







一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
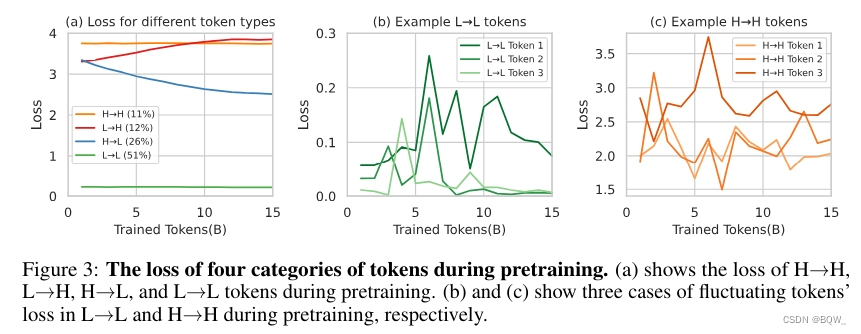
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个checkpoint。对于每个checkpoint都评估token级别的loss。通过分析token级别loss,发现token的损失值有4种模式:持续高损失值(H->H)、损失值增加(L->H)、损失值下降(H->L)、持续低损失值(L->L)。其中,H->L的token占26%;L->L的token占51%;H->H的token占11%;L->H的token占12%。L->L和H->H的token损失值在训练中方差高,可视化后发现其中包含很多噪音。
综上,训练过程中token的损失值并不像总体损失值那边平滑减少,token损失值之间存在复杂动态。因此,训练过程中选择合适的token,可以稳定训练并提高训练效率。
2. 选择性语言建模
整体思路:a. 在高质量数据上训练reference模型;b. 使用该模型对预训练的token评估损失值;c. 选择性训练语言模型,专注在训练模型和reference模型之间高损失值的token。
reference建模。使用高质量数据训练reference模型(RM),训练方式采用标准的交叉熵。token x i x_i xi的损失值计算为:
L ref ( x i ) = − log P ( x i ∣ x < i ) \mathcal{L}_{\text{ref}}(x_i)=-\log P(x_i|x_{<i}) \\ Lref(xi)=−logP(xi∣x<i)
通过损失值可以使语言模型专注在更具影响力的token上。
选择性预训练。自回归语言模型训练的损失函数为:
L CLM ( θ ) = − 1 N ∑ i = 1 N log P ( x i ∣ x < i ; θ ) \mathcal{L}_{\text{CLM}}(\theta)=-\frac{1}{N}\sum_{i=1}^N\log P(x_i|x_{<i};\theta) \\ LCLM(θ)=−N1i=1∑NlogP(xi∣x<i;θ)
其中 θ \theta θ是模型参数, N N N是序列长度, x i x_i xi是序列中第i个token, x < i x_{<i} x<i表示第i个token前的所有token。选择性语言建模重点关注那些与reference模型相比具有高损失值的token。超额损失值 L Δ \mathcal{L}_{\Delta} LΔ的定义为:
L Δ ( x i ) = L θ ( x i ) − L ref ( x i ) \mathcal{L}_{\Delta}(x_i)=\mathcal{L}_{\theta}(x_i)-\mathcal{L}_{\text{ref}}(x_i) \\ LΔ(xi)=Lθ(xi)−Lref(xi)
这里引入一个选择比例k%,用于根据超额损失值来确定包含token的比例。选择性token的交叉熵损失值为:
L SLM ( θ ) = − 1 N × k % ∑ i = 1 N I k % ( x i ) ⋅ log P ( x i ∣ x < i ; θ ) \mathcal{L}_{\text{SLM}}(\theta)=-\frac{1}{N\times k\%}\sum_{i=1}^N I_{k\%}(x_i)\cdot\log P(x_i|x_{<i};\theta) \\ LSLM(θ)=−N×k%1</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











