







基础篇 | 文生图 - 电商广告图片生成器
一、学习目标
在上一小节中,我们学习了 Spring AI 中聊天客户端的使用方法,当然 AI 大模型的能力远远不至于回答你的问题,包括文生图、音频转文字、文字转音频等等功能在后面的章节中都会慢慢学习到。那么这一小节,我们将学习 Spring AI 中非常强大的功能:文生图,通过这种技术完成一个新的案例:电商广告图片生成器。
我们先来看下最终的效果以及本章实现的系统具备的功能:
一、提示词优化 : 提示词是文生图的关键,优化它能提升生成图片质量与精准度,帮助用户精准描述所想画面。如想要梦幻森林,起初用 “森林”,生成场景普通,优化为 “迷雾笼罩、月光洒下、有奇异发光植物的梦幻森林”,就能引导模型勾勒奇幻、细节丰富的画面。系统自带提示词优化功能,精准调整描述主体、细节、风格用词,让模型理解需求,产出贴合期待的图像。

二、文生图
核心功能,用户只需输入一段文字描述,就能借助人工智能算法将抽象的文字迅速转化为具象的视觉图像。

三、高级设置:模型、图片大小
模型选择:满足用户选择不同的模型进行图片生成,灵活选择收费、免费模型。
图片大小:此项设置决定了生成图片的分辨率与尺寸规格。若需要用于社交媒体封面、海报宣传等场景,可选择较大尺寸,保证画面细节在放大展示时依旧清晰,吸引观众目光;若是仅为快速预览、手机屏保等日常简单用途,小尺寸既能快速生成,又节省资源,让用户根据实际使用场景灵活定制图片输出,获得最佳体验。

二、功能开发
首先我们来看一下整个系统的流程设计图:
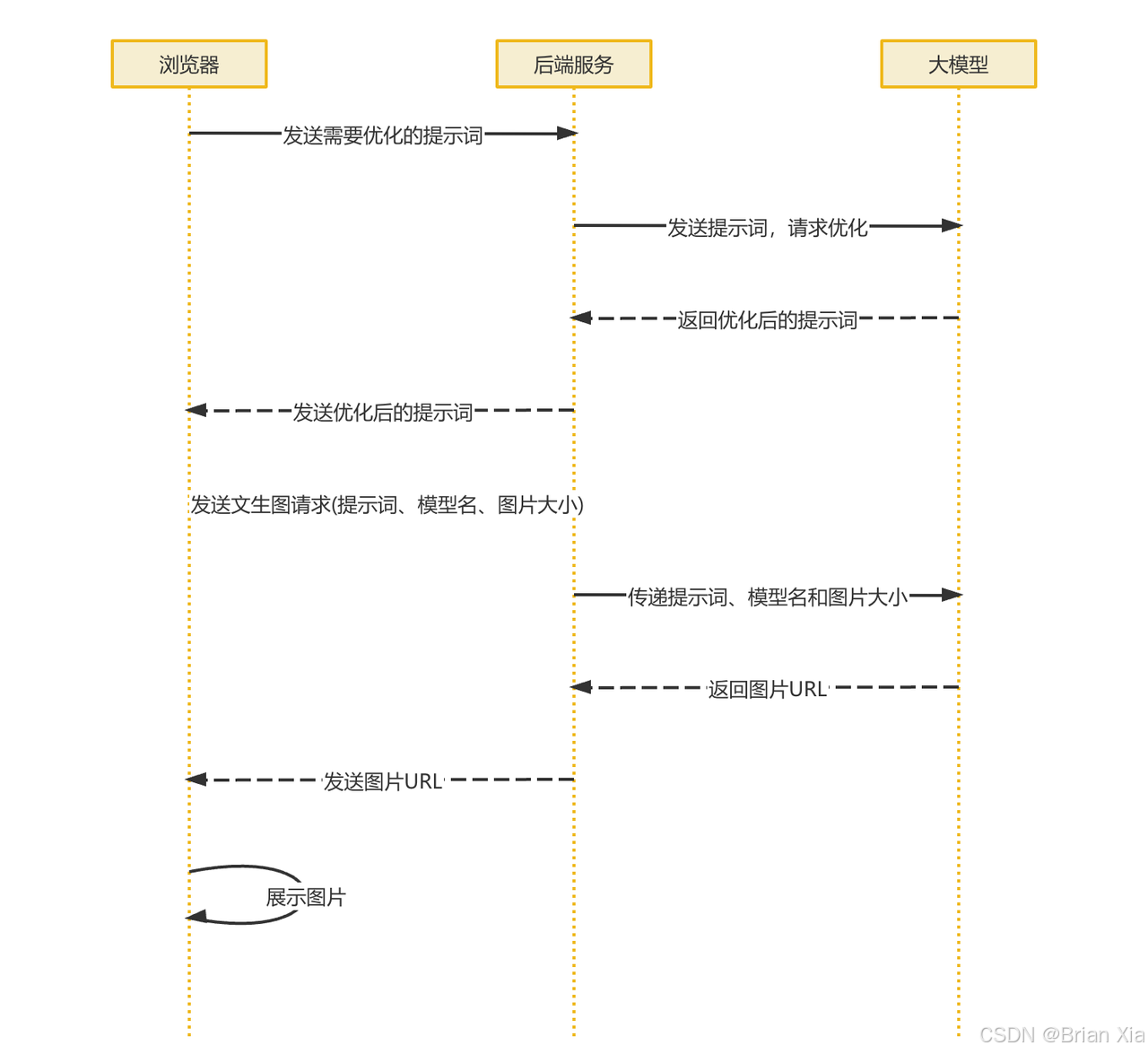
整体流程如下:
1、浏览器调用优化提示词的接口,将需要优化的提示词发送到后端服务。
2、后端服务获取到提示词,调用大模型接口,发送提示词,获取优化后的提示词。
3、后端将优化后的提示词返回给浏览器。
4、浏览器发送文生图请求到后端,参数中会携带提示词、模型名字和图片大小。
5、后端服务调用大模型接口,传递提示词、模型名字和图片大小。
6、大模型返回图片 url 给后端服务。
7、后端服务返回图片 Url 给前端。
8、浏览器展示图片。
其中 1~3 步使用第二章 ChatClient 技术就可以完成,而 4~ 8 步需要用到 Spring AI 文生图相关的技术。我们先来完成提示词优化功能。
提示词优化
一、为什么提示词优化是 AI 应用的核心瓶颈?
1. 模型的"认知偏差"
大语言模型本质是基于统计规律的"概率生成器",其输出高度依赖输入提示的质量。
比如如下案例:
❌ 提示词:“写一首关于春天的诗” → 生成内容可能流于表面(“春天花开草长莺飞”)
✅ 优化后:“请以余光中《逍遥游》的隐喻手法,结合《诗经》中的植物意象,创作一首体现生命轮回主题的现代诗”
→ 引发模型调用文学知识库,生成深度内容 :
《浮生纪事》
(一)
青铜碑文在江底锈蚀时
蒹葭正一节节攀援月光
那些被浪花带走的骨殖
沉入淤泥便成了新生的菌丝体
这样生成出来的效果就比较符合用户的预期了。
2. 信息检索的"暗黑森林"
目前大量模型都接入了互联网搜索,但是如果模型是私有化部署的,它无法直接访问互联网,那么所有知识都基于训练数据中的概率关联。此时就可以使用优化技巧:通过特定关键词锚定引导模型调用特定知识模块
你是一个三级医院心血管外科主任医师,根据《2025ESC心血管疾病治疗指南》最新证据:
1. 解释ST段抬高型心肌梗死患者的急诊处理流程
2. 对比静脉溶栓与介入治疗的适应症差异
3. 提供术后康复阶段的营养支持方案,需包含具体热量计算公式
关键词锚定 = 给模型"贴标签"
就像给快递箱贴上「易碎」「冷藏」标签,让快递员知道该怎么处理。在提示词里给关键词贴上"专业标签",能让大模型更准确地"理解你的需求"。
这段提示词用了哪些"标签"?
- 身份标签
三级医院心血管外科主任医师
➔ 相当于告诉模型:“你现在是专业医生,要用临床指南说话” - 证据标签
《2025ESC心血管疾病治疗指南》最新证据
➔ 告诉模型:“只能用今年最新的医学指南,不能用过时的知识” - 专业术语标签
ST段抬高型心肌梗死、静脉溶栓、介入治疗
➔ 相当于在文档里用红色荧光笔标出重点词汇 - 流程标签
急诊处理流程、术后康复营养方案
➔ 告诉模型:“要按照步骤一步步回答,不能乱来”
贴标签的好处
二**、如何优化提示词?**
-
目标明确性
就像你去机场要明确说"去北京首都国际机场(BAA)“,而不是模糊地说"去北方”。提示词必须清晰定义最终交付物和核心诉求,避免模型自由发挥导致偏离需求。
✅ 使用动作动词 + 量化指标(如"生成包含 5 个创意标题的广告方案")
✅ 明确限定内容范围(如"只讨论技术可行性,不涉及商业风险")- ✅ 优秀案例:
"用Python写一个自动整理Excel数据的脚本,要求:①合并多张工作表 ②筛选出销售额>10万的记录 ③生成柱状图" - ❌ 反面教材:
"帮我处理Excel文件"
- ✅ 优秀案例:
-
专业约束力
给模型戴上"专业眼镜",强制其调用特定领域的知识体系或操作流程,避免生成泛泛而谈的内容。
✅ 引用行业标准(如"根据《建筑设计防火规范》GB50016")
✅ 规定技术路线(如"使用 Python+TensorFlow 框架实现图像分类")
✅ 设置质量门槛(如"BLEU 分数 ≥0.85")- ✅ 优秀案例:
"作为ICU护士长,根据《重症患者营养治疗指南》,为术后ARDS患者制定包含热量计算(使用Harris-Benedict公式)和蛋白质摄入量(≥1.5g/kg/d)的肠内营养方案" - ❌ 反面教材:
"怎么给病人安排饮食"
- ✅ 优秀案例:
-
结构化表达
将复杂需求拆解为模块化步骤,用序号、项目符号或代码格式引导模型按逻辑输出,避免思维跳跃。
✅ 分步骤描述(如"第一步收集数据 → 第二步训练模型 → 第三步生成报告")
✅ 使用表格/代码块/Markdown 格式(如要求输出"包含字段:姓名、年龄、血压值的 JSON 结构")
✅ 设定优先级顺序(如"首要解决性能问题,其次优化 UI 设计")- ✅ 优秀案例:
要求:
- 功能:实时翻译工具
- 技术:集成 WebRTC 语音识别 +Transformer 模型
- 限制:延迟 <200ms,支持中英日韩四语种
- 输出:提供前端 Vue3 代码 + 后端 Node.js 接口文档
- ❌ **反面教材**:
`"写个能翻译的软件"`
## **大模型优化提示词**
### **大模型优化提示词的优势**
除了用户自己去优化提示词,其实我们也可以利用大模型技术,让大模型去优化提示词,实现自产自销。
利用大模型优化不太好的提示词有以下优点:
**一、改善表达清晰度方面**
**二、提升针对性方面**
**三、增强逻辑性方面**
### 后端开发
那接下来我们就来开发这个功能,首先创建一个`Controller`:
```java
_/**_
_ * 图片生成控制器_
_ * 提供文本生成图片相关的接口_
_ */_
@RestController
@RequestMapping("/text-to-image")
@RequiredArgsConstructor
public class ImageGenerationController {
_ /**_
_ * 优化提示词_
_ * _
_ * @param request 包含原始提示词的请求_
_ * @return 优化后的提示词_
_ */_
@PostMapping("/optimize-prompt")
public Result<String> **optimizePrompt**(@RequestBody Map<String, String> _request_) {
try {
String optimizedPrompt = imageGenerationService.optimizePrompt(_request_.get("prompt"));
return Result.success(optimizedPrompt, "提示词优化成功");
} catch (Exception _e_) {
return Result.error("提示词优化失败:" + e.getMessage());
}
}
}
这里从参数中获取到了 prompt 字段,也就是用户提交的提示词,传递到了 service 中进行处理。在这一小节中,我们规范了返回结果的处理,用了一个单独的类 Result 进行封装。我们来看下 Result 的实现:
_/**_
_ * 统一返回结果类_
_ * 用于封装所有API的返回结果_
_ */_
@Data
public class Result<T> {
private Integer code; // 状态码:0成功,非0失败
private String message; // 提示信息
private T data; // 返回数据
private LocalDateTime timestamp; // 时间戳
_/**_
_ * 成功返回结果_
_ * _
_ * @param data 返回数据_
_ */_
_ _public static <T> Result<T> success(T data) {
Result<T> result = new Result<>();
result.setCode(0);
result.setMessage("success");
result.setData(data);
result.setTimestamp(LocalDateTime.now());
return result;
}
_/**_
_ * 成功返回结果_
_ * _
_ * @param data 返回数据_
_ * @param message 成功提示信息_
_ */_
_ _public static <T> Result<T> success(T data, String message) {
Result<T> result = new Result<>();
result.setCode(0);
result.setMessage(message);
result.setData(data);
result.setTimestamp(LocalDateTime.now());
return result;
}
_/**_
_ * 失败返回结果_
_ * _
_ * @param message 错误提示信息_
_ */_
_ _public static <T> Result<T> error(String message) {
Result<T> result = new Result<>();
result.setCode(-1);
result.setMessage(message);
result.setTimestamp(LocalDateTime.now());
return result;
}
_/**_
_ * 失败返回结果_
_ * _
_ * @param code 错误码_
_ * @param message 错误提示信息_
_ */_
_ _public static <T> Result<T> error(Integer code, String message) {
Result<T> result = new Result<>();
result.setCode(code);
result.setMessage(message);
result.setTimestamp(LocalDateTime.now());
return result;
}
}
这段代码定义了一个名为 Result 的泛型类,用于统一封装 API(应用程序接口)的返回结果。通过这种方式,可以确保所有的 API 响应都遵循相同的结构和格式,便于前端或其他调用方解析和处理。
接下来实现 Service 层:
@Service
public class ImageGenerationService {
@Autowired
private ChatClient chatClient;
// 优化提示词的系统提示
private static final String _OPTIMIZE_SYSTEM_PROMPT _= "你是一个专业的AI绘图提示词优化专家,特别擅长优化电商海报的提示词。请按照以下规则优化用户的提示词:\n" +
"1. 保持用户原始需求的核心意图\n" +
"2. 添加更多细节描述,如光影效果、材质表现、空间布局等\n" +
"3. 使用更专业的设计术语\n" +
"4. 确保描述清晰、具体且富有创意\n" +
"5. 优化后的提示词应该更容易被AI理解和执行\n" +
"请直接返回优化后的提示词,不要包含任何解释或其他内容。";
_/**_
_ * 优化提示词_
_ * _
_ * @param prompt 原始提示词_
_ * @return 优化后的提示词_
_ */_
_ _public String optimizePrompt(String prompt) {
// 拼接OPTIMIZE_SYSTEM_PROMPT和prompt
prompt = _OPTIMIZE_SYSTEM_PROMPT _+ "\n" + prompt;
// 调用AI获取响应
return chatClient.prompt(prompt).call().content();
}
}
这段代码非常简单,通过构造了一个 System Prompt,要求大模型帮我们优化提示词,但是这段提示词还是非常值得大家去学习的。我们一起来解读一下:
“你是一个专业的 AI 绘图提示词优化专家,特别擅长优化电商海报的提示词。”
** **设定角色和专长领域。建立专业形象,明确优化方向,让用户信任且聚焦任务。
“请按照以下规则优化用户的提示词:”
引出具体优化规则。规范操作流程,使优化有章可循,保证结果稳定可靠。
“1. 保持用户原始需求的核心意图”
“2. 添加更多细节描述,如光影效果、材质表现、空间布局等”
“3. 使用更专业的设计术语”
“4. 确保描述清晰、具体且富有创意”
“5. 优化后的提示词应该更容易被 AI 理解和执行”
“请直接返回优化后的提示词,不要包含任何解释或其他内容。”
前端开发
// 优化提示词
async function optimizePrompt() {
const promptInput = _document_.getElementById('promptInput');
const optimizeBtn = _document_.getElementById('optimizeBtn');
const errorMessage = _document_.getElementById('errorMessage');
if (!promptInput.value.trim()) {
errorMessage.textContent = '请输入图片描述!';
errorMessage.style.display = 'block';
return;
}
// 禁用按钮
optimizeBtn.disabled = true;
optimizeBtn.textContent = '优化中...';
try {
const response = await fetch('/text-to-image/optimize-prompt', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: _JSON_.stringify({
prompt: promptInput.value
})
});
const data = await response.json();
if (data.code !== 0) {
throw new Error(data.message || '优化失败,请重试');
}
promptInput.value = data.data;
errorMessage.style.display = 'none';
} catch (error) {
errorMessage.textContent = error.message;
errorMessage.style.display = 'block';
} finally {
optimizeBtn.disabled = false;
optimizeBtn.textContent = '优化提示词';
}
}
代码非常简单,调用了 /text-to-image/optimize-prompt 接口,获取了对应的返回值。由于返回结果是 Result 对象,需要判断 code 是否异常,如果有异常就抛出异常。正常返回就获取 data 字段填入输入框中。
文生图功能开发
Spring AI 中提供了文生图功能,这是对应的官方网址。目前支持的大模型如下:
- OpenAI Image Generation
- Azure OpenAI Image Generation
- QianFan Image Generation
- StabilityAI Image Generation
- ZhiPuAI Image Generation
这一次我们依然使用智谱 AI 提供的文生图功能来实现。具体的使用方法如下:
1、引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-zhipuai-spring-boot-starter</artifactId>
</dependency>
2、注入 ImageModel:
@Autowired
private ImageModel imageModel;
3、设置参数:
// 构建图片生成选项
ImageOptions options = ImageOptionsBuilder._builder_()
.width(width)
.height(height)
.model(request.getModel())
.build();
不同模型支持的参数可能会有不同,这时需要通过特定的配置类进行配置:
ZhiPuAiImageOptions options = ZhiPuAiImageOptions._builder_().user("brian").build();
4、调用 call 方法获取数据:
// 构建图片生成请求
ImagePrompt imagePrompt = new ImagePrompt(fullPrompt, options);
// 调用AI生成图片
ImageResponse response = imageModel.call(imagePrompt);
// 返回生成的图片URL
return response.getResult().getOutput().getUrl();
这里注意不同模型返回的数据格式是不同的,比如千帆默认使用 B64JSON 返回,而智谱返回的是图片的 URL。
public class Image {
private String url;
private String b64Json;
所以要根据具体的模型,获取对应的数据。
后端开发
在 Controller 中添加接口:
_/**_
_ * 生成图片_
_ * _
_ * @param request 生成图片的请求参数_
_ * @return 生成的图片URL_
_ */_
@PostMapping("/generate")
public Result<String> generateImage(@RequestBody GenerateRequest request) {
try {
String imageUrl = imageGenerationService.generateImage(request);
return Result._success_(imageUrl, "图片生成成功");
} catch (Exception e) {
return Result._error_("图片生成失败:" + e.getMessage());
}
}
其中参数定义如下:
_/**_
_ * 生成图片的请求参数_
_ */_
@Data
public static class GenerateRequest {
private String prompt; // 提示词
private String size = "1024x1024"; // 图片尺寸,可选值:768x768, 1024x1024, 1536x1536, 2048x2048
private String model = "cogview-3-flash"; // AI模型,可选值:cogview-4(收费版), cogview-3-flash(免费版)
}
图片尺寸以固定 长x宽 的格式进行传递,大模型传递模型名。
在 Service 中调用大模型进行处理:
@Autowired
private ImageModel imageModel;
// 系统提示词,用于优化生成效果
private static final String _SYSTEM_PROMPT _= "你是一个专业的电商海报设计师,擅长创作具有商业价值的营销海报。" +
"请生成一张具有以下特点的高质量电商海报:" +
"1. 构图精美,主次分明,重点突出" +
"2. 色彩和谐,符合品牌调性" +
"3. 细节丰富,纹理清晰" +
"4. 文字布局合理(如有)" +
"5. 商品展示专业,突出卖点" +
"具体要求:";
_/**_
_ * 生成图片的请求参数_
_ */_
@Data
public static class GenerateRequest {
private String prompt; // 提示词
private String size = "1024x1024"; // 图片尺寸,可选值:768x768, 1024x1024, 1536x1536, 2048x2048
private String model = "cogview-3-flash"; // AI模型,可选值:cogview-4(收费版), cogview-3-flash(免费版)
}
_/**_
_ * 生成图片_
_ * _
_ * @param request 生成请求参数_
_ * @return 生成的图片URL_
_ */_
public String generateImage(GenerateRequest request) {
// 解析尺寸参数
String[] dimensions = request.getSize().split("x");
int width = Integer._parseInt_(dimensions[0]);
int height = Integer._parseInt_(dimensions[1]);
// 构建图片生成选项
ImageOptions options = ImageOptionsBuilder._builder_()
.width(width) //图片宽
.height(height) //图片高
.model(request.getModel()) //使用的模型
.build();
// 构建完整的提示词
String fullPrompt = _SYSTEM_PROMPT _+ "\n" + request.getPrompt();
// 构建图片生成请求
ImagePrompt imagePrompt = new ImagePrompt(fullPrompt, options);
// 调用AI生成图片
ImageResponse response = imageModel.call(imagePrompt);
// 返回生成的图片URL
return response.getResult().getOutput().getUrl();
}
1、通过 String[] dimensions = request.getSize().split("x"); 用 x 分隔参数传入的长和宽(1024x768),并放入 ImageOptions 中。
2、通过参数获取到使用的模型,传入 ImageOptions 中。
3、将 SYSTEM_PROMPT 和 User Prompt 进行合并,传入大模型生成图片。
4、获取返回的图片 URL,并返回给前端。
前端开发
完整的前端页面如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>智能文生图工具</title>
<style>
/* 现代简约设计风格 */
body {
font-family: 'PingFang SC', 'Microsoft YaHei', sans-serif;
margin: 0;
padding: 20px;
background-color: #f0f2f5;
color: #333;
line-height: 1.6;
}
.container {
max-width: 1200px;
margin: 0 auto;
padding: 30px;
background-color: white;
border-radius: 15px;
box-shadow: 0 4px 20px rgba(0, 0, 0, 0.08);
}
.header {
text-align: center;
margin-bottom: 40px;
}
h1 {
color: #1a1a1a;
font-size: 2.5em;
margin-bottom: 10px;
}
.subtitle {
color: #666;
font-size: 1.1em;
}
.main-content {
display: grid;
grid-template-columns: 1fr 1fr;
gap: 30px;
margin-top: 30px;
}
@media (max-width: 768px) {
.main-content {
grid-template-columns: 1fr;
}
}
.input-section {
padding: 20px;
background-color: #f8f9fa;
border-radius: 10px;
}
.example-prompts {
margin-bottom: 20px;
padding: 15px;
background-color: #e6f7ff;
border-radius: 8px;
border-left: 4px solid #1890ff;
}
.example-prompts h3 {
margin-top: 0;
color: #1890ff;
}
.example-item {
padding: 10px;
margin: 10px 0;
background-color: white;
border-radius: 6px;
cursor: pointer;
transition: all 0.3s;
}
.example-item:hover {
transform: translateX(5px);
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.1);
}
textarea {
width: 100%;
height: 150px;
padding: 15px;
border: 2px solid #e8e8e8;
border-radius: 8px;
resize: vertical;
font-size: 16px;
margin-bottom: 20px;
transition: border-color 0.3s;
}
textarea:focus {
border-color: #1890ff;
outline: none;
}
.button-group {
display: flex;
gap: 10px;
margin-bottom: 20px;
}
.optimize-btn {
background-color: #52c41a;
color: white;
border: none;
padding: 12px 25px;
border-radius: 8px;
cursor: pointer;
font-size: 16px;
flex: 1;
transition: all 0.3s;
}
.optimize-btn:hover {
background-color: #389e0d;
transform: translateY(-2px);
}
.optimize-btn:disabled {
background-color: #d9d9d9;
cursor: not-allowed;
transform: none;
}
.generate-btn {
flex: 2;
background-color: #1890ff;
color: white;
border: none;
padding: 12px 25px;
border-radius: 8px;
cursor: pointer;
font-size: 16px;
transition: all 0.3s;
}
.generate-btn:hover {
background-color: #096dd9;
transform: translateY(-2px);
}
.generate-btn:disabled {
background-color: #d9d9d9;
cursor: not-allowed;
transform: none;
}
.result-section {
padding: 20px;
background-color: white;
border-radius: 10px;
border: 2px solid #f0f0f0;
}
.result-image {
width: 100%;
border-radius: 8px;
display: none;
margin-top: 20px;
}
.loading {
display: none;
text-align: center;
padding: 20px;
}
.loading-spinner {
border: 4px solid #f3f3f3;
border-top: 4px solid #1890ff;
border-radius: 50%;
width: 40px;
height: 40px;
animation: spin 1s linear infinite;
margin: 0 auto;
}
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
.error-message {
color: #ff4d4f;
text-align: center;
margin-top: 10px;
display: none;
}
.advanced-options {
margin-top: 20px;
padding: 15px;
background-color: #f8f9fa;
border-radius: 8px;
}
.advanced-options summary {
font-weight: bold;
cursor: pointer;
}
.form-group {
margin-bottom: 10px;
}
.form-group label {
display: block;
margin-bottom: 5px;
}
.form-group select,
.form-group input {
width: 100%;
padding: 8px;
border: 1px solid #e8e8e8;
border-radius: 4px;
}
.form-text {
font-size: 0.9em;
color: #666;
margin-top: 4px;
}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>智能文生图工具</h1>
<p class="subtitle">基于AI技术,将文字描述转换为精美图片</p>
</div>
<div class="main-content">
<div class="input-section">
<div class="example-prompts">
<h3>示例提示语</h3>
<div class="example-item" onclick="useExample(1)">
"时尚简约风格的夏季女装展示,主色调为浅蓝色,模特穿着短裙微笑,背景有海滩元素"
</div>
<div class="example-item" onclick="useExample(2)">
"复古风手工串珠项链特写,暖色调灯光效果,木质背景"
</div>
</div>
<textarea id="promptInput"
placeholder="请描述您想要生成的图片效果,可以包含以下要素: 1. 主体内容描述 2. 画面风格(如:简约、奢华、复古等) 3. 色彩倾向 4. 构图布局 5. 环境或背景元素"></textarea>
<div class="button-group">
<button id="optimizeBtn" class="optimize-btn" onclick="optimizePrompt()">优化提示词</button>
<button id="generateBtn" class="generate-btn" onclick="generateImage()">生成图片</button>
</div>
<details class="advanced-options">
<summary>高级选项</summary>
<div class="form-group">
<label for="imageModel">AI模型</label>
<select id="imageModel">
<option value="cogview-3-flash">CogView-3-Flash(免费版)</option>
<option value="cogview-4">CogView-4(付费版 - 效果更好)</option>
</select>
<small class="form-text">CogView-3-Flash为免费版本,CogView-4为付费版本但效果更好</small>
</div>
<div class="form-group">
<label for="imageSize">图片尺寸</label>
<select id="imageSize">
<option value="1024x1024">1024x1024(推荐)</option>
<option value="768x768">768x768</option>
<option value="1536x1536">1536x1536</option>
<option value="2048x2048">2048x2048(超高清)</option>
</select>
<small class="form-text">尺寸越大,生成时间越长,建议根据实际需求选择</small>
</div>
</details>
</div>
<div class="result-section">
<div id="loading" class="loading">
<div class="loading-spinner"></div>
<p>正在生成图片,请稍候...</p>
</div>
<div id="errorMessage" class="error-message"></div>
<img id="resultImage" class="result-image" alt="生成的图片">
</div>
</div>
</div>
<script>
// 使用示例提示语
function useExample(index) {
const examples = {
1: "时尚简约风格的夏季女装展示,主色调为浅蓝色,模特穿着短裙微笑,背景有海滩元素",
2: "复古风手工串珠项链特写,暖色调灯光效果,木质背景"
};
_document_.getElementById('promptInput').value = examples[index];
}
// 生成图片
async function generateImage() {
const promptInput = _document_.getElementById('promptInput');
const generateBtn = _document_.getElementById('generateBtn');
const loading = _document_.getElementById('loading');
const resultImage = _document_.getElementById('resultImage');
const errorMessage = _document_.getElementById('errorMessage');
if (!promptInput.value.trim()) {
errorMessage.textContent = '请输入图片描述!';
errorMessage.style.display = 'block';
return;
}
// 重置状态
errorMessage.style.display = 'none';
generateBtn.disabled = true;
loading.style.display = 'block';
resultImage.style.display = 'none';
try {
const response = await fetch('/text-to-image/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: _JSON_.stringify({
prompt: promptInput.value,
size: _document_.getElementById('imageSize').value,
model: _document_.getElementById('imageModel').value
})
});
const data = await response.json();
if (data.code !== 0) {
throw new Error(data.message || '生成失败,请重试');
}
// 显示生成的图片
resultImage.src = data.data;
resultImage.style.display = 'block';
} catch (error) {
errorMessage.textContent = error.message;
errorMessage.style.display = 'block';
} finally {
loading.style.display = 'none';
generateBtn.disabled = false;
}
}
// 优化提示词
async function optimizePrompt() {
const promptInput = _document_.getElementById('promptInput');
const optimizeBtn = _document_.getElementById('optimizeBtn');
const errorMessage = _document_.getElementById('errorMessage');
if (!promptInput.value.trim()) {
errorMessage.textContent = '请输入图片描述!';
errorMessage.style.display = 'block';
return;
}
// 禁用按钮
optimizeBtn.disabled = true;
optimizeBtn.textContent = '优化中...';
try {
const response = await fetch('/text-to-image/optimize-prompt', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: _JSON_.stringify({
prompt: promptInput.value
})
});
const data = await response.json();
if (data.code !== 0) {
throw new Error(data.message || '优化失败,请重试');
}
promptInput.value = data.data;
errorMessage.style.display = 'none';
} catch (error) {
errorMessage.textContent = error.message;
errorMessage.style.display = 'block';
} finally {
optimizeBtn.disabled = false;
optimizeBtn.textContent = '优化提示词';
}
}
// 监听文本框输入,实时更新按钮状态
_document_.getElementById('promptInput').addEventListener('input', function (e) {
const generateBtn = _document_.getElementById('generateBtn');
generateBtn.disabled = !e.target.value.trim();
});
</script>
</body>
</html>
核心代码在 generateImage 的异步函数中,其主要作用是根据用户输入的文本描述生成相应的图片。
三、总结
这一章围绕大模型文生图技术与 Spring AI 展开,重点介绍了智能文生图工具的相关内容:
提示词优化
- 重要性:提示词是大模型生成图片的关键,直接影响生成图片的质量与精准度。优化提示词能引导模型生成更符合用户预期的图像。
- 优化方法:包括保持核心意图、添加细节描述、使用专业术语、确保描述清晰具体且富有创意等,同时要使优化后的提示词更易被 AI 理解和执行。
- 大模型的优势:大模型凭借其广泛知识和语言理解能力,可明确语义、消除歧义,还能构建合理框架、梳理因果关系,从而提升提示词的质量。
Spring AI 在文生图功能开发中的作用
- 用户交互:用户输入文字描述,通过前端页面输入提示词、选择图片尺寸和 AI 模型等参数。
- 后端处理:后端接收前端请求,调用大模型接口进行提示词优化和文生图处理。例如,使用 Spring AI 的
ImageModel相关功能,根据用户选择的模型和参数,构建图片生成请求并获取生成的图片 URL。 - 大模型的多样性:Spring AI 支持多种大模型,如智谱 AI、千帆 AI、OpenAI Image Generation、Azure OpenAI Image Generation 等,不同模型在功能和参数配置上可能有所不同。

















 2356
2356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









