







 K-SVD是一种字典学习算法,用于稀疏表示问题,是K-means的推广。它通过迭代优化数据在字典中的表示和更新字典,广泛应用于图像、语音等领域。算法首先固定字典求最佳系数,然后更新字典的每一列,利用SVD进行优化。尽管存在非凸优化问题导致局部最优,但在实践中表现良好。
K-SVD是一种字典学习算法,用于稀疏表示问题,是K-means的推广。它通过迭代优化数据在字典中的表示和更新字典,广泛应用于图像、语音等领域。算法首先固定字典求最佳系数,然后更新字典的每一列,利用SVD进行优化。尽管存在非凸优化问题导致局部最优,但在实践中表现良好。
参考网址:http://en.wikipedia.org/wiki/K-SVD
K-SVD 是一种关于稀疏表示的字典学习算法。之所以称之为K-SVD ,是因为该算法K次迭代使用SVD(singular value decomposition)。K-SVD是 k-means的一种推广,该算法采用迭代交替学习方式,通过迭代优化输入数据在当前字典的表示和更新字典中的单词(atom)以更好地拟合数据1][2] 。 K-SVD在图像处理、语音处理、生物和文件分析等众多领域被广泛应用。
稀疏表示问题描述
给定一个过完备的字典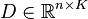 ,该字典包含
,该字典包含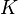 个单词,在此每一列都被视作一个单词。一个信号
个单词,在此每一列都被视作一个单词。一个信号 能够被表示为这些单词的线性组合。为表示
能够被表示为这些单词的线性组合。为表示 ,稀疏表示
,稀疏表示  应当满足精确条件
应当满足精确条件 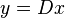 , 或者满足近似条件
, 或者满足近似条件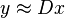 , 或者满足条件
, 或者满足条件  . 向量
. 向量  由表示的系数组成. 通常来说, 范数
由表示的系数组成. 通常来说, 范数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









