







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
-XX:MaxMetaspaceSize=512m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=100
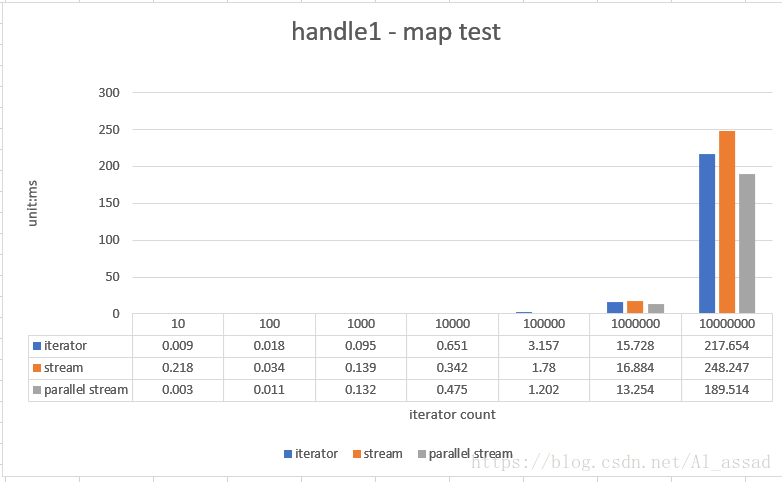
1. 映射处理测试
把一个随机数列(List<Integer>)中的每一个元素自增1后,重新组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>();
for(Integer e : list){
result.add(++e);
}
//parallel stream
List result = list.parallelStream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
2. 过滤处理测试
取出一个随机数列(List<Integer>)中的大于 200 的元素,并组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>(list.size());
for(Integer e : list){
if(e > 200){
result.add(e);
}
}
//parallel stream
List result = list.parallelStream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));

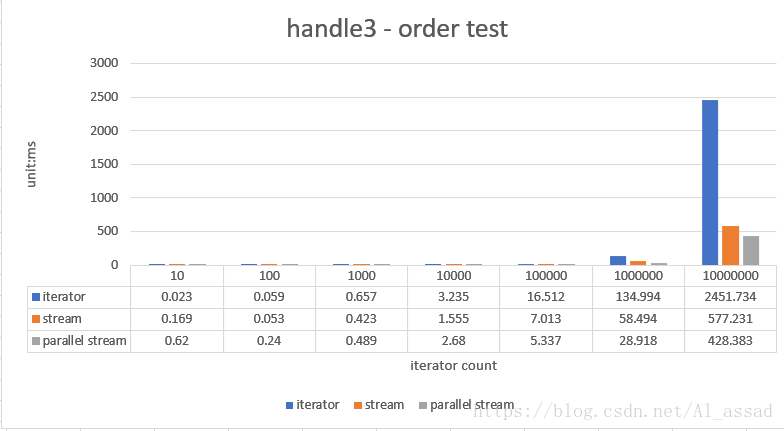
3. 自然排序测试
对一个随机数列(List<Integer>)进行自然排序,并组装为一个新的 List<Integer>,iterator 使用的是 Collections # sort API(使用归并排序算法实现),测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List result = new ArrayList<>(list);
Collections.sort(result);
//parallel stream
List result = list.parallelStream()
.mapToInt(x->x)
.sorted()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
4. 归约统计测试
获取一个随机数列(List<Integer>)的最大值,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
int max = list.stream()
.mapToInt(x -> x)
.max()
.getAsInt();
//iterator
int max = -1;
for(Integer e : list){
if(e > max){
max = e;
}
}
//parallel stream
int max = list.parallelStream()
.mapToInt(x -> x)
.max()
.getAsInt();

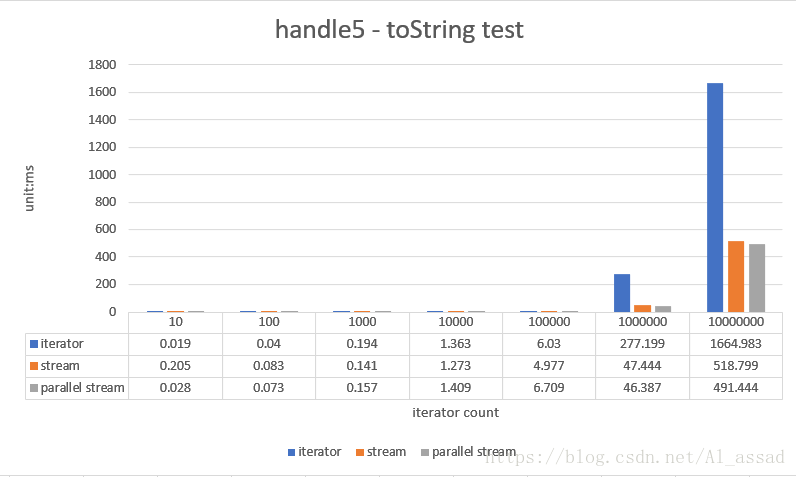
5. 字符串拼接测试
获取一个随机数列(List<Integer>)各个元素使用“,”分隔的字符串,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(“,”));
//iterator
StringBuilder builder = new StringBuilder();
for(Integer e : list){
builder.append(e).append(“,”);
}
String result = builder.length() == 0 ? “” : builder.substring(0,builder.length() - 1);
//parallel stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(“,”));
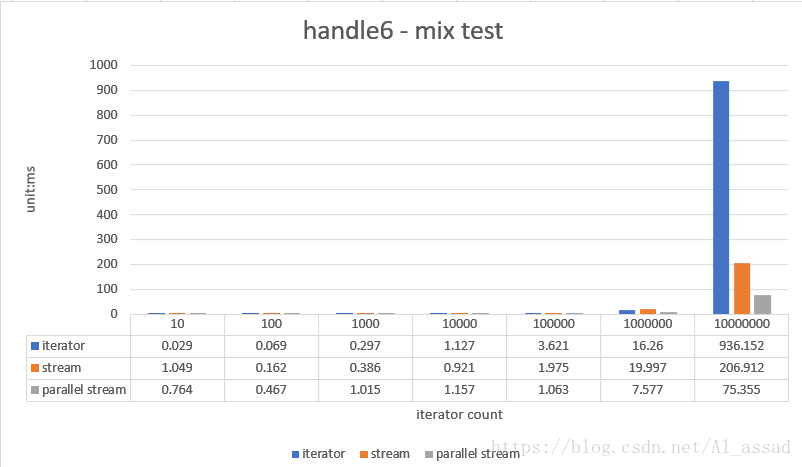
6. 混合操作测试
对一个随机数列(List<Integer>)进行去空值,除重,映射,过滤,并组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
//stream
List result = list.stream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
HashSet set = new HashSet<>(list.size());
for(Integer e : list){
if(e != null && e > 200){
set.add(e + 1);
}
}
List result = new ArrayList<>(set);
//parallel stream
List result = list.parallelStream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
实验结果总结
从以上的实验来看,可以总结处以下几点:
-
在少低数据量的处理场景中(size<=1000),stream 的处理效率是不如传统的 iterator 外部迭代器处理速度快的,但是实际上这些处理任务本身运行时间都低于毫秒,这点效率的差距对普通业务几乎没有影响,反而 stream 可以使得代码更加简洁;
-
在大数据量(szie>10000)时,stream 的处理效率会高于 iterator,特别是使用了并行流,在cpu恰好将线程分配到多个核心的条件下(当然parallel stream 底层使用的是 JVM 的 ForkJoinPool,这东西分配线程本身就很玄学),可以达到一个很高的运行效率,然而实际普通业务一般不会有需要迭代高于10000次的计算;
-
Parallel Stream 受引 CPU 环境影响很大,当没分配到多个cpu核心时,加上引用 forkJoinPool 的开销,运行效率可能还不如普通的 Stream;
使用 Stream 的建议
- 简单的迭代逻辑,可以直接使用 iterator,对于有多步处理的迭代逻辑,可以使用 stream,损失一点几乎没有的效率,换来代码的高可读性是值得的;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
不如普通的 Stream;
使用 Stream 的建议
- 简单的迭代逻辑,可以直接使用 iterator,对于有多步处理的迭代逻辑,可以使用 stream,损失一点几乎没有的效率,换来代码的高可读性是值得的;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-APRqZT75-1713300279022)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2301
2301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









