







第 3 章 进程管理
这一章主要介绍进程在linux系统中的表示,从如何创建到如何被回收的整个过程。同时特别提到了线程在linux系统中的实现。
进程的定义:
进程就是处于执行期的程序,但进程不仅局限于可执行代码,还包括其他资源,比如打开的文件,挂起的信号,内核数据,处理器状态,多个线程,全局变量等。
线程的定义:
线程是进程中活动的对象,线程有单独的程序计数器,进程栈,一组进程寄存器。值得注意的是,unix系统中,一个进程包括一个线程,但linux系统中,线程和进程其实不区分的(内核角度)。
虚拟机制:虚拟处理器和虚拟内存。线程之间共享虚拟内存,但每个有各自的虚拟处理器。
记住,进程是执行期的程序 + 相关资源
进程创建通常是通过fork()系统调用来实现,通过复制现有进程来创建全新进程,调用一次,返回两次,一次回到父进程,返回子进程PID,一次回到子进程,返回0。一般创建新的进程都是为了执行新的程序,接着调用exec()可以创建新的地址空间。linux中,fork()实际上是clone()系统调用实现的。
最终程序通过exit()退出执行,释放资源。父进程通过wait()系统调用获得子进程状态,这时,子进程才从僵死状态中,完全被释放掉。
进程描述符及任务结构
进程列表在内核中是一个任务队列的双向循环链表。结点的数据类型是task_struct,称为进程描述符。包含进程所有信息,在32位机器上,大约有1.7kb。
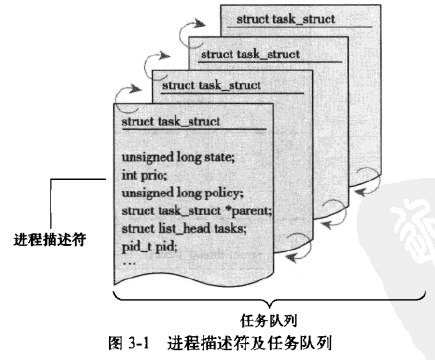
linux 通过slab分配器分配task_struct结构。这样的目的是对象复用和缓存着色。避免动态分配和释放带来的资源消耗
进程创建时会产生两个栈,一个用户空间的进程栈,另一个是属于内核空间的内核栈。进程调用系统调用陷入内核态就会发生栈的切换。实际上只是栈的地址的变动。这里需要注意的是,从用户空间陷入内核态时,内核栈已经是清空的,因此,这时仅仅是将内核栈的栈顶指针给现在的栈地址寄存器就行。
进程内核栈是一个thread_union的结构如下:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THEREAD_SIZE/sizeof(long)];
};
struct thread_info {
struct task_struct *task; // 注意
struct exec_domain *exec_domain;
__u32 flg;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};
struct task_struct {
void *stack; // 注意
};
从代码中可以看出task_struct 和 thread_info 相互保持对方的指针。再看一个进程内核栈的布局图,我们就知道,可以通过计算直接得到thread_info的指针。
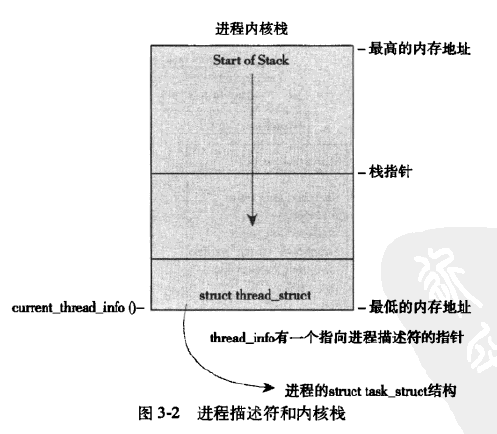
因此,内核栈和进程描述符之间就有了一个座桥梁,可以相互引用。
PID标识每个进程,类型为pid_t,实际上是一个int类型,默认值最大32768.可以修改。这个值越小,转一圈就越快。
进程状态
系统中的进程必处于五种状态之一,如图:
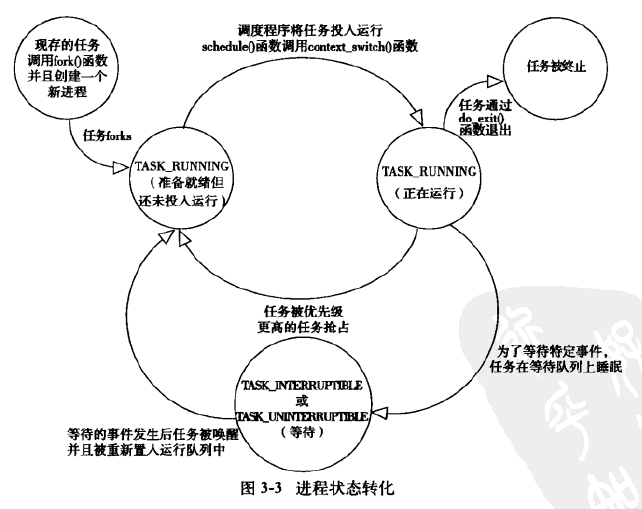
可中断,进程处于睡眠(阻塞),等待某些条件达成,但可以被信号提前唤醒
不可中断,进程处于睡眠(组设),等待某些条件达成,不会被信号提前唤醒
进程的状态可以设置,但是我们知道这里会需要设置内存屏障,强制其他处理器重新排序。避免不一致状态:)
进程家族树
linux系统中的进程有明显的继承关系。原因是将进程的创建分为fork()/exec()两个阶段。所有的进程都是PID为1的init进程的后代。内核在系统启动的最后阶段启动init进程,该进程读取初始化脚本并执行其他的相关程序,最终完成系统的启动过程。
进程描述符中,有parent指针,指向父进程,有children list,表示子进程链表。还有任务队列中的next、prev指针,指向任务队列的前一个和下一个进程。
进程创建
刚才说到,进程的创建和特别(unix,linux)。许多其他的系统是通过spawn进程机制,创建新的地址空间,读入可执行文件,最后开始执行。而linux采用fork()和exec()。fork拷贝当前进程,创建一个子进程,区别仅仅在于PID、PPID和一些统计量(挂起的信号等)。exec负责读取可执行文件,开始运行。
传统的fork,直接复制所有资源给新进程。简单但效率低下,因为大多数新进程都打算立即执行exec,那之前的拷贝就毫无意义。linux的fork使用的是写时拷贝(copy on write)页实现。延迟拷贝的过程,内核不复制整个进程地址空间,而父子进程共享一个进程地址空间。只有需要写入时,数据才会被赋值。实际大部分新进程都是立即执行exec,不需要复制原有的进程数据。能够快速创建进程。
fork的实际开销是,复制父进程的页表以及给子进程创建唯一的进程描述符。
线程在linux中的实现
我们一般来说,线程是轻量级的进程,进程中包含若干线程。同一程序的线程共享内存地址空间,包括打开的文件和其他资源。linux实现线程非常特别,从内核的角度,没有线程的概念。linux把所有的线程当成进程来实现。线程仅仅被视为和其他进程共享某些资源(地址空间)的进程。每个线程有自己的task_struct,所以在内核看来就是一个普通的进程。想想,实际这种方法很高明。
线程的创建时调用clone(),但是传入了CLONE_VM参数,表示共享地址空间。
进程终止
进程终止需要释放它占用的资源,包括task_struct。进程的析构是自身引起的,通过调用exit()系统调用,释放资源,包括打开的文件描述符,定时器等。最后调用exit_notify给父进程发送信号,给子进程重新找养父,养父为同一进程组的其他进程或者init进程。进程的状态为EXIT_ZOMBIE。进程处于这个僵死状态,它现在占用的内存就是内核栈、thread_info结构和task_struct结构。唯一的目的就是向它的父进程提供信息。父进程检索到信息后,通知内核那是无关信息,进程剩余内存被释放掉。














 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









