







Spark公开了pyhton的编程模型-PySpark,开发者通过PySpark可以很容易开发Spark application。
但是Python API和Scala API略有不同:
- Python是动态语言,RDD可以持有不同类型的对象
- PySpark目前并没有支持全部的API,但核心部分已经全部支持
在PySpark里,RDD支持scala一样的方法,只不过这些方法是Python函数来实现的,返回的也是Python的集合类型;对于RDD方法中使用的短函数可以使用Python的lambda语法实现。
不过python开发Spark Application拥有很多优势:
- 不需要编译,使用方便
- 可以与许多系统集成,特别是NoSQL大部分都提供了python开发包
1:开发环境
笔者的Spark开发环境参见
Spark1.0.0 开发环境快速搭建,另外在操作系统安装的时候已经默认安装了python:
- 虚拟集群中各节点安装的CentOS6.4,所带Python版本是Python2.6.6
- 客户机安转的是Ubuntu14.0.4,所带的Python版本是Python2.7.6
- Spark1.0.0的Python程序也可以使用spark-submit提交,关于spark-submit的用法参见Spark1.0.0 应用程序部署工具spark-submit 。
- 本篇是对Spark1.0.0 多语言编程的需求进行Python实现
2:sogou日志数据分析python实现
A:用户在00:00:00到12:00:00之间的查询数
import sys
from pyspark import SparkContext
if __name__ == "__main__":
if len(sys.argv) != 2:
print >> sys.stderr, "Usage: SogouA <file>"
exit(-1)
sc = SparkContext(appName="SogouA")
sgRDD = sc.textFile(sys.argv[1])
print sgRDD.filter(lambda line : line.split('\t')[0] >= '00:00:00' and line.split('\t')[0] <= '12:00:00').count()
sc.stop()
运行结果:527300
B:搜索结果排名第1,但是点击次序排在第2的数据有多少?
import sys
from pyspark import SparkContext
if __name__ == "__main__":
if len(sys.argv) != 2:
print >> sys.stderr, "Usage: SogouB <file>"
exit(-1)
sc = SparkContext(appName="SogouB")
sgRDD = sc.textFile(sys.argv[1])
print sgRDD.filter(lambda line : len(line.split('\t')) == 5).map(lambda line : line.split('\t')[3]).filter(lambda line : int(line.split(' ')[0])==1 and int(line.split(' ')[1])==2).count()
sc.stop()
运行结果:79765
C:一个session内查询次数最多的用户的session与相应的查询次数
import sys
from pyspark import SparkContext
if __name__ == "__main__":
if len(sys.argv) != 2:
print >> sys.stderr, "Usage: SogouC <file>"
exit(-1)
sc = SparkContext(appName="SogouC")
sgRDD = sc.textFile(sys.argv[1])
print sgRDD.filter(lambda line : len(line.split('\t')) == 5).map(lambda line : (line.split('\t')[1],1)).reduceByKey(lambda x , y : x + y ).map(lambda pair : (pair[1],pair[0])).sortByKey(False).map(lambda pair : (pair[1],pair[0])).take(10)
sc.stop()
运行结果:[(u'11579135515147154', 431), (u'6383499980790535', 385), (u'7822241147182134', 370), (u'900755558064074', 335), (u'12385969593715146', 226), (u'519493440787543', 223), (u'787615177142486', 214), (u'502949445189088', 210), (u'2501320721983056', 208), (u'9165829432475153', 201)]
3:疑问
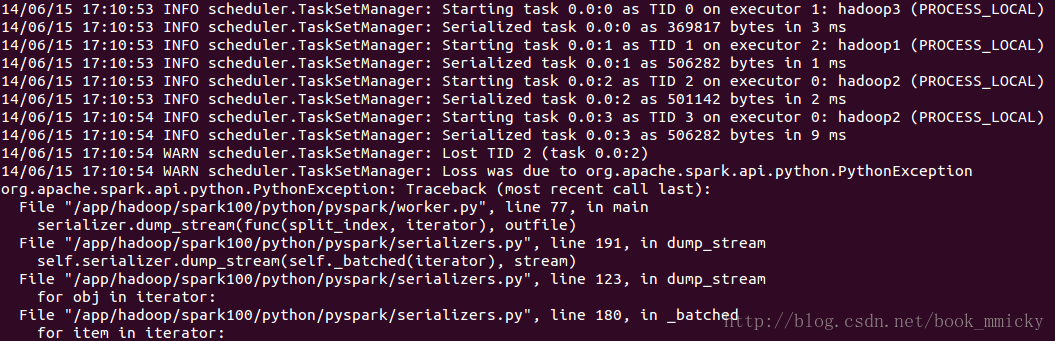
笔者使用spark-submit从客户端提交python程序给虚拟集群运行时,出现Task错误,不知是集群和客户端Python版本
不同造成的,还是其他原因造成的。等稍空的时候研究一下源码。














 3804
3804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









