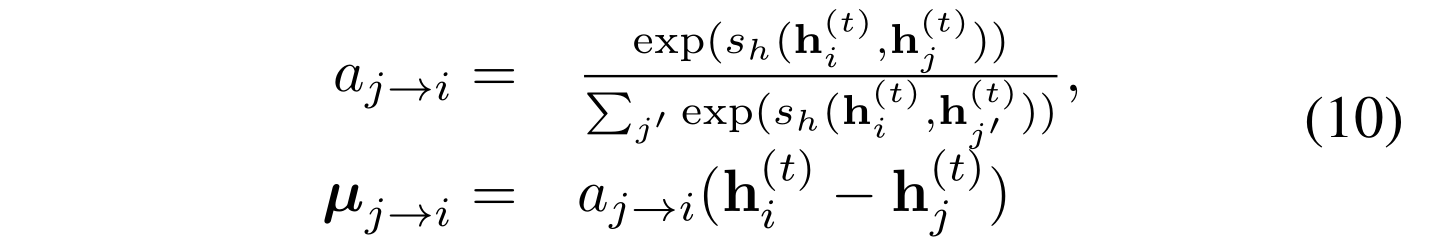 -
s
h
s_h
sh是向量空间的相似度度量函数,像欧式或者cosine相似度。所以有
-
s
h
s_h
sh是向量空间的相似度度量函数,像欧式或者cosine相似度。所以有
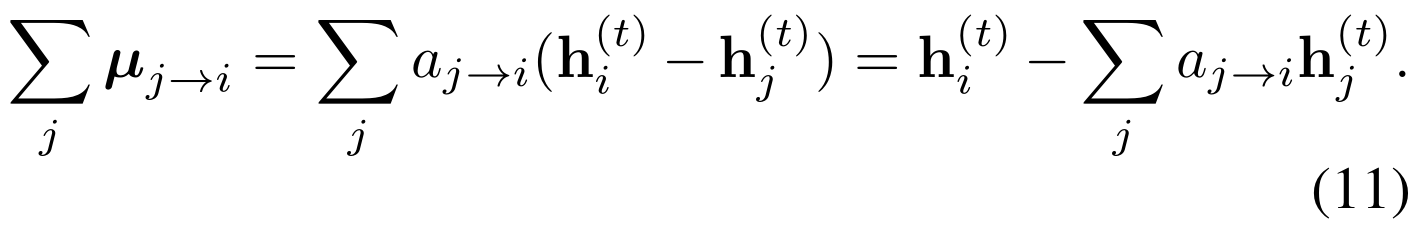 (11)式直观上来说是用来衡量
h
i
(
t
)
h_i^{(t)}
hi(t)与另一个图上与其最近的邻接点的不同。
(11)式直观上来说是用来衡量
h
i
(
t
)
h_i^{(t)}
hi(t)与另一个图上与其最近的邻接点的不同。
从(10)式可以看出规范化的系数
a
j
→
i
a_{j\to i}
aj→i依赖于
{
h
j
(
t
)
}
\{h_j^{(t)}\}
{hj(t)}。
3.2 learning
- 成对数据( ( G 1 , G 2 , t ) (G_1,G_2,t) (G1,G2,t) t 为标签)
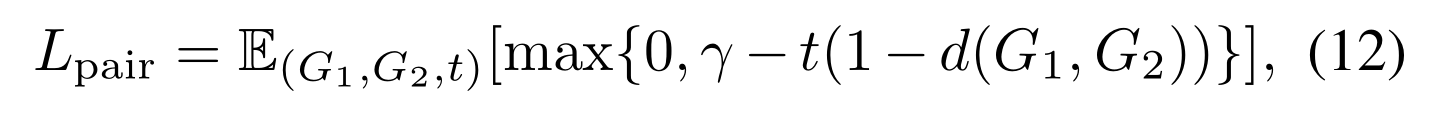
- t ∈ − 1 , 1 t\in {-1,1} t∈−1,1
- γ \gamma γ是边缘参数
- d ( G 1 , G 2 ) = ∣ ∣ h G 1 − h G 2 ∣ ∣ d(G_1,G_2)=||h_{G_1}-h_{G_2}|| d(G1,G2)=∣∣hG1−hG2∣∣是欧式距离
- t=1表示相似,loss使得 d < 1 − γ d<1-\gamma d<1−γ
- t=-1表示不相似, d > 1 + γ d>1+\gamma d>1+γ
- 三元输入数据
(
G
1
,
G
2
,
G
3
)
(G_1,G_2,G_3)
(G1,G2,G3)
G1与G2之间的相似度小于G1与G3,所以loss 为
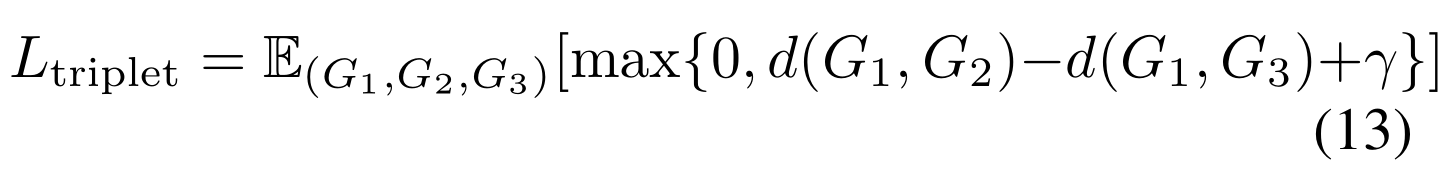 这个loss 强迫
d
(
G
1
,
G
2
)
+
γ
<
d
(
G
1
,
G
3
)
d(G_1,G_2)+\gamma<d(G_1,G_3)
d(G1,G2)+γ<d(G1,G3)
这个loss 强迫
d
(
G
1
,
G
2
)
+
γ
<
d
(
G
1
,
G
3
)
d(G_1,G_2)+\gamma<d(G_1,G_3)
d(G1,G2)+γ<d(G1,G3) - 图空间搜索汉明相似度改进loss
由于图空间太大,所以如果将最后图的表示用一个二值向量会更加高效。即 h G ∈ { − 1 , 1 } H h_G\in \{-1,1\}^{H} hG∈{−1,1}H, 所以我们最小化正例,最大化负例,也就是
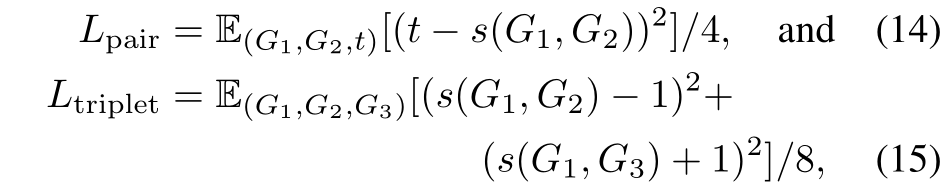
- s ( G 1 , G 2 ) = 1 H ∑ i = 1 H t a n h ( h G 1 i ) s(G_1,G_2)=\frac{1}{H}\sum_{i=1}^H tanh(h_{G_{1}i}) s(G1,G2)=H1∑i=1Htanh(hG1i), t a n h ( h G 1 i ) tanh(h_{G_{1}i}) tanh(hG1i)是近似平均汉明相似度
- 两个loss范围都是[0,1], 将正例的hamming相似度趋于1,负例的趋于-1
4. 实验
- 图编辑距离
图数据g1和g2之间的编辑距离定义为将g1转换为g2所需的最小编辑操作数。我们通过对具有n个节点的随机二项图 G 1 G_1 G1和边按概率p来抽样生成训练数据。
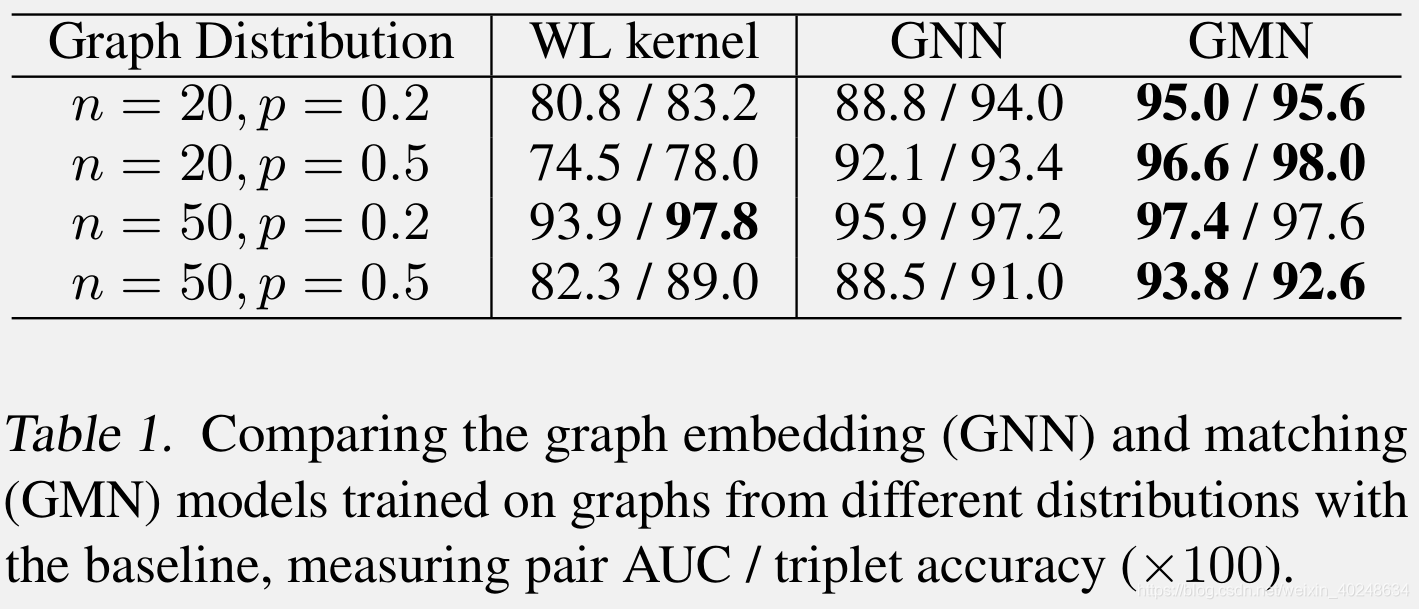
- 基于控制流图的二进制函数相似性搜索

















 1775
1775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









