







阿里巴巴的Github代码托管地址:https://github.com/alibaba
通过写这篇文章从开源中国站上面看了很多,也从那里将开源软件的基本的介绍和下载地址拷贝到了文章当中,总体给我的一个感受就是阿里的开源实在太强大了,多到需要花大量的时间去了解。今天写这篇文章主要是对阿里开源的项目比较陌生,通过本文也有了一个大体的认知。每个人每天有24小时,但是大部分时间我们并不能集中精力学习做事,而时间对于我们而言都是很宝贵的,原因就是人的精力是有限的,不能像机器一样学习和频繁地机械运动。惰性乃人之常情,如果不写此文我想我明天可能就会忘记阿里的这一堆东东,让他们掉入头脑的“黑洞”,为拯救记忆和不再留下遗憾,本文还是很必要写的。通过梳理,也大致看到了阿里发展过程中技术更新的轨迹。阿里很多的中间件和开源方案也是值得借鉴的,所以在很多时候我们不仅要低下头来做事,还要时不时地看看天空。
以下文章从开源中国汇总而来:http://www.oschina.net/project/alibaba
1.JDBC连接池、监控组件 Druid
Druid是一个JDBC组件,它包括三部分:(1) DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系;(2)DruidDataSource 高效可管理的数据库连接池;(3)SQLParser ;
Druid可以做什么?
1) 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
2) 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
3) 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
4) SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。如下是一个基于Druid内置扩展StatFilter的监控实现:

Git地址:http://git.oschina.net/wenshao/druid
2.分布式文件系统 FastDFS
FastDFS是一个开源的分布式文件系统,她对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
Github地址:https://github.com/happyfish100/fastdfs
3.通用 React 兼容渲染引擎 Rax
Rax 是阿里开源的一个通用的 JavaScript 库,主要有 React 兼容的 API 。 使用 React 的就应该已经知道如何使用 Rax。
特性:快速:快速的虚拟 DOM;微型:min + gzip 之后仅 8.0kb;通用:跨浏览器、Weex 和 Node.js。
Github地址:https://github.com/alibaba/rax
4.Java的JSON处理器 fastjson
fastjson 是一个性能很好的 Java 语言实现的 JSON 解析器和生成器,来自阿里巴巴的工程师开发。
主要特点:快速FAST (比其它任何基于Java的解析器和生成器更快,包括jackson);强大(支持普通JDK类包括任意Java Bean Class、Collection、Map、Date或enum);零依赖(没有依赖其它任何类库除了JDK)。
Git地址:https://git.oschina.net/wenshao/fastjson
5.七天学会NodeJS文档
七天学会NodeJS是阿里巴巴国际站前端技术部编写的开源文档,用于学习 Node.js。
Github地址:https://github.com/nqdeng/7-days-nodejs
6.服务框架 Dubbo
Dubbo 是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 sprig框架无缝集成。
主要核心部件:
-
Remoting: 网络通信框架,实现了 sync-over-async 和 request-response 消息机制.
-
RPC: 一个远程过程调用的抽象,支持负载均衡、容灾和集群功能
-
Registry: 服务目录框架用于服务的注册和服务事件发布和订阅
Dubbo工作原理

-
Provider
-
暴露服务方称之为“服务提供者”。
-
-
Consumer
-
调用远程服务方称之为“服务消费者”。
-
-
Registry
-
服务注册与发现的中心目录服务称之为“服务注册中心”。
-
-
Monitor
-
统计服务的调用次调和调用时间的日志服务称之为“服务监控中心”。
-
Github地址:https://github.com/alibaba/dubbo
7.开源数据库AliSQL
AliSQL是基于MySQL官方版本的一个分支,由阿里云数据库团队维护,目前也应用于阿里巴巴集团业务以及阿里云数据库服务。该版本在社区版的基础上做了大量的性能与功能的优化改进。尤其适合电商、云计算以及金融等行业环境。
阿里云数据库资深专家丁奇介绍,AliSQL版本在强度和广度上都经历了极大的考验。最新的AliSQL版本不仅从其他开源分支比如:Percona,MariaDB,WebScaleSQL等社区汲取精华,也沉淀了阿里巴巴多年在MySQL领域的经验和解决方案。AliSQL增加更多监控指标,并针对电商秒杀、物联网大数据压缩、金融数据安全等场景提供个性化的解决方案。
“在通用基准测试场景下,AliSQL版本比MySQL官方版本有着70%的性能提升。在秒杀场景下,性能提升100倍。”丁奇表示。
阿里云资深总监李津表示,“AliSQL的发展得到了众多智慧的支持。我们希望将过去几年沉淀的技术积累回馈到社区,帮助更多使用MySQL的个人和企业,这是社区良性发展的道路。我们也欢迎更多的开发者和技术团队加入AliSQL开源项目,使之在业内发挥更大的价值。”
和 Oracle 数据库的性能比较:
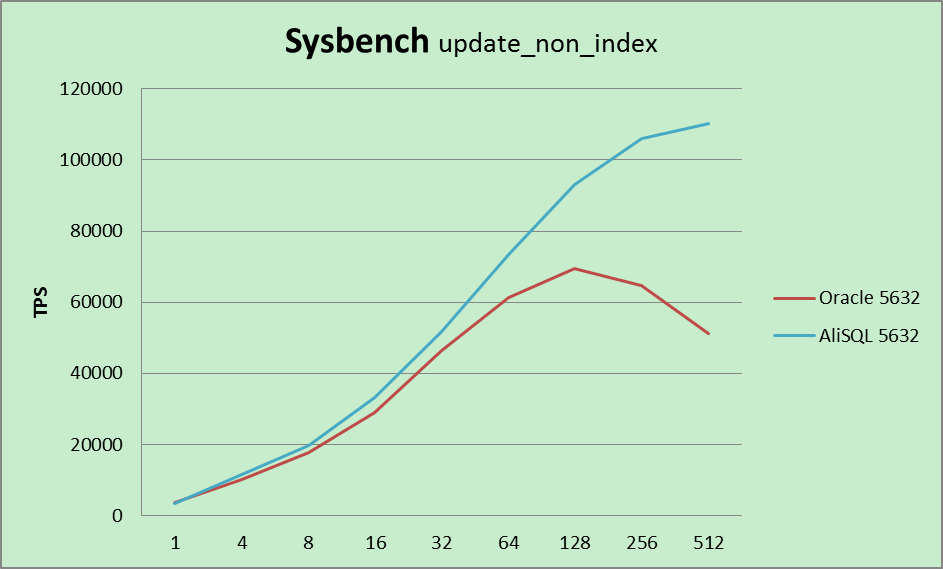
Github地址:https://github.com/alibaba/AliSQL
8.跨平台移动开发工具 Weex
2016年4月21日,阿里巴巴在Qcon大会上宣布开源跨平台移动开发工具Weex,Weex能够完美兼顾性能与动态性,让移动开发者通过简捷的前端语法写出Native级别的性能体验,并支持iOS、安卓、YunOS及Web等多端部署。
对于移动开发者来说,Weex主要解决了频繁发版和多端研发两大痛点,同时解决了前端语言性能差和显示效果受限的问题。开发者可通过Weex官网申请内测。(http://alibaba.github.io/weex/)
开发者只需要在自己的APP中嵌入Weex的SDK,就可以通过撰写HTML/CSS/JavaScript来开发Native级别的Weex界面。Weex界面的生成码其实就是一段很小的JS,可以像发布网页一样轻松部署在服务端,然后在APP中请求执行。
与现有的开源跨平台移动开放项目如Facebook的React Native和微软的Cordova相比,Weex更加轻量,体积小巧。因为基于web conponent标准,使得开发更加简洁标准,方便上手。Native组件和API都可以横向扩展,方便根据业务灵活定制。Weex渲染层具备优异的性能表现,能够跨平台实现一致的布局效果和实现。对于前端开发来说,Weex能够实现组件化开发、自动化数据绑定,并拥抱Web标准。
突出特点:
-
致力于移动端,充分调度 native 的能力
-
充分解决或回避性能瓶颈
-
灵活扩展,多端统一,优雅“降级”到 HTML5
-
保持较低的开发成本和学习成本
-
快速迭代,轻量实时发布
-
融入现有的 native 技术体系
-
工程化管理和监控等
-
轻量:体积小巧,语法简单,方便接入和上手
-
可扩展:业务方可去中心化横向定制组件和功能模块
-
高性能:高速加载、高速渲染、体验流畅
9.消息中间件 Apache RocketMQ
【Apache RocketMQ】RocketMQ捐赠给Apache那些鲜为人知的故事
Apache基金会宣布接收阿里消息中间件RocketMQ为孵化项目
RocketMQ 是一款分布式、队列模型的消息中间件,具有以下特点:
-
能够保证严格的消息顺序
-
提供丰富的消息拉取模式
-
高效的订阅者水平扩展能力
-
实时的消息订阅机制
-
亿级消息堆积能力
-
Metaq3.0 版本改名,产品名称改为RocketMQ
10.淘宝Hadoop作业平台 宙斯Zeus
宙斯是一个完整的Hadoop的作业平台。从Hadoop任务的调试运行到生产任务的周期调度 宙斯支持任务的整个生命周期。
从功能上来说,支持:
- Hadoop MapReduce任务的调试运行
- Hive任务的调试运行
- Shell任务的运行
- Hive元数据的可视化查询与数据预览
- Hadoop任务的自动调度
Github地址:https://github.com/alibaba/zeus
11.淘宝分布式数据库 OceanBase
OceanBase是一个支持海量数据的高性能分布式数据库系统,实现了数千亿条记录、数百TB数据上的跨行跨表事务,由淘宝核心系统研发部、运维、DBA、广告、应用研发等部门共同完成。在设计和实现OceanBase的时候暂时摒弃了不紧急的DBMS的功能,例如临时表,视图(view),研发团队把有限的资源集中到关键点上,当前 OceanBase主要解决数据更新一致性、高性能的跨表读事务、范围查询、join、数据全量及增量dump、批量数据导入。
目前OceanBase已经应用于淘宝收藏夹,用于存储淘宝用户收藏条目和具体的商品、店铺信息,每天支持4~5千万的更新操作。等待上线的应用还包括CTU、SNS等,每天更新超过20亿,更新数据量超过2.5TB,并会逐步在淘宝内部推广。
12.分布式key/value存储系统 Tair
Tair是由淘宝网自主开发的Key/Value结构数据存储系统,在淘宝网有着大规模的应用。您在登录淘宝、查看商品详情页面或者在淘江湖和好友“捣浆糊”的时候,都在直接或间接地和Tair交互。
Tair是一个Key/Value结构数据的解决方案,它默认支持基于内存和文件的两种存储方式,分别和我们通常所说的缓存和持久化存储对应。
Tair除了普通Key/Value系统提供的功能,比如get、put、delete以及批量接口外,还有一些附加的实用功能,使得其有更广的适用场景,包括:
-
Version支持>
-
原子计数器
-
Item支持
13.系统信息采集和监控工具 Tsar
Tsar是淘宝的采集工具,主要用来收集服务器的系统信息(如cpu,io,mem,tcp等)以及应用数据(如squid haproxy nginx等),tsar支持实时查看和历史查看,方便了解应用和服务器的信息!
它类似于sar,能监控和收集服务器和关键应用的信息,支持实时终端显示和集中式数据库存储查询,还能向Nagios发送报警信息。Tsar模块化的设计利于通过开发新模块来扩展新的功能,非常方便。
Github地址: https://github.com/alibaba/tsar14.模块加载框架 SeaJS
Sea.JS 是一个遵循 CommonJS 规范的模块加载框架,可用来轻松愉悦地加载任意 JavaScript 模块。
SeaJS 支持的标准模块遵循 Modules/Wrappings 规范的 define 形式,可运行于 Web 浏览器以及 node.JS 等环境中。
Github地址: https://github.com/seajs/seajs15.阿里巴巴分布式数据库同步系统 otter
otter 基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统。
工作原理:
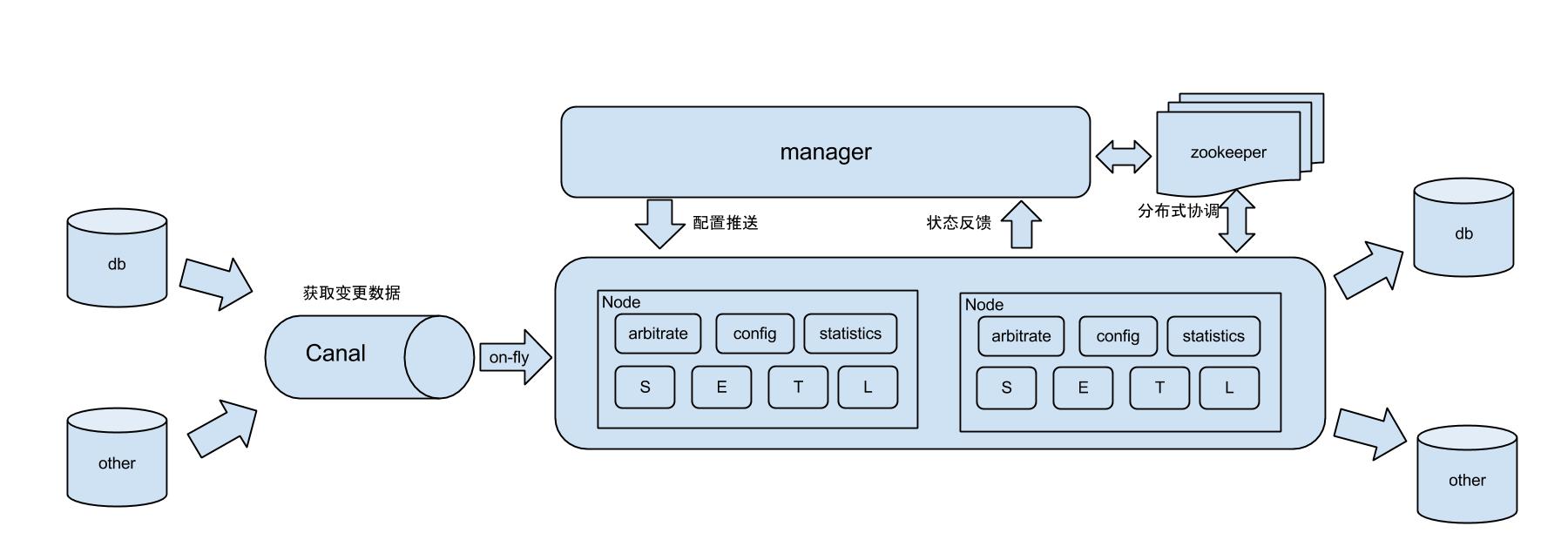
原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请点击
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
16.分布式消息中间件 Metamorphosis
Metamorphosis (MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于LinkedIn的Kafka,具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源。
总体结构:

内部结构:

主要特点:
-
生产者、服务器和消费者都可分布
-
消息存储顺序写
-
性能极高,吞吐量大
-
支持消息顺序
-
支持本地和XA事务
-
客户端pull,随机读,利用sendfile系统调用,zero-copy ,批量拉数据
-
支持消费端事务
-
支持消息广播模式
-
支持异步发送消息
-
支持http协议
-
支持消息重试和recover
-
数据迁移、扩容对用户透明
-
消费状态保存在客户端
-
支持同步和异步复制两种HA
-
支持group commit
-
更多……
17.HTML5 互动游戏引擎 Hilo
Hilo 是阿里巴巴集团开发的一款HTML5跨终端游戏解决方案,ta可以帮助开发者快速创建HTML5游戏。
主要特性
-
Hilo 支持多种模块范式的包装版本,包括AMD,CMD,COMMONJS,Standalone多种方式接入。另外,你可以根据需要新增和扩展模块和类型;
-
极精简的模块设计,完全面向对象;
-
多种渲染方式, 提供DOM,Canvas,Flash,WebGL等多种渲染方案(目前已经申请专利);
-
全端浏览器的支持和高性能方案,独有的Flash渲染方案,即使在低版本IE浏览器下也可以跑起来“酷炫”游戏; DOM渲染方案能显著解决低性能手机浏览器遇到的性能问题;
-
物理引擎支持——Chipmunk,支持自扩展物理实现;骨骼动画支持——DragonBones,同时内建骨骼动画系统——Tahiti(目前内部使用);
-
案例丰富,框架成熟,已经经历多届阿里巴巴双十一,年中大促互动营销活动考验;
18.自动化测试解决方案 Macaca
官方网站: 链接
Macaca是一套完整的自动化测试解决方案。
特性:
-
支持移动端和PC端
-
支持Native, Hybrid, H5 等多种应用类型
-
提供客户端工具和持续集成服务
客户端:
客户端工具的安装、使用详见 macaca-cli。
持续集成:
reliable 是分布式持续集成服务,可与 macaca 无缝融合。
部署和使用详见 reliable-slave,reliable-master。
Github地址: https://github.com/alibaba/macaca19.JavaScript 模板引擎 Velocity.js
Velocity.js 是velocity模板语法的javascript实现。Velocity 是基于Java的模板引擎,广泛应用在阿里集 体各个子公司。Velocity模板适用于大量模板使用的场景,支持复杂的逻辑运算,包含 基本数据类型、变量赋值和函数等功能。Velocity.js 支持 Node.js 和浏览器环境。
Features
-
支持客户端和服务器端使用
-
语法是富逻辑的,构成门微型的语言
-
语法分析和模板渲染分离
-
基本完全支持velocity语法
-
浏览器使用支持模板之间相互引用,依据kissy模块加载机制
-
三个Helper,友好的数据模拟解决方案
20.Oracle数据迁移同步工具 yugong
yugong 是阿里巴巴推出的去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS)
08年左右,阿里巴巴开始尝试MySQL的相关研究,并开发了基于MySQL分库分表技术的相关产品,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机Oracle无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上,完成去IOE的第一步.
整个数据迁移过程,分为两部分:
-
全量迁移
-
增量迁移

过程描述:
-
增量数据收集 (创建oracle表的增量物化视图)
-
进行全量复制
-
进行增量复制 (可并行进行数据校验)
-
原库停写,切到新库
架构

说明:
-
一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
-
instance分为三部分
a. extractor (从源数据库上提取数据,可分为全量/增量实现)
b. translator (将源库上的数据按照目标库的需求进行自定义转化)
c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)
21.企业级流式计算引擎 JStorm
JStorm 是参考 Apache Storm 实现的实时流式计算框架,在网络IO、线程模型、资源调度、可用性及稳定性上做了持续改进,已被越来越多企业使用。JStorm 可以看作是 storm 的java增强版本,除了内核用纯java实现外,还包括了thrift、python、facet ui。从架构上看,其本质是一个基于zk的分布式调度系统
JStorm 的性能是Apache Storm 的4倍, 可以自由切换行模式或 mini-batch 模式:


Github地址:https://github.com/alibaba/jstorm
22.非侵入式运行期 AOP 框架 Dexposed
Dexposed 是阿里巴巴无线事业部第一个重量级 Andorid 开源软件,基于 ROOT 社区著名开源项目 Xposed 改造剥离了 ROOT 部分,演化为服务于所在应用自身的 AOP 框架。它支撑了阿里大部分 App 的在线分钟级客户端 bugfix 和线上调试能力。
Dexposed 的 AOP 是实现了纯非侵入式,没有任何注释处理器,weaver 或者字节码重写程序。Dexposed 的集成非常简单,就像加载一个 JNI 库一样,只需要在初始化的时候插入一行代码。
经典用例
-
典型的 AOP 编程
-
仪表化 (测试,性能监控等等)
-
在线热修复(重要,关键,安全漏洞等等)
-
SDK hooking,更好的开发体验
23.自动化测试解决方案 UI Recorder
UI Recorder是一款零成本的整体自动化测试解决方案,一次自测等于多次测试,测一个浏览器等于测多个浏览器!
以下是本产品的特点:
-
自测 = 自动化测试:对于开发人员来讲,自测是开发流程中缺一不可的过程,我们要实现的目标就是自测过程中即可同步的录制出自动化脚本,实现真正的零成本自动化
-
无干扰录制:所作操作均无需交互干扰,鼠标、键盘、alert弹框、文件上传,完全按照正常自测流程操作即可(以下操作除外:悬停事件、断言、变量)
-
本地生成脚本:录制的脚本存储在用户本机,用户可以自行在录制的基础上进行修改定制,更自由更开放
-
丰富的断言:支持以下断言类型,val、text、displayed、enabled、selected、attr、css、url、title、cookie、localStorage、sessionStorage
-
支持数据Mock:我们支持Faker变量功能,支持强大的数据Mock
-
支持公共用例: 用例之间允许相互引用,可以将某些公用的操作步骤录制为公用用例,以进一步提升录制效率
-
支持执行截图:每次执行后,允许生成截图日志,以方便出问题时排查诊断
Github地址:https://github.com/alibaba/uirecorder
24.Android 应用热修复工具 AndFix
AndFix 是阿里巴巴开源的 Android 应用热修复工具,帮助 Anroid 开发者修复应用的线上问题。Andfix 是 "Android hot-fix" 的缩写。
AndFix 支持 Android 2.3 - 6.0,ARM 和 x86 架构,dalvik 运行时和 art 运行时。AndFix 的分支是 .apatch 文件。
AndFix 方法体取代实现规则:
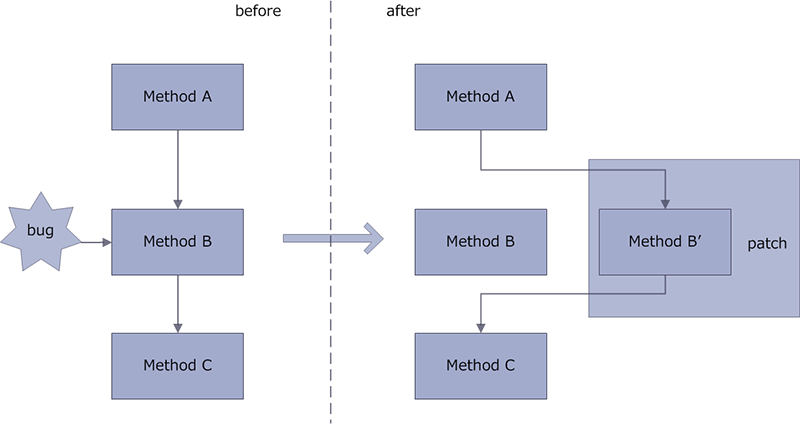
Bug 修复过程:
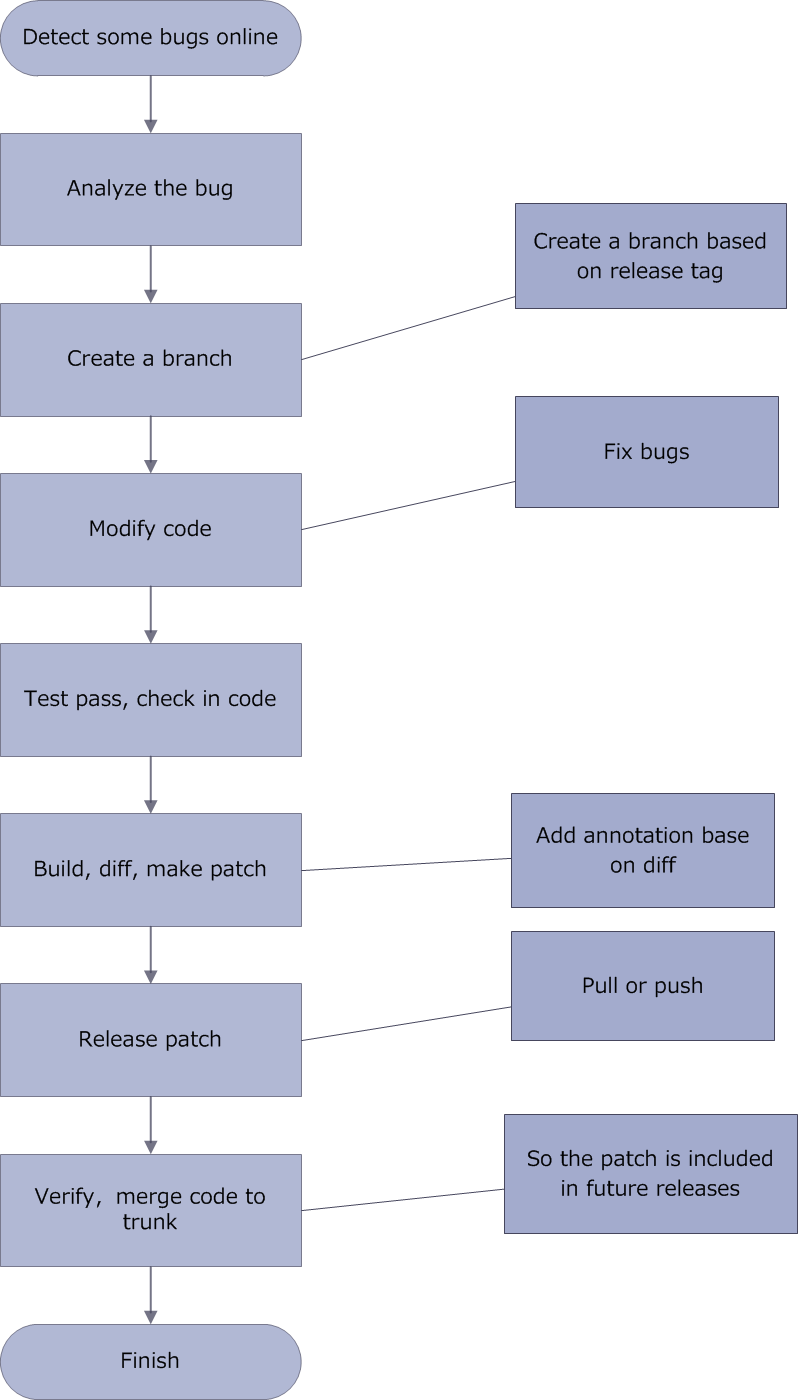
Gitbub地址:https://github.com/alibaba/AndFix
25.设计语言&前端框架 Ant Design
Ant Design 是蚂蚁金服开发和正在使用的一套企业级的前端设计语言和基于 React 的前端框架实现。

特性
-
企业级金融产品的交互语言和视觉体系。
-
丰富实用的 React UI 组件。
-
基于 React 的组件化开发模式。
-
背靠 npm 生态圈。
-
基于 webpack 的调试构建方案,支持 ES6。
26.分布式SQL引擎 Lealone
Lealone 为 HBase 提供一个分布式SQL引擎,尝试将BigTable(HBase)和 RDBMS (H2数据库) 结合的项目。
Lealone 发音 ['li:ləʊn] 这是我新造的英文单词,灵感来自于在淘宝工作期间办公桌上那些叫绿萝的室内植物,一直想做个项目以它命名。 绿萝的拼音是lv luo,与Lealone英文发音有点相同, Lealone是lea + lone的组合(lea 草地/草原, lone 孤独的),也算是现在的心境:思路辽阔但又孤独。 反过来念更有意思。
应用场景:
-
使用Lealone的分布式SQL引擎,可使用类似MySQL的SQL语法和标准JDBC API读写HBase中的数据, 支持各种DDL,支持触发器、自定义函数、视图、Join、子查询、Order By、Group By、聚合。
-
对于Client/Server架构的传统单机RDBMS的场景,也可使用Lealone。
-
如果应用想不经过网络直接读写数据库,可使用嵌入式Lealone。
27.淘宝 React 框架 React Web
淘宝前端团队开源项目React Web,通过与React Native一致的API构建Web应用。

Github:https://github.com/taobaofed/react-web
28.基于 Node.js 的自动化持续集成 Reliable
Reliable 是分布式架构的持续集成系统,由Macaca 团队的成员开发。适用于集成构建、集成构建等场景。她是典型的主从结构,分为reliable-master 与 reliable-slave 两部分。
特点:
-
集群负载,合理调配
-
提供插件机制,易扩展
-
部署非常简单
-
便于接入 Gitlab、Github 等社区化系统
同时,她与 Macaca 无缝融合。
使用 Macaca + Reliable 为自己的团队和公司搭建一个开源的自动化集成平台是个不错的选择。
Github地址: https://github.com/reliablejs/reliable-master29.Java APNS Apple Push Notification Service开源库 apns4j
apns4j 是 Apple Push Notification Service 的 Java 实现!
Github地址:https://github.com/teaey/apns4j
30.Linux 内核的阿里巴巴分支 Ali-Kernel
Alibaba Kernel起源于亚洲最大的电子商务网站——阿里巴巴。它基于 RHEL6 源代码,包含了阿里巴巴所需的一些更新和新功能。更多的信息和文档,请参阅http://kernel.taobao.org
特征:
-
rhel6u2内核的所有功能,源代码版本是 2.6.32-220.23.1.
-
netoops使你能够从panic server收集数据, https://lwn.net/Articles/414031/.
-
支持ext4的bigalloc和内联数据. https://lwn.net/Articles/469805/
-
overlayfs能够在一个fs上部署另一个fs. 请参阅 http://lwn.net/Articles/447650/.
-
支持嵌入式缓存.
-
支持用于容器的中央处理器的计算.
-
dio 覆盖后面加上的快速 SSDs 的支持.
-
完善 JIT 使你能够跟踪一个java程序的性能.
-
使内存管理策略有所不同.
Github地址:https://github.com/alibaba/ali_kernel
31.淘宝Web服务器 Tengine
Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性。Tengine的性能和稳定性已经在大型的网站如淘宝网,天猫商城等得到了很好的检验。它的最终目标是打造一个高效、稳定、安全、易用的Web平台。
从2011年12月开始,Tengine成为一个开源项目,Tengine团队在积极地开发和维护着它。Tengine团队的核心成员来自于淘宝、搜狗等互联网企业。Tengine是社区合作的成果,我们欢迎大家参与其中,贡献自己的力量。
以下沿引项目主页上的特性介绍:
-
继承Nginx-1.2.8的所有特性,100%兼容Nginx的配置;
-
动态模块加载(DSO)支持。加入一个模块不再需要重新编译整个Tengine;
-
更多负载均衡算法支持。如会话保持,一致性hash等;
-
输入过滤器机制支持。通过使用这种机制Web应用防火墙的编写更为方便;
-
动态脚本语言Lua支持。扩展功能非常高效简单;
-
支持管道(pipe)和syslog(本地和远端)形式的日志以及日志抽样;
-
组合多个CSS、JavaScript文件的访问请求变成一个请求;
-
可以对后端的服务器进行主动健康检查,根据服务器状态自动上线下线;
-
自动根据CPU数目设置进程个数和绑定CPU亲缘性;
-
监控系统的负载和资源占用从而对系统进行保护;
-
显示对运维人员更友好的出错信息,便于定位出错机器;
-
更强大的防攻击(访问速度限制)模块;
-
更方便的命令行参数,如列出编译的模块列表、支持的指令等;
-
可以根据访问文件类型设置过期时间;
32.Web常用UI库 kissy
issy 是淘宝一个开源的 JavaScript 库,包含的组件有:日历、图片放大镜、卡片切换、弹出窗口、输入建议等

愿景:小巧灵活,简洁实用,使用起来让人感觉愉悦。
支持的浏览器:IE 6+, Firefox 3.5+, Safari 4+, Chrome 2+, Opera 10+
Github地址: https://github.com/kissyteam/kissy33.Bug管理系统 BugFree-禅道

34.Nginx开发从入门到精通
nginx由于出色的性能,在世界范围内受到了越来越多人的关注,在淘宝内部它更是被广泛的使用,众多的开发以及运维同学都迫切的想要了解nginx模块的开发以及它的内部原理,但是国内却没有一本关于这方面的书,源于此我们决定自己来写一本。本书的作者为淘宝核心系统服务器平台组的成员,本书写作的思路是从模块开发逐渐过渡到nginx原理剖析。书籍的内容会定期在这里更新,欢迎大家提出宝贵意见,不管是本书的内容问题,还是字词错误,都欢迎大家提交issue(章节标题的左侧有评注按钮),我们会及时的跟进。
Github地址:https://github.com/taobao/nginx-book
35.分布式数据层 TDDL
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):

淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作 一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是 分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能 够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一 个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
下图展示了一个简单的分库分表数据查询策略:
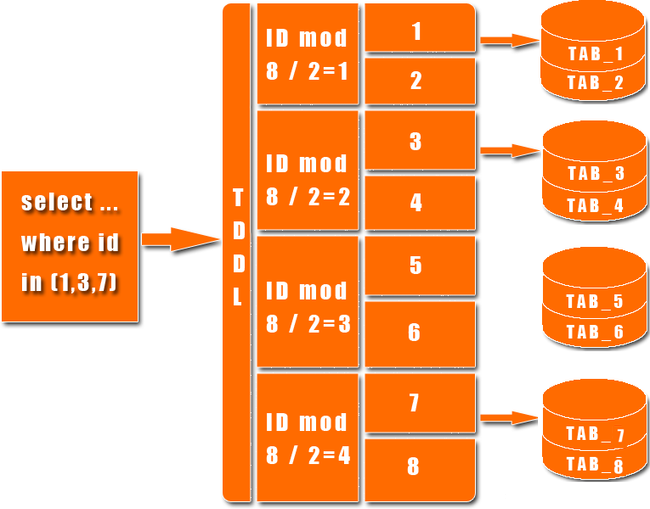
主要优点:
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
36.分布式文件系统TFS
TFS(Taobao FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,其设计目标是支持海量的非结构化数据。
目前,国内自主研发的文件系统可谓凤毛麟角。淘宝在这一领域做了有效的探索和实践,Taobao File System(TFS)作为淘宝内部使用的分布式文件系统,针对海量小文件的随机读写访问性能做了特殊优化,承载着淘宝主站所有图片、商品描述等数据存储。
文章首先概括了TFS的特点:最近,淘宝核心系统团队工程师楚材(李震)在其官方博客上撰文(《TFS简介》,以下简称文章)简要介绍了TFS系统的基本情况,引起了社区的关注。
完全扁平化的数据组织结构,抛弃了传统文件系统的目录结构。
在块设备基础上建立自有的文件系统,减少EXT3等文件系统数据碎片带来的性能损耗。
单进程管理单块磁盘的方式,摒除RAID5机制。
带有HA机制的中央控制节点,在安全稳定和性能复杂度之间取得平衡。
尽量缩减元数据大小,将元数据全部加载入内存,提升访问速度。
跨机架和IDC的负载均衡和冗余安全策略。
完全平滑扩容。
当前,TFS在淘宝的应用规模达到“数百台PCServer,PB级数据量,百亿数据级别”,对于其性能参数,楚材透漏:
TFS在淘宝的部署环境中前端有两层缓冲,到达TFS系统的请求非常离散,所以TFS内部是没有任何数据的内存缓冲的,包括传统文件系统的内存缓冲也不存在......基本上我们可以达到单块磁盘随机IOPS(即I/O per second)理论最大值的60%左右,整机的输出随盘数增加而线性增加。
TFS的逻辑架构图1如下所示:

图1. TFS逻辑架构图(来源:淘宝核心系统团队博客)
楚材结合架构图做了进一步说明:
-
TFS尚未对最终用户提供传统文件系统API,需要通过TFSClient进行接口访问,现有JAVA、JNI、C、PHP的客户端
-
TFS的NameServer作为中心控制节点,监控所有数据节点的运行状况,负责读写调度的负载均衡,同时管理一级元数据用来帮助客户端定位需要访问的数据节点
-
TFS的DataServer作为数据节点,负责数据实际发生的负载均衡和数据冗余,同时管理二级元数据帮助客户端获取真实的业务数据。
37.http压力测试工具 httpsender
httpsender是一款轻量级的http压力测试工具,由淘宝的测试工程师用Java语言开发完成。它可以指定并发连接数发送指定数目的请求,还可以自定义请求的header头。请求的URL支持通过正则表达式指定范围,同时也支持从文件随机或顺序读取。它还具备验证数据是否完整和错乱等较高级的功能。默认应用环境为Linux。
下载地址:
http://dl.dbank.com/c0vxx27aa5
38.轻量级分布式数据访问层 CobarClient
Cobar Client是一个轻量级分布式数据访问层(DAL)基于iBatis(已更名为MyBatis)和Spring框架实现。

主要特性:
-
可以支持垂直和水平数据切分数据库集群的访问;
-
支持双机热备的HA解决方案, 应用方可以根据情况选用数据库特定的HA解决方案(比如Oracle的RAC),或者选用CobarClient提供的HA解决方案.
-
小数据量的数据集计(Aggregation), 暂时只支持简单的数据合并.
-
数据库本地事务的支持, 目前采用Best Efforts 1PC模式的事务管理.
-
数据访问操作相关SQL的记录, 分析等.(可以采用国际站现有Ark解决方案,但CobarClient提供扩展的切入接口)
39.淘蝌蚪开源平台 taocode
![]()
taocode(淘蝌蚪)是淘宝网推出的开源平台。平台本身也是开源的。
TaoCode的定位:大的方面来说,是平台+社区
1).平台化
a) 完善项目管理过程工具平台
b) 提供更多代码级工具
c) 提供更多文档化工具
2).社区化
a). 提供更好的交流平台
b). 增加更多的持续性生态化平台功能
40.关系型数据的分布式处理系统 Cobar
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下像传统数据库一样为您提供海量数据服务。以下是快速启动场景:
-
系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
-
tb1表的数据被映射到物理数据库dbtest1的tb1上。
-
tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
如下图所示:

产品约束
-
使用JDBC时,推荐使用5.1以上版本Driver进行连接
-
不支持跨库的关联操作:join、分页、排序、子查询。
-
不支持rewriteBatchedStatements=true参数设置。默认为false
-
不支持useServerPrepStmts=true参数设置。默认为false
-
BLOB, BINARY, VARBINARY字段不能使用。若特殊需求需要这三种字段,禁止使用PreparedStatement的setBlob()或setBinaryStream()方法设置参数。
-
不支持SAVEPOINT操作。
-
不支持SET语句的执行,事务和字符集设置语句除外
-
对于拆分表(一个表的数据被映射到多个MySQL数据库),不能更新已有记录的拆分字段(分库字段)值
-
只支持MySQL数据节点。
-
对于拆分表,插入操作须给出列名,必须包含拆分字段。
41.异步任务处理系统TBSchedule
由原来的项目taobao-pamirs-schedule 更名为 TBSchedule
Console Demo地址: www.tbschedule.com
Console下载: trunk/console/ScheduleConsole.war
技术支持: 忌少 jishao@taobao.com
推荐项目: QLExpress 简介高效的脚本引擎
pom引用:
com.taobao.pamirs.schedule
tbschedule
3.2.10对于互联网和电子商务领域而言,由于存在大数据、高并发的特点,相对比较消耗时间的业务逻辑都会从用户行为中被剥离开来进行异步处理,一来可以提高用户体验,二来也可以增大系统的可扩转性,因此得到大量的应用了。由于业务的需要我们选择了淘宝p9的架构师玄难大师写的tbschedule来作为我们的异步任务处理系统,至今有接近一年的运维与使用实践,由于最近有业务需要一个任务分配系统,直接使用tbschedule是不满足要求的,在考虑具体实现的时候决定再次通读一次tbschedule的源代码,在对tbschedule的源代码又再次研读一番之后有了一些新的认识和思考。
tbschedule具有如下特性:
1、tbschedule的目的是让一种批量任务或者不断变化的任务,能够被动态的分配到多个主机的JVM中,不同的线程组中并行执行。所有的任务能够被不重复,不遗漏的快速处理。
2、调度的Manager可以动态的随意增加和停止。
3、可以通过JMX控制调度服务的创建和停止。
4、可以指定调度的时间区间。
42.模拟数据生成器 Mock.js
Mock.js 是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试。提供了以下模拟功能:
-
根据数据模板生成模拟数据
-
模拟 Ajax 请求,生成并返回模拟数据
-
基于 HTML 模板生成模拟数据
Github地址:https://github.com/nuysoft/Mock
43.在线分析查询系统 mdrill
1:mdrill是阿里妈妈-adhoc-海量数据多维自助即席查询平台下的一个子项目。
2:mdrill旨在帮助用户在几秒到几十秒的时间内,分析百亿级别的任意维度组合的数据。
3:mdrill是一个分布式的在线分析查询系统,基于hadoop,lucene,solr,jstorm等开源系统作为实现,基于SQL的查询语法。 mdrill是一个能够对大量数据进行分布式处理的软件框架。mdrill是快速的高性能的,他的底层因使用了索引、列式存储、以及内存cache等技 术,使得数据扫描的速度大为增加。mdrill是分布式的,它以并行的方式工作,通过并行处理加快处理速度。
4:mdrill在adhoc项目中,mdrill使用了10台机器,存储了400亿的数据,每次扫描30亿的行数,响应时间在20秒~120秒左右(取决不同的查询条件)。
据越来越多,传统的关系型数据库支撑不了,分布式数据仓库又非常贵。几十亿、几百亿、甚至几千亿的数据量,如何才能高效的分析?
mdrill是由阿里妈妈开源的一套数据的软件,针对TB级数据量,能够仅用10台机器,达到秒级响应,数据能实时导入,可以对任意的维度进行组合与过滤。
mdrill作为数据在线分析处理软件,可以在几秒到几十秒的时间,分析百亿级别的任意组合维度的数据。
在阿里10台机器完成每日30亿的数据存储,其中10亿为实时的数据导入,20亿为离线导入。目前集群的总存储1000多亿80~400维度的数据。
特性如下:
1.满足大数据查询需求:adhoc每天的数据量为30亿条,随着日积月累,数据会越来越大,mdrill采用列存储,索引,分布式技术,适当的分区等满足用户对数据的实时在线分析的需求。
2.支持增量更新:离线形式的mdrill数据支持按照分区方式的增量更新。
3.支持实时数据导入:在仅有10台机器的情况下,支持每天10亿级别(高峰每小时2亿)的实时导入。
4.响应时间快:列存储、倒排索引、高效的数据压缩、内存计算,各种缓存、分区、分布式处理等等这些技术,使得mdrill可以仅在几秒到几十秒的时间分析百亿级别的数据。
5.低成本:目前在阿里adhoc仅仅使用10台48G内存的PC机,但确存储了超过千亿规模的数据。
6.全文检索模式:强大的条件设置,任意组合,无论难易秒级预览,每天160亿的数据随意筛选。
Github地址:https://github.com/alibaba/mdrill
44.淘宝定制JVM TaobaoJVM
淘宝有几万台Java应用服务器,上千名Java工程师、及上百个Java应用。为此,核心系统研发部专用计算组的工作之一是专注于OpenJDK的优化及定制,根据业务、应用特点及开发者需要,提供稳定,高效和深度定制的JVM版本:Taobao JVM。
TaobaoJVM 基于 OpenJDK HotSpot VM,是国内第一个优化、定制且开源的服务器版Java虚拟机。目前已经在淘宝、天猫上线,全部替换了Oracle官方JVM版本,在性能,功能上都初步体现了它的价值。
开放是淘宝的重要基因之一,在服务于淘宝的同时,我们非常愿意将我们的工作成果分享给所有Java技术的应用方,希望共同交流,学习,进步,持续为JVM发展和社区的繁荣做出贡献。
专用计算组职责:
-
针对特定领域问题,以计算性能、效能为导向的优化。
-
异构计算推广及实践。
-
JVM优化、定制及相关工具开发。JVM相关故障,问题排查及解决。
-
协助优化特定应用。
45.Java 图片处理类库 SimpleImage-图片水印、缩略图
SimpleImage是阿里巴巴的一个Java图片处理的类库,可以实现图片缩略、水印等处理。
SimpleImage中的ImageRender是图片处理的基类,它是一个抽象类,我们看到,该类中定义了一个抽象方法render(),同时持有一个对ImageRender类的引用。
ReadRedner可以理解成一个组件,不是一个装饰者,因为ReadRender是所有渲染操作的第一步。
其他的子类DrawTextRender(水印处理),ScaleRender(缩略处理),WriterRender(输出)都是装饰者。
Github地址: https://github.com/alibaba/simpleimage46.php图片裁剪 Tclip 终于有美女可看了放松一下
名字说明:
T,头像之意。
clip,读[klip],译为裁剪。
Tclip,是一个头像自动识别,php图片裁剪项目。
概要:
用于图片裁剪。有以下特点:
1.能进行人脸识别。图片中有人脸,将自动视为人脸区域为重要区域,将不会被裁剪掉。
2.自动识别其它重要区域。如果图片中未识别出人脸,则会根据特征分布计算出重区域。
总而言之,自动识别图片中的重要区域,并且在图片裁剪时保留重要区域。
可以在php图片裁剪中使用,也提供了命令行方式进行图片裁剪。
目前已经用于一淘玩客 http://wanke.etao.com 进行php图片裁剪。
效果演示:
原图:

如果按照从中间截取为 400 * 225 大小大图片。效果如下:

使用tclip裁剪图片效果如下:
 原图:
原图:

如果按照从中间截取,效果如下:

在php中使用裁剪图片效果如下:

php图片裁剪在线演示 http://demo.bo56.com/tclip
安装步骤:
源码下载
opencv2 下载地址 http://www.bo56.com/tclip人脸识别图片裁剪/ (建议opencv2.4.4版本)
安装opencv2
此扩展依赖于opencv2.0 之上版本。因此安装前先安装opencv。opencv的安装步骤如下
-
yum install gtk+ gtk+-devel pkgconfig libpng zlib libjpeg libtiff cmake
-
下载 opencv2 安装包
-
解压安装包
-
cd 进入安装包文件夹内。
-
cmake CMakeLists.txt
-
make && make install
-
vim /etc/profile
-
在 unset i 前增加
-
export PKG_CONFIG_PATH=/usr/lib/pkgconfig/:/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
-
保持退出后,执行如下命令
-
source /etc/profile
-
echo "/usr/local/lib/" > /etc/ld.so.conf.d/opencv.conf
-
ldconfig
安装php图片裁剪tclip扩展
-
cd 到源代码目录中的php_ext文件夹
-
phpize
-
./configure
-
make
-
cp modules/tclip.so 到 extension 目录
-
修改php.ini。加入 extension=tclip.so
-
重启fpm
安装命令行
如果想使用命令行方式,可以进行如下安装
-
cd 进入安装包soft文件夹内
-
chmod +x ./tclip.sh
-
./tclip.sh
使用方法说明
第一种:在php中图片裁剪使用格式:
tclip(文件原路径,裁剪后的图片保存路径,裁剪后的图片宽度,裁剪后的图片高度)
示例:
$source_file = "/tmp/a.jpg";
$dest_file = "/www/a_dest.jpg";
$width = 400;
$height = 200;
tclip($source_file, $dest_file, $width, $height);
第二种:命令行
参数说明:
-s 原图路径
-d 裁剪后的图片保存路径
-w 裁剪后的图片宽度
-h 裁剪后的图片高度
./tclip -s a.jpg -d a_dest.jpg -w 400 -h 200
47.自动化测试任务调度平台 TOAST
TOAST(Toast Open Automation System for Test) 是一淘广告技术测试团队开发的一套自动化测试任务调度平台。

软件版本:v1.0 beta
支持系统:32/64位 Linux
Agent支持系统:32/64位 Win/Linux
自动化任务调度
TOAST提供一套通用的自动化任务调度平台,支持任务的串/并行运行,并且能够收集、分析和统计运行结果。
自动化测试用例管理
TOAST提供了简单的测试用例管理,通过自动化任务运行结果映射,实现测试用例和用例运行结果的关联。同时也可以通过API实现用例和结果的录入。
测试环境管理
TOAST提供了简单的机器监控和管理功能,通过TOAST Agent能够监控机器的CPU、内存、I/O、网络及应用的实时状态,兼容Window和Linux操作系统。
48.redis的java客户端 Tedis
Tedis是另一个redis的java客户端,Tedis的目标是打造一个可在生产环境直接使用的高可用Redis解决方案。
特性:
-
高可用,Tedis使用多写随机读做HA确保redis的高可用
-
高性能,使用特殊的线程模型,使redis的性能不限制在客户端
-
多种使用方式,如果你只有一个redis实例,并不需要tedis的HA功能,可以直接使用tedis-atomic;使用tedis的高可用功能需要部署多个redis实例使用tedis-group
-
两种API,包括针对byte的底层api和面向object的高层api
-
多种方便使用redis的工具集合,包括mysql数据同步到redis工具,利用redis做搜索工具等
示例代码:
Group tedisGroup = new TedisGroup(appName, version);
tedisGroup.init();
ValueCommands valueCommands = new DefaultValueCommands(tedisGroup.getTedis());
// 写入一条数据
valueCommands.set(1, "test", "test value object");
// 读取一条数据
valueCommands.get(1, "test");Github地址: https://github.com/justified/tedis
49.分布式关系数据库 Alibaba Wasp
Wasp 是类Google MegaStore & F1的分布式关系数据库。
最近几年随之Bigtable和NoSQL的兴起,社区产品HBase逐步走向NoSQL系统的主流产品,优势明显然而缺点也明显,大数据平台下的业务由 SQL向NoSQL的迁移比较复杂而应用人员学习成本颇高,并且无法支持事务和多维索引,使得许多业务无法享用来自NoSQL系统中线性拓展能力。 Google内部MegaStore就作为Bigtable的一个补充而出现,在Bigtable的上层支持了SQL,事务、索引、跨机房灾备,并成为大 名鼎鼎的Gmail、APPEngine、Android Market的底层存储。近期Google在MegaStore的基础上升级了F1的系统,因此我们决定以MegaStore&F1为理论模型进 行探索如何在HBase系统上不牺牲线性拓展能力的同时又能提供跨行事务、索引、SQL的功能。通过简单的用户入口SQL,用户可以不需要关注hbase 的schema设计,极大的简化了用户的数据迁移和学习成本。理论设计详情见MegaStore及F1。
Wasp是分布式的、支持SQL的、事务型数据库:
-
支持索引类型:本地索引、全局索引
-
支持分区(分区可再分区、合并、移动部署),可线性拓展
-
支持数据类型:int64、int32、string、double、float、datetime
-
SQL语法特性:select、update、delete、insert、create table、delete table、create index、drop index等
-
支持跨行事务,支持NoSQl之上的索引与实体的ACID
-
支持MVCC
-
JDBC访问接口
-
易用的监控:Ganglia - metrics
-
SQL分析性统计型函数
-
资源隔离
-
权限
50.dubbo 的 spring boot 自动配置 spring-boot-starter-dubbo
spring-boot-starter-dubbo是 dubbo 的 spring boot starter,它可以无缝地对接 spring boot和dubbo ,方便大家使用 dubbo 组件。
spring-boot-starter-dubbo 支持的 jdk 版本为 1.6 或者 1.6+。
spring-boot-starter-dubbo 很简单,也很方便使用,它同时集成了dubbo 的 provider 和 consumer 的功能。
-
当在 provider 端使用 spring-boot-starter-dubbo 时,可以选择不用 web 容器或者使用 web 容器;当不用 web 容器时,它作为 dubbo 的 provider 会提供简单的 RPC 服务;而当使用 web 容器时,它在提供 RPC 服务的同时,还会提供服务的上下线功能。
-
当在 consumer 端使用 spring-boot-starter-dubbo 时,需要使用 web 容器,它会提供 health监控,但是不会提供服务的上下线功能了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









