







Scrapy 伪分布式爬虫
应用 Scrapy框架 ,使用redis实现伪分布式爬虫。
# settings 配置redis
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER_PERSIST = True
# spider 引入并配置redis
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from proxy.items import ProxyItem
from scrapy_redis.spiders import RedisCrawlSpider
class XiciSpider(RedisCrawlSpider):
name = 'xici'
redis_key = 'myspider:start_urls'
def parse_start_url(self, response):
print(response)
rules = (
Rule(LinkExtractor(allow=r'/nt/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
print(response.url)
item = ProxyItem()
list = response.xpath('//table[@id="ip_list"]/tr')
for listItem in list:
item['country'] = listItem.xpath('.//td[1]/img/@alt').get()
item['ipAddress'] = listItem.xpath('.//td[2]/text()').get()
item['port'] = listItem.xpath('.//td[3]/text()').get()
item['serverAddress'] = listItem.xpath('.//td[4]/a/text()').get()
item['type'] = str(listItem.xpath('.//td[6]/text()').get()).lower()
item['timeToLive'] = listItem.xpath('.//td[9]/text()').get()
item['proofTime'] = listItem.xpath('.//td[10]/text()').get()
yield item
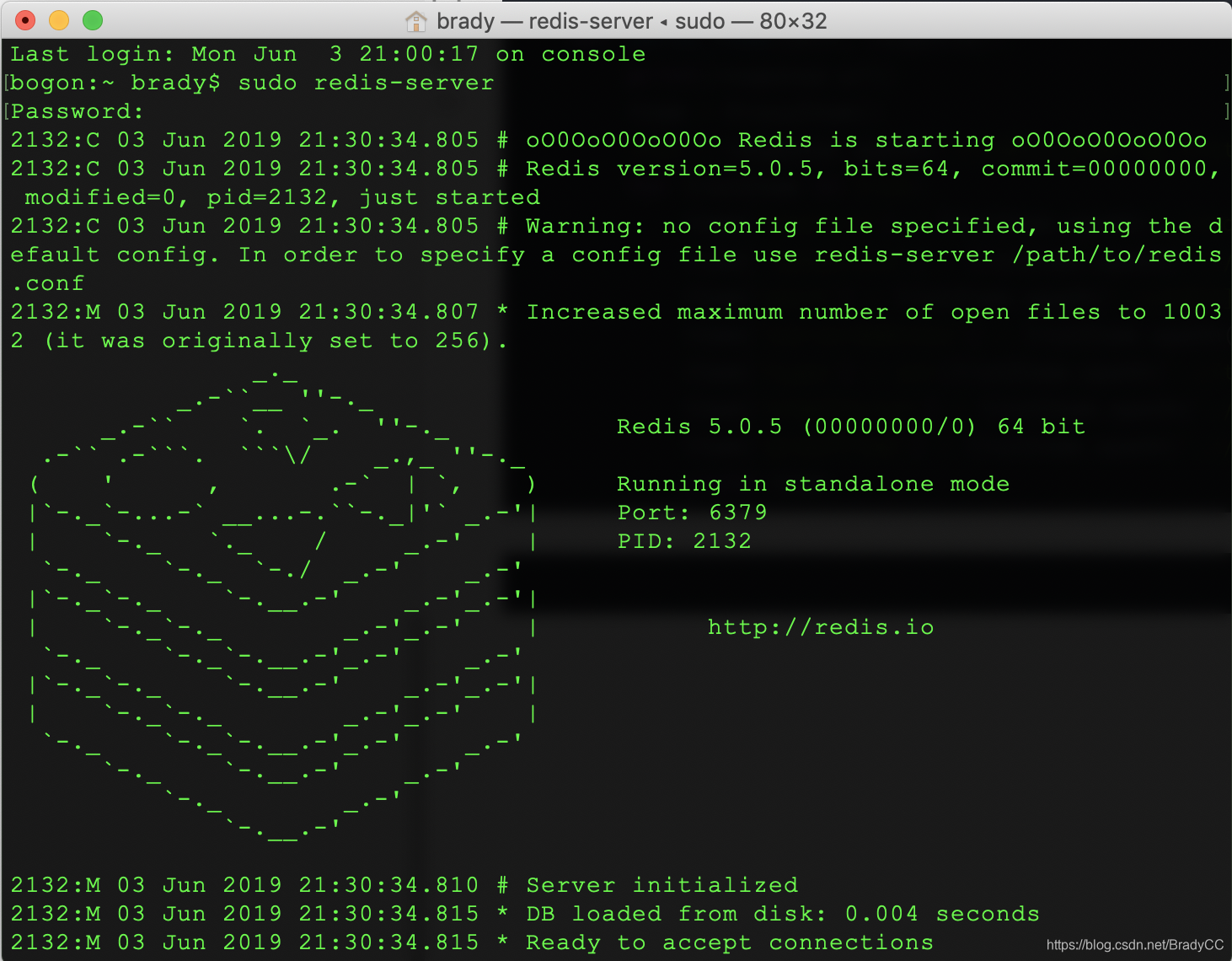
启动 redis服务 - redis-server。
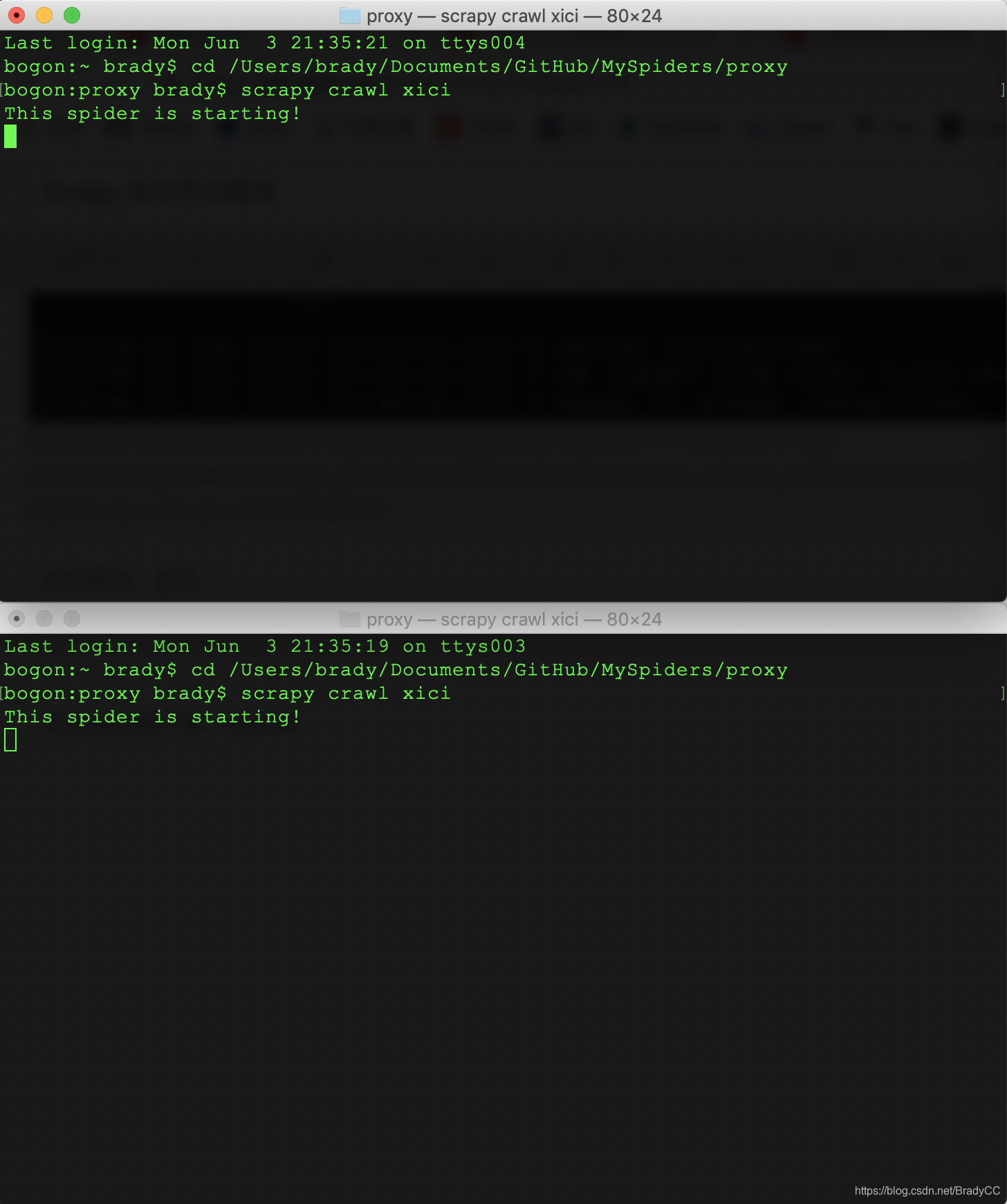
启动爬虫,监听
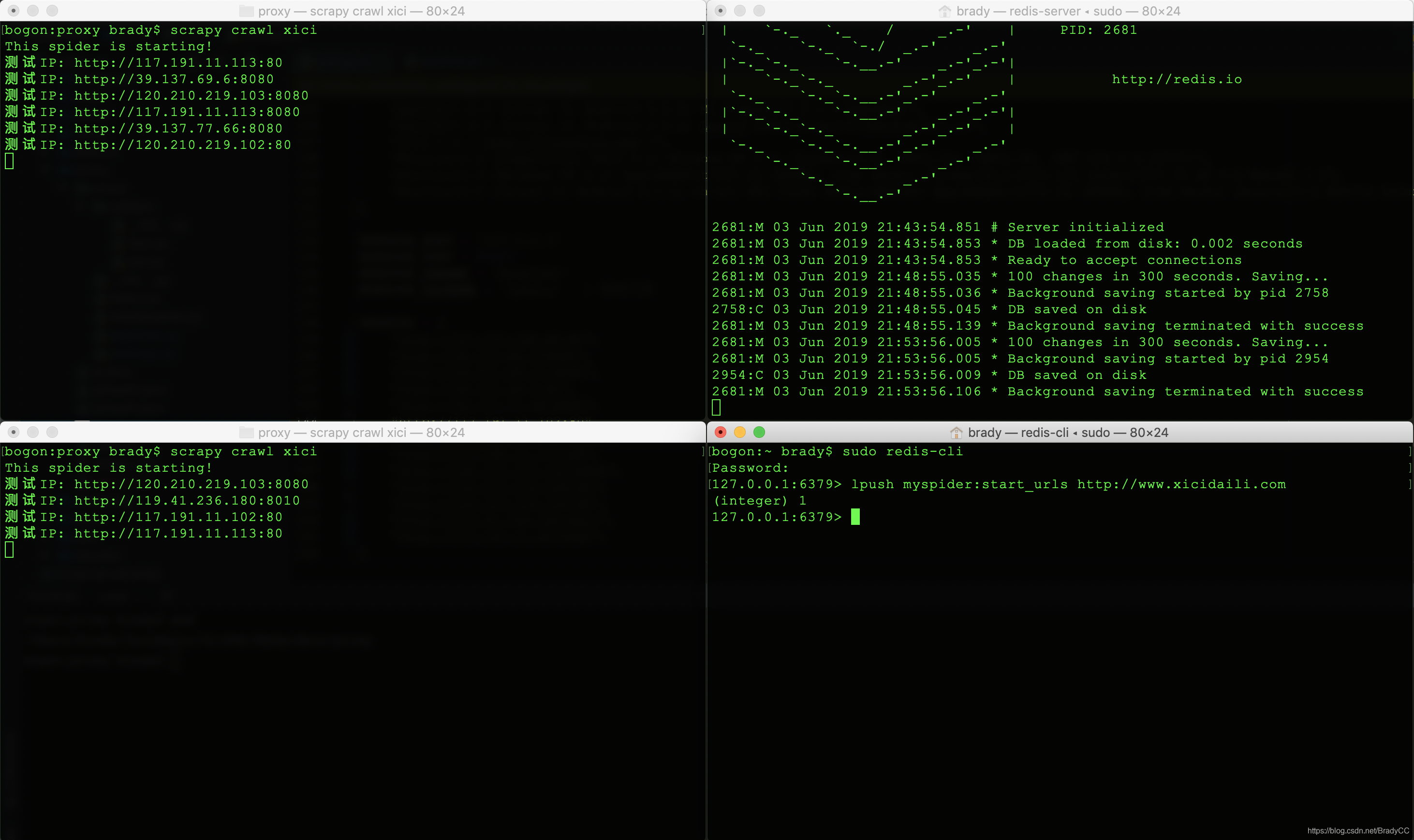
启动redis客户端 - redis-cli, 执行伪分布式爬虫















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









