










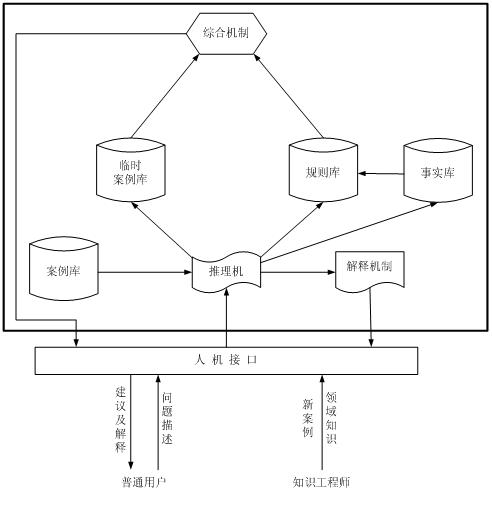
本系统是由CBR和RBR组成的混合系统。系统结构如下图所示。系统的核心是推理机,推理机根据用户输入的故障描述,既可以将故障描述转化为新的案例,从而进行对案例库进行操作;又可以将故障描述转化为事实,对规则库进行操作。但CBR和RBR的地位并不是等同的,CBR起主导作用,RBR对CBR起监督作用,二者的推理结果由综合机制进行综合。本系统采用友好的人机界面,普通用户输入故障描述后,系统经推理后给出诊断建议,并对给出的建议进行解释。另外,为了便于对系统知识(案例库、知识库和事实库)进行管理,系统可以由知识工程师进行修改。
2、案例表示与存储
参见博文“EMC-CBR故障诊断研究(一、二)”
3、案例检索
参见博文“EMC-CBR故障诊断研究(三)”
4、案例重用
案例重用的主要任务是对检索到的案例的结论进行修正。基本思想就是将案例库中与目标案例最相似的案例的结论与次相似的案例的结论进行对比,如果二者仅仅是谓词函数的参数不同,可以认定无需对最佳匹配案例进行修改;如果二者不仅参数不同而且有谓词上的出入,则需启用基于规则的推理,最终利用CBR和RBR的综合机制利用RBR的结论对最佳匹配案例的结论进行修正。
5、 href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_filelist.xml" rel="File-List" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_themedata.thmx" rel="themeData" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_colorschememapping.xml" rel="colorSchemeMapping" /> 案例的保存
在案例保存时要进行模式归纳(Schema Induction)。模式归纳的含义就是指:如果类比导致了一个解,则执行两类似体的泛化过程,以便形成一个抽象的案例模式。简而言之,就是寻找两类似体的共性,然后加以抽象和泛化。
案例保存的过程可以看作一个归纳学习的过程,很多归纳学习的方法都可以应用于案例保存,如产生预测试方法(INDUCE1.2)。6、案例的维护
href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_filelist.xml" rel="File-List" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_themedata.thmx" rel="themeData" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_colorschememapping.xml" rel="colorSchemeMapping" />
心理学家在研究记忆机理时,提出了著名的遗忘曲线理论,即长期不用的信息将会被逐渐遗忘。在基于案例推理中,案例库的维护很重要,必须将长期不用的案例删除,因为这种案例很可能是噪声案例,例如误诊的病例、误判的案件等。Aha建议对案例库中的每个案例建立一个匹配记录,就可以删除那些噪声或无用的案例,以维护案例库的有效性。Aha提出案例求精算法IB3,表述如下[51]:
输入:案例库S和测试案例集T
输出:精化案例库S’
过程:
(1) 从测试案例集T中任选一个测试案例t;
(2) 设法从案例库S中找到一个案例s,它与t有最佳匹配,其相似度超过某个阈值;
(3) 如果找不到这样的s,则转到(8);
(4) 若确认t和s属于同一类,则转(9);否则把t加上它所属的类c的标志后存入库S;
(5) 从库S中找出所有这样的案例si,它们和t的相似程度至多不大于s和t的相似程度,所有这些si的匹配记录要扣分;
(6) 从库S中删除记录分数小于某个规定值的所有案例;
(7) 如果测试集的案例已经用完,则算法结束,否则转(1);
(8) 从库S中任选一个案例s,转到(4);
(9) 从库S中找出所有这样的案例si,它们和t的相似程度至少不亚于s和t的相似程度;
(10)转到(7)。
7、 href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_filelist.xml" rel="File-List" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_editdata.mso" rel="Edit-Time-Data" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_oledata.mso" rel="OLE-Object-Data" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_themedata.thmx" rel="themeData" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_colorschememapping.xml" rel="colorSchemeMapping" /> 基于规则的推理基于规则推理(RBR)子系统是一个简化的专家系统。RBR子系统由事实库和规则库组成,规则库中存放由专家经验中提取出来的专家规则,以产生式表示;事实库是由推理机通过人机界面从用户的输入中提取出来的事实,以命题逻辑表示。
例如,和上面讨论的case6相关的规则有“使用导电橡胶、衬垫之类的屏蔽材料时,不但要保证接触面上的良好的导电性(接触面去除所有漆),而且还要保证一定的压缩量。”,可以用产生式规则表述如下:
Shielding(product, conductive_tape) ∨ Shielding(product, condutive_gasket) => Wipe_off(interface, lacquer) ∧ (Compress(conductive_tape) ∨ Compress(conductive_ gasket))
RBR的推理采用不确定性推理。不确定推理包括前提条件的不确定性、结论的不确定性以及推理过程的不确定性。根据电磁兼容知识的特点,必须综合利用这三种不确定性才能比较确切的模拟电磁兼容专家的推理过程。不确定推理的通用表示方法为[20]:IF [(p1, f1, t1) AND (p2, f2, t2) AND … AND (pm, fm, tm)]
THEN [((q1, g1, s1), (q2, g2, s2)…)] WITH CF(R)
其中,pi表示模糊前提条件,qi表示模糊结论及动作,CF(R)为可信度,fi是表达前件的可能性分布,ti是前件的确信程度,gi是表达结论的可能性分布,s1是结论的确信程度。
对于前件,可以采用表达方案:
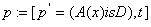 ,p
为模糊命题,x
为对象名,A是
x的属性名,D是确定性状态表达,
是
p的相应的确定性命题,
,p
为模糊命题,x
为对象名,A是
x的属性名,D是确定性状态表达,
是
p的相应的确定性命题,
是命题的不确定性度量。
例如,某模糊命题为:
如果为感应耦合(可信度0.9),且电路频率很高(模糊数0.8),则耦合为容性耦合(可信度0.7)。
则该命题可以表述为:
IF [(p1,0.9) AND (p2,0.8)] THEN[(q1, 0.7)] WITH CF(R)
其中,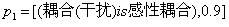 ,
,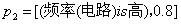 ,
,
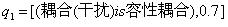 ,R为根据不确定推理理论计算出的整个命题的可信度。
,R为根据不确定推理理论计算出的整个命题的可信度。
8、
href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_filelist.xml" rel="File-List" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_themedata.thmx" rel="themeData" /> href="file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtmlclip1/01/clip_colorschememapping.xml" rel="colorSchemeMapping" />
CBR和RBR的综合机制
当目标案例和CBR案例库中的源案例的相似度低于阈值时,启用RBR。如果利用RBR能够推导出结果,则将RBR的结论作为最终诊断结果,将CBR的结论作为建议一同提交给用户;如果由于规则的不完整RBR无法推导出结论,则将CBR的结论作为诊断结果提交给用户,但此时必须注明该结论的可信度(可信度可以用目标案例和源案例的相似度表示)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









