







写入时复制(Copy-on-write)是一个被使用在程序设计领域的最佳化策略。其基础的观念是,如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立。--百度百科
简介
copy-on-write (以下简称COW)是计算机领域非常经典的优化思想,在各个领域很多方面上都有具体的应用。例如Linux OS利用COW思想实现lazy copy以节省资源提高性能,java中利用COW思想实现集合的读写分离的并发策略(CopyOnWriteArrayList&CopyOnWriteArraySet),以提高性能且保证并发安全,redis中的数据持久化策略都使用了cow思想,Kafka中利用COW思想实现消息Map,避免更新key-value的时候阻塞住高频的读操作,实现无锁的效果,优化线程并发的性能,等等。
Linux方面:
进程是操作系统中比较昂贵的资源,它具有自己的数据和程序。
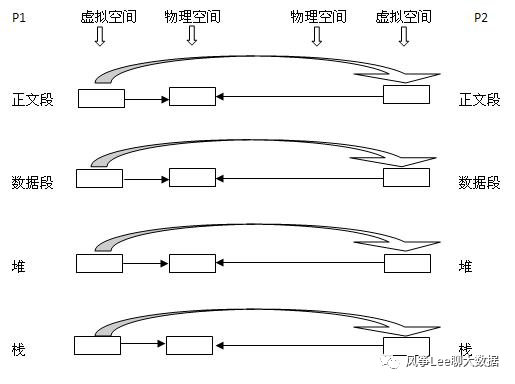
传统方式下,fork()函数在创建子进程时直接把所有资源复制给子进程,即:正文段块,数据段块,堆块,栈块。这种实现方式简单,但是效率低下,而且复制的资源可能对子进程毫无用处。linux为了降低创建子进程的成本,改进fork()实现方式使用COW技术创建子进程。当父进程创建子进程时,内核只为子进程创建虚拟空间,父子两个进程使用的是相同的物理空间。只有父子进程发生更改时才会为子进程分配独立的物理空间。
下图展示从P1进程创建子进程P2时的物理空间使用状况。通过COW技术,fork()延迟了数据拷贝,根据子进程的实际操作最终可能完全避免数据复制,如:子进程创建后运行一个与当前数据无关的可执行文件。
Java方面:
集合框架中的ArrayList是非线程安全的,Vector虽是线程安全的,但由于简单粗暴的锁同步机制,性能较差。对于读多写少的场景来说,频繁地读取必然导致频繁地加锁,导致性能很差。
java中利用COW思想实现了CopyOnWriteArrayList、CopyOnWriteSet。但是与Linux OS上降低数据复制开销的目的不同,java中的COW集合更偏向于提供并发能力。总体设计思想是在读的过程中去掉了锁,而在写的过程中则需要引入互斥锁,但是这个锁不会影响到读本身,也就进一步释放了读的性能瓶颈。写入操作的源码分析(CopyOnWriteArrayList):
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
可见在集合内部,利用ReentrantLock同步多个写操作,具体流程梳理如下:
1.复制原始数据2.修改原始数据3.将修改后的数据赋给集合数据引用4.退出同步锁定区域
在写方法执行前和执行中的读操作都是直接取得旧数据的引用,由于迭代器的修改方法被禁用,所以迭代遍历数据的程序总是在使用一份不会改变的数据引用。因为写操作最后修改数据引用的操作是原子的,所以读操作不会错误的得到“部分修改”的数据。
优缺点分析:
-
优点:读操作性能很高,比较适用于读多写少的并发场景。CopyOnWriteArrayList由于其"读写分离"的思想,遍历和修改操作分别作用在不同的list容器,所以在使用迭代器进行遍历时候,不会抛出ConcurrentModificationException异常
-
缺点:内存占用问题,毕竟每次执行写操作都要将原容器拷贝一份,数据量大时,对内存压力较大,可能会引起频繁GC;另外无法保证实时性,CopyOnWriteArrayList由于其实现策略的原因,写和读分别作用在新老不同容器上,在写操作执行过程中,读不会阻塞但读取到的却是老容器的数据。
linux内核中有一种叫做RCU(Read-Copy Update)数据共享策略跟COW十分相似,唯一不同在于RCU的新旧数据替换同过特定的回调(callback)机制被动执行,而不是由写操作进程自助完成。
Redis方面:
某些情况下,我们希望保存redis中的数据,那么只用一个主线程处理请求的redis是怎么在处理请求的同时进行数据持久化的呢?答案当然是依赖COW,具体来说就是依赖系统的fork()函数的COW实现。
Redis中为了保证住线程处理请求的同时进行数据持久化,利用了COW思想。Redis的两种数据持久化策略这(RDB快照和AOF日志)都利用了COW思想,具体来说就是依赖系统的fork()函数的COW实现。
参考一些博客上的相关信息:
Redis在持久化时,如果是采用BGSAVE命令或者BGREWRITEAOF的方式,那Redis会fork出一个子进程来读取数据,从而写到磁盘中。
总体来看,Redis还是读操作比较多。如果子进程存在期间,发生了大量的写操作,那可能就会出现很多的分页错误(页异常中断page-fault),这样就得耗费不少性能在复制上。
而在rehash阶段上,写操作是无法避免的。所以Redis在fork出子进程之后,将负载因子阈值提高,尽量减少写操作,避免不必要的内存写入操作,最大限度地节约内存。
Kafka方面:
我们知道,客户端在向Kafka写数据的时候,会把消息先写入客户端本地的内存缓冲,然后在内存缓冲里形成一个Batch之后再一次性发送到Kafka服务器上去,这样的异步的实现以助于提升吞吐量。
其中内存缓冲中消息的数据结构CopyOnWriteMap的实现就是利用的COW思想,具体源码如下:
import java.util.Collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ConcurrentMap;
/**
* A simple read-optimized map implementation that synchronizes only writes and does a full copy on each modification
*/
/**
* 读写分离 的设计方案:适合场景 读多写少
* 读多:
* 写少:
* @param <K>
* @param <V>
*/
public class CopyOnWriteMap<K, V> implements ConcurrentMap<K, V> {
/**
* 使用volatile 使得其他线程可见
*/
private volatile Map<K, V> map;
public CopyOnWriteMap() {
this.map = Collections.emptyMap();
}
public CopyOnWriteMap(Map<K, V> map) {
this.map = Collections.unmodifiableMap(map);
}
@Override
public boolean containsKey(Object k) {
return map.containsKey(k);
}
@Override
public boolean containsValue(Object v) {
return map.containsValue(v);
}
@Override
public Set<java.util.Map.Entry<K, V>> entrySet() {
return map.entrySet();
}
/**
* 没有加同步锁 读取性能很高
* 因为这个是读写分离 思想 不需要加锁
* @param k
* @return
*/
@Override
public V get(Object k) {
return map.get(k);
}
@Override
public boolean isEmpty() {
return map.isEmpty();
}
@Override
public Set<K> keySet() {
return map.keySet();
}
@Override
public int size() {
return map.size();
}
@Override
public Collection<V> values() {
return map.values();
}
@Override
public synchronized void clear() {
this.map = Collections.emptyMap();
}
/**
* 每一次新增数据都是开辟新的内存空间
* 然后再进行合并数据 并且 这个是同步的
* @param k
* @param v
* @return
*/
@Override
public synchronized V put(K k, V v) {
// 往新的内存空间写入数据
// 读写分离
Map<K, V> copy = new HashMap<K, V>(this.map);
// 插入数据
V prev = copy.put(k, v);
// 赋值给map 合并到旧的map里
this.map = Collections.unmodifiableMap(copy);
return prev;
}
@Override
public synchronized void putAll(Map<? extends K, ? extends V> entries) {
Map<K, V> copy = new HashMap<K, V>(this.map);
copy.putAll(entries);
this.map = Collections.unmodifiableMap(copy);
}
@Override
public synchronized V remove(Object key) {
Map<K, V> copy = new HashMap<K, V>(this.map);
V prev = copy.remove(key);
this.map = Collections.unmodifiableMap(copy);
return prev;
}
@Override
public synchronized V putIfAbsent(K k, V v) {
// 如果我们传进来的key 不存在
if (!containsKey(k))
return put(k, v);
else
return get(k);
}
@Override
public synchronized boolean remove(Object k, Object v) {
if (containsKey(k) && get(k).equals(v)) {
remove(k);
return true;
} else {
return false;
}
}
@Override
public synchronized boolean replace(K k, V original, V replacement) {
if (containsKey(k) && get(k).equals(original)) {
put(k, replacement);
return true;
} else {
return false;
}
}
@Override
public synchronized V replace(K k, V v) {
if (containsKey(k)) {
return put(k, v);
} else {
return null;
}
}
}
为什么要采用这个结构呢?这个数据结构需要支持的是读多写少的场景。读多是因为每条消息过来都会根据 key 读取 value 的信息,假如有 1000 万条消息,那么就会读取 batches 对象 1000 万次。写少是因为,比如我们生产者发送数据需要往一个主题里面去发送数据,假设这个主题有 50 个分区,那么这个 batches 里面就需要写 50 个 key-value 数据就可以了(大家要搞清楚我们虽然要写 1000 万条数据,但是这 1000 万条是写入 queue 队列的 batch 里的,并不是直接写入 batches,所以就我们刚刚说的这个场景,batches 里只需要最多写 50 条数据就可以了)。
所以Kafka就采用了CopyOnWrite思想来实现这个Map,避免更新key-value的时候阻塞住高频的读操作,实现无锁的效果,优化线程并发的性能。
总结
copy-on-write是一种容易理解且比较简单高效的优化策略,可以在数据备份或者读多写少的场景下选择使用,且已经在各个领域很多方面上都有具体的应用, 在使用其思想优化或者解决问题时可以参考借鉴其在各个方向上的应用。















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









