







因为OLAP存在一些缺点,如提供给用户的分析方式有限,用户没有足够的时间去查看所有的图表,以及用户只关心搜索他们所参与的业务模式。数据挖掘的出现可以解决上面的绝大多数问题,因为它是数据驱动,并且基于数学方法,可以在有限的时间内检查大量的数据,发现的有用的模式和规则。
考试目标:
l 建立数据挖掘解决方案
Ø 用挖掘向导建立挖掘结构
Ø 用挖掘设计器修改挖掘结构
Ø 使用多个模型进行算法间比较
Ø 指定表和列为key, input, predictable
Ø 指定列的内容
Ø 指定case 和 nested table
l 选择一种数据挖掘定义方法
Ø 从关系数据建立定义
Ø 从多维数据建立定义
l 配置算法参数
一、数据挖掘准备
1、数据挖掘生命周期
1)确定要回答的业务问题
2)模式发现
3)业务决策
4)反馈
2、为DM准备数据
1)在数据挖掘前,应当进行一次数据调查,获取数据的统计信息
分数据的值进行分类:
l 类别或名义属性。离散值,无序的,如颜色、状态码、状态
l 排名。有序的离散值,不允许算术运算
l 间隔。有序的连续值,但不允许汇总,如日期、时间和温度。
l 真正的数字变量。支持所有的数学运算,如金额和数量。
2)决定CASE的构成,是否包含nested case
3)决定如何处理其它与缺失值
4)分别准备训练集和测试集
训练集用来训练模型,而测试集用来预测。
对于小表随机数据的查询应使用下面的SQL语句:
/*抽样20%的数据*/
Select *
Into TK445_Ch09_TestSet
From vTargetMail
Where RAND (CHECKSUM(NEWID())%1000000000+CustomerKey) < 0.2
二、建立数据挖掘结构和模型
挖掘结构定义数据类型、内容类型、数据分布
挖掘模型继承全部或者部分挖掘结构的列属性,并指定列用途为输入、预测或者输入与预测,指定数据挖掘算法及参数。
1、数据挖掘算法
1)九种数据挖掘算法是:
| 算法 | 用途 |
| 决策树 | 可用于预测离散与连续值。当预测连接值时采用线性衰退方程式,把树分隔成节点。结果易于理解。 |
| 线性衰退 | 只能预测连续值,并且输入变量也要求是连续值,是一种没有分隔的衰退树。 |
| 贝叶斯 | 不支持连续值,算法简单,模型处理快。根据己知预测未知 |
| 神经网络算法 | 机器学习,一种线性算法 |
| 罗吉斯衰退算法 | 没有隐藏层的神经网络算法 |
| 聚类算法 | 分组 |
| 序列聚类算法 | 使用马克链从一系列事件中建立模型,只能用于序列数据,如WEB 站点访问预测 |
| 关联规则算法 | 常用于市场购物篮分析 |
| 时间序列算法 | 用于预测连续变量,也称为自动衰退树算法 |
2)SSIS中的两个文本挖掘算法:
A、Term Extraction Transformation
从文本中抽取重要的名词、名词短语
B、Term Lookup Transformation
查找字典中的哪些术语包含在文本中,输出内容包括两部分:术语和出现频率。搜集的信息可用于文档的聚类分析。
最佳实践:对于一项任务,你应当总是能够采用不同算法和参数的多个模型,然后对模型进行评价,找出最佳的那一个部署。永远不要只依赖一个模型得出的结果。
三、建立关联、序列和预测模型
1、挖掘结构属性到字段的映射
1)column usuage
Predictable, input, predictable and input, ignored
2)content type
Discrete, continuous, discretized, Ordered, cyclical
3)key column type
Key sequence column, key time column
四、使用cube作为数据源与配置数据挖掘算法
1、使用CUBE源
关系源更容易建立导出字段
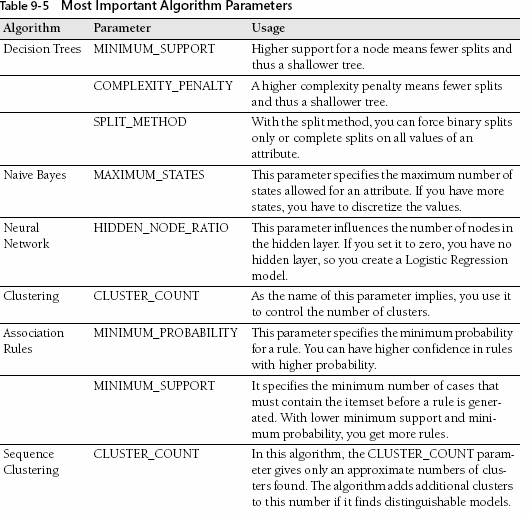
2、配置算法
















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









