






编译原理第五章学习总结
这一章我们主要需进行学习的是自下而上语法分析的方法,它的意义是指从输入串开始,或者从语法树的末端开始步步向上逐步规约,知道根结。
一学习内容
首先我们了解到我们所研究的自下而上的分析法,它是一种移进归约法。它的基本思想是,又或是它的大意是我们用一个寄存符号的先进后出栈,将输入符号一个一个的移进到栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分归约为该产生式的左部符号。
自下而上分析法的中心问题是怎样判断栈顶符号串的可归约性以及如何归纳。在各种不同的自下而上分析法的共同特点是边输入单词符号边归约。
/以下介绍规范规约的概念
①短语

②直接短语
③句柄

/符号栈的使用与语法树的表示
栈是语法分析的一种基本数据结构
算符优先分析法
算符优先分析法是一种简单直观、广为使用的自下而上分析法。有利于表达式分析,宜于手工实现。但算符优先分析法不是一种规范归约法。
它的思路是定义算符之间优先关系,借助这种关系来寻找“可归约串”和进行归纳。
①算符文法的定义:一个文法,如果它的任一产生式的右部都不含两个相继的非终结符,即不含如下形式的产生式右部: ...QR...
则我们称该文法为算符文法。
/定义终结符之间的优先关系

/构造算符优先关系表

/构造集合FIRSTVT(P)的算法

/算符优先分析算法的顺序
1.问题的提出 自下而上分析
移进-归约法:句柄为可归纳串
算符优先分析法:最左素短语为可归纳串
2.素短语
指一个句型的短语,它至少包括有一个终结符号且除去它本身之外不再含任何更小的素短语
3.最左素短语
处在句型最左端那个素短语成为最左素短语
/算符优先分析算法和设计
(1)句型的一般表示形式:
#N1a1N2a2…NnanNn+1#
其中,每个ai都是终结符,Ni是可有可无的非终结符
(2)定理:
一个算符优先文法G的任何句型的最左素短语是满足如下条件的最左子串 Njaj…NiaiNi+1,
aj-1<. aj
aj=. aj+1,aj+1 =. aj+2,…,ai-1 =. ai
ai>. ai+1
注:出现在左端或右端的非终结符一定属于这个素短语
算符优先分析一般不等于规范归约
/优先函数

/优先函数的构造方法
(1)对于每个终结符a,令其对应两个符号fa和ga,画一张以所有符号fa和ga为结点的方向图。
如果a>.b,则从fa画一条弧至gb
如果a<.b,则从gb画一条弧至fa 。
(2)对每个结点都赋予一个数,此数等于从该结点出发所能到达的结点(包括出发点自身)。
赋给fa的数作为f(a)
赋给ga的数作为g(a)。
(3)检查所构造出来的函数f和g是否与原来的关系矛盾。若没有矛盾,则f和g就是要求的优先函数,若有矛盾,则不存在优先函数。
/LR分析方法
是一种自下而上的分析方法
LR分析法的归约过程是规范推导的逆过程,所以LR分析过程是一种规范归约过程
LR分析方法是一种适用于一大类上下文无关文法的分析方法
比较复杂,不适于用手工实现,可借助于YACC/bison实现
(1)动作表
ACTION[s,a]:当状态s面临输入符号a时,应采取什么动作
每一项ACTION[s,a]所规定的四种动作:
<1>. 移进 把(s,a)的下一状态s’=GOTO[s,a] 和输入符号a推进栈,下一输入符号变成现行输入符号.
<2>. 归约 指用某产生式A进行归约. 假若的长度为r, 归约动作是A, 去除栈顶r个项,使状态sm-r变成栈顶状态,然后把(sm-r,A)的下一状态s’=GOTO[sm-r, A]和文法符号A推进栈.
<3>. 接受 宣布分析成功,停止分析器工作。
<4>. 报错 发现源程序含有错误,调用出错处理程序
/LR(0)项目集族和分析表的构造
活前缀特点:
该前缀加上被分析串中未被分析的终结符,就可以构成一个规范句型
只要输入串的已扫描部分可归约成一个活前缀,意味着扫描过的部分没有错误
/识别活前缀的有限自动机
LR(0)项目
A→β·
A→β1·β2
A→·α
我们把右部某位置上标有圆点的产生式称为相应文法的一个LR(0)项目,特别对形如A→ε的产生式,A→·。
文法的全部LR(0)项目将是构造识别它的所有活前缀的有限自动机的基础。
二习题练习

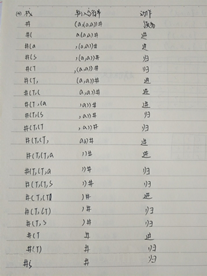



三总结感悟
相对于前面几章的学习,本章的内容相对复杂且逻辑性较高。短语、句柄以及算符优先关系表的知识逻辑较为容易理解,
但是对于文法产生式的识别以及NFA算法比较繁琐,需要有比较强的分析能力以及逻辑表达能力。还有通过符号栈的运用进行自下而上的语法分析与设计,也比较需要细节方面的东西。状态表的构造需要对每个状态之间的转化有明确的认识。LR分析法的学习和理解对我有部分难度,闭包的处理和一些概念的理解一开始比较迷茫。但是,将课本的知识和课件上的例题相结合,反复琢磨理解,总会找到解题的方法技巧。编译原理的学习,就是对于概念的理解和逻辑思维的训练,加上不断的习题练习,然后不断的复习巩固,必然会找到窍门。同样在一些习题的细节处理上,有的时候也会将部分细节遗忘,这也是我在本章的学习过程中需要注意的地方,我也会进行不断的改进,完善自我。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









