







 这篇博客探讨了H-Index的概念,它涉及到给定论文引用次数的问题。通过分析边界条件,如h=0(无引用或全部为0)和h=n(所有论文引用次数至少为n),博主提出了一种优化的解决方案。初始的暴力方法时间复杂度为O(n^2),不适合大规模数据。通过使用堆排序将论文引用次数排序,时间复杂度降低到O(nlogn)。排序后,只需线性时间O(n)即可找到满足条件的最大h值,从而实现高效解题。
这篇博客探讨了H-Index的概念,它涉及到给定论文引用次数的问题。通过分析边界条件,如h=0(无引用或全部为0)和h=n(所有论文引用次数至少为n),博主提出了一种优化的解决方案。初始的暴力方法时间复杂度为O(n^2),不适合大规模数据。通过使用堆排序将论文引用次数排序,时间复杂度降低到O(nlogn)。排序后,只需线性时间O(n)即可找到满足条件的最大h值,从而实现高效解题。
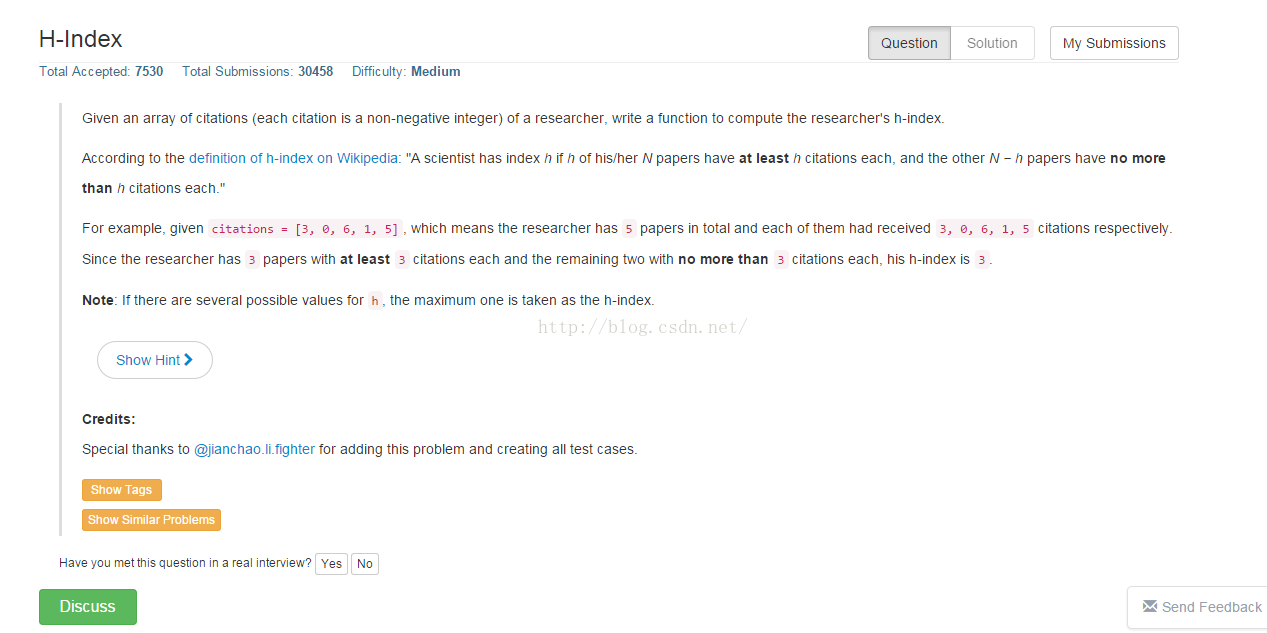
题意:现在给你n篇论文,然后告诉你每篇论文的引用次数,求一个最大的整数h,使得有h篇论文的引用次数至少为h次,且剩下的n-h篇论文的引用次 数不超过h次。
从题意中可知道0<=h<=n,考虑边界情况,h=0:没有论文或者所有论文的引用次数都是0次;h=n:有n篇论文,且每篇论文的引用次数都至少为n次。理解清楚边界情况后,中间的其实也就知道了。
首先还是考虑暴力方法,即h从n→1枚举,然后统计引用数>=h的论文数cnt,若cnt==h,则找到。时间复杂度O(n^2),显然不行。
接下来考虑下先排序,此处我用的堆排序,时间复杂度O(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2597
2597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









