







 该论文提出了一种新的视频表示方法——Rank Pooling,通过学习排名函数捕捉视频帧随时间的演变顺序,以此来表达视频并用于动作识别。Rank Pooling能有效处理不同视频中动作时间长度的差异,通过训练线性ranking machine学习帧的排列顺序,并用其参数作为视频的表示,用于分类器训练。
该论文提出了一种新的视频表示方法——Rank Pooling,通过学习排名函数捕捉视频帧随时间的演变顺序,以此来表达视频并用于动作识别。Rank Pooling能有效处理不同视频中动作时间长度的差异,通过训练线性ranking machine学习帧的排列顺序,并用其参数作为视频的表示,用于分类器训练。
Rank Pooling for Action Recognition
2015/12 PAMI
作者:http://users.cecs.anu.edu.au/~basura/
首先,framework
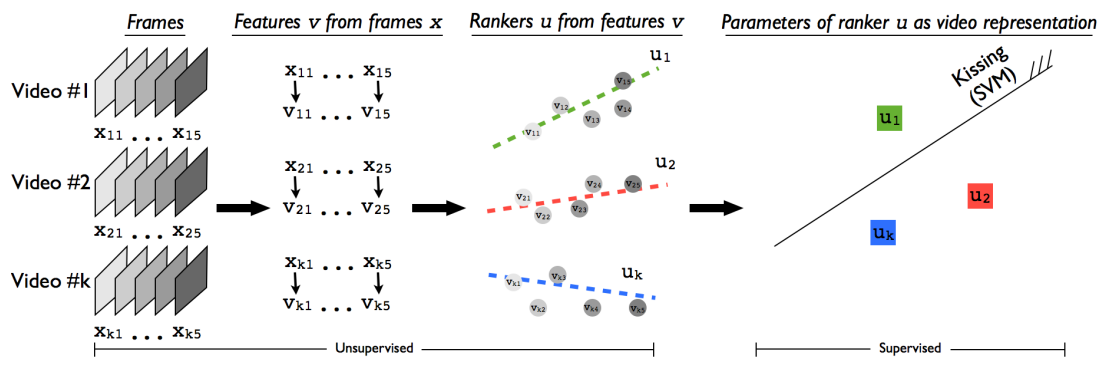
1、对每一帧都进行特征编码,作者选择的特征有HOG HOF MBH TRJ
2、进行平滑
3、rankSVM,求出参数u
4、对参数u进行分类(SVM)
所以实际上就是用参数u来表达一个视频,在其所在空间进行分类
abstract & intro
视频的表示方法有很多,一般是把它看作帧的序列。论文提出一种新的方法——基于函数的时间池化方法,捕捉视频序列的潜在结构,比如说帧级别的特征随着时间是如何演化的。
in this paper:
- 提出了新的视频表达方式。rank pooling。
- 可以捕捉视频级别的时间演化。虽然同一个动作的时间长短是不一样的,但是元动作的时间顺序是不变的。
- 通过训练线性ranking machine来捕捉特定视频的时间顺序。具体来说,就是对于给定视频的所有帧, 学习如何按照时间顺序来arrange这些帧。
- 用ranking function的参数编码视频的帧序列。
- ranking machine采用有监督学习方式,在同一个动作的不同视频上进行训练,应当得到相似的ranking function。因此,提出用ranking machine的参数作为新的动作识别的表达形式。在这种新的representation 上来训练分类器。
Video representations
函数参数作为时间表达
视频帧: xt(xt∈RD)
视频: X=[x1,x2,...,xn]
给定一个向量序列,先进行平滑(后面详细讨论如何平滑),得到新的序列: V=[v1,v2,...,vn]
( x1:t or
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









