






LSTM+word2vec电影情感分析
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from nltk.corpus import stopwords
from plot_result import plot_history
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
data = pd.read_csv('dataset/labeledTrainData.tsv', sep='\t', usecols=['sentiment', 'review'])
data.head()
| sentiment | review | |
|---|---|---|
| 0 | 1 | With all this stuff going down at the moment w... |
| 1 | 1 | \The Classic War of the Worlds\" by Timothy Hi... |
| 2 | 0 | The film starts with a manager (Nicholas Bell)... |
| 3 | 0 | It must be assumed that those who praised this... |
| 4 | 1 | Superbly trashy and wondrously unpretentious 8... |
# 定义函数进行简单的文本处理
def detail_text(w):
import re
# text = re.sub(r"([?,.!])", r" \1", w)
# text = re.sub(r'[" "]+', " ", text)
# text = re.sub(r'[^a-zA-Z?,!.]+', " ", text)
token = re.compile('[A-Za-z]+|[!?,.()]')
text = token.findall(w)
new_text = [word.lower() for word in text if word not in stopwords.words('english') and len(word) > 2]
return new_text
data['review'] = data.review.apply(detail_text)
data['review'][0]
['with',
'stuff',
'going',
'moment',
'started',
························
························
'stupid',
'guy',
'one',
'sickest',
'liars',
'hope',
'latter']
# 构建x y
sentences = data.review.values
y = data.sentiment.values
sentences_train, sentences_test, y_train, y_test = train_test_split(sentences, y, test_size=0.25, random_state=1000)
max_words = 20000
# 创建Tokenizer对象
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(sentences_train)
tokenizer.fit_on_texts(sentences_test)
# 将text转成序列
X_train = tokenizer.texts_to_sequences(sentences_train)
X_test = tokenizer.texts_to_sequences(sentences_test)
print(X_train[0])
[271, 286, 13, 17, 3, 834, 6, 552, 14, 565, 437, 7, 4, 107, 17, 3, 2362, 244, 5130, 133, 311, 1100, 2669, 540, 942, 5130, 1283, 3025, 581, 750, 943, 944, 6665, 5131, 6666, 5132, 46, 51, 26, 386, 3026, 6667, 6665, 5131, 3497, 6668, 1654, 6669, 5133, 945, 942, 366, 387, 1655, 1284, 62, 290, 9578, 438, 1041, 6670, 245, 472, 134, 122, 515, 2363, 9579, 863, 12, 105, 116, 138, 344, 3498, 348, 18, 327, 3499, 9580, 41, 1799, 6671, 2142, 607, 22, 2670, 93, 17, 1154, 1042, 3, 3500, 117, 3500, 1800, 1043, 140, 277, 1100, 5134, 4231, 300, 66, 1801, 301, 96, 1101, 1101, 516, 5130, 141, 291, 2671, 6672, 311, 70, 133, 9581, 751, 49, 192, 337, 73, 66, 2143, 6673, 35, 123, 946, 2144, 699, 9582, 24, 903, 161, 439, 9583, 947, 2672, 2, 1363, 1102, 52, 327, 194, 9584, 1364, 226, 234, 566, 150, 499, 388, 2145, 6674, 6675, 2146, 1365, 176, 185, 656, 1366, 1367, 9585, 353, 52, 236, 1560, 9586, 5135, 344, 43, 54, 328, 806, 292, 2, 29, 9587, 1155, 948, 141, 277, 2364, 140, 4232, 1214, 9588, 2365, 176, 135, 71, 608, 18, 197, 2366, 23, 2, 24, 5, 499, 1368, 3, 108, 1368, 3027, 5134, 5136, 105, 2367, 440, 11, 1965, 235, 4, 680]
# 进行pad_sequences
maxlen = 150
X_train = keras.preprocessing.sequence.pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, padding='post', maxlen=maxlen)
vocab_size = len(tokenizer.word_index) + 1
print("vocab_size", vocab_size)
vocab_size 17909
# 使用训练好的word2vec语料库glove.6B.50d.txt 构建词向量 过滤无关词语
def create_embedding_matrix(filepath, word_index, embedding_dim):
"""
将自己的词对应的向量在 被人训练好的文本向量模型中找到 对应起来
"""
vocab_size = len(word_index) + 1 # keras文档中指定需要+1
embedding_matrix = np.zeros((vocab_size, embedding_dim))
with open(filepath, encoding='utf-8') as f:
for line in f:
word, *vector = line.split()
if word in word_index:
idx = word_index[word]
embedding_matrix[idx] = np.array(vector, dtype=np.float32)[:embedding_dim]
return embedding_matrix
# 构建模型
embedding_dim = 50
embedding_matrix = create_embedding_matrix('dataset/glove.6B.50d.txt', tokenizer.word_index, embedding_dim)
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix], # 权重不再是随机指定的向量 而是word2vec词向量
# input_length=max_len,
trainable=True)) # 词嵌入层继续训练
model.add(keras.layers.LSTM(64, return_sequences=True)) # 输出64维
model.add(keras.layers.LSTM(64, return_sequences=True))
model.add(keras.layers.LSTM(128, return_sequences=False))
model.add(keras.layers.Dense(10, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
opt = keras.optimizers.Adam(lr=0.001)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(X_train, y_train,
epochs=50,
verbose=1,
# callbacks=[keras.callbacks.EarlyStopping(patience=2, monitor='val_loss')],
validation_data=(X_test, y_test),
batch_size=64)
loss_train5, accuracy = model.evaluate(X_train, y_train, verbose=False) # verbose=False 不打印训练结果
print("Training Accuracy: {:.4f}".format(accuracy))
loss_test5, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history, name='base_Embedding Layer')
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 50) 895450
_________________________________________________________________
lstm (LSTM) (None, None, 64) 29440
_________________________________________________________________
lstm_1 (LSTM) (None, None, 64) 33024
_________________________________________________________________
lstm_2 (LSTM) (None, 128) 98816
_________________________________________________________________
dense (Dense) (None, 10) 1290
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 1,058,031
Trainable params: 1,058,031
Non-trainable params: 0
_________________________________________________________________
Epoch 1/50
12/12 [==============================] - 7s 361ms/step - loss: 0.6918 - acc: 0.4593 - val_loss: 0.6883 - val_acc: 0.6000
Epoch 2/50
12/12 [==============================] - 3s 265ms/step - loss: 0.6914 - acc: 0.5462 - val_loss: 0.6868 - val_acc: 0.5760
Epoch 3/50
12/12 [==============================] - 3s 263ms/step - loss: 0.6801 - acc: 0.5928 - val_loss: 0.6753 - val_acc: 0.6280
Epoch 4/50
12/12 [==============================] - 3s 267ms/step - loss: 0.6393 - acc: 0.5929 - val_loss: 0.6576 - val_acc: 0.5960
Epoch 5/50
12/12 [==============================] - 3s 296ms/step - loss: 0.5889 - acc: 0.6644 - val_loss: 0.6133 - val_acc: 0.6840
Epoch 6/50
12/12 [==============================] - 4s 339ms/step - loss: 0.5103 - acc: 0.7634 - val_loss: 0.6980 - val_acc: 0.6440
Epoch 7/50
12/12 [==============================] - 4s 336ms/step - loss: 0.5457 - acc: 0.7641 - val_loss: 0.7750 - val_acc: 0.5800
Epoch 8/50
12/12 [==============================] - 4s 361ms/step - loss: 0.6201 - acc: 0.6423 - val_loss: 0.6544 - val_acc: 0.5800
Epoch 9/50
12/12 [==============================] - 4s 327ms/step - loss: 0.5474 - acc: 0.6986 - val_loss: 0.6293 - val_acc: 0.7120
Epoch 10/50
12/12 [==============================] - 4s 359ms/step - loss: 0.4952 - acc: 0.7804 - val_loss: 0.7398 - val_acc: 0.5320
Epoch 11/50
12/12 [==============================] - 4s 337ms/step - loss: 0.5603 - acc: 0.6619 - val_loss: 0.7509 - val_acc: 0.5840
Epoch 12/50
12/12 [==============================] - 4s 327ms/step - loss: 0.4849 - acc: 0.7315 - val_loss: 0.6508 - val_acc: 0.7200
Epoch 13/50
12/12 [==============================] - 4s 334ms/step - loss: 0.4055 - acc: 0.8081 - val_loss: 0.6827 - val_acc: 0.7120
Epoch 14/50
12/12 [==============================] - 4s 353ms/step - loss: 0.3476 - acc: 0.8556 - val_loss: 0.7940 - val_acc: 0.6400
Epoch 15/50
12/12 [==============================] - 4s 324ms/step - loss: 0.4679 - acc: 0.7623 - val_loss: 0.6620 - val_acc: 0.7280
Epoch 16/50
12/12 [==============================] - 4s 369ms/step - loss: 0.3791 - acc: 0.8254 - val_loss: 0.7203 - val_acc: 0.6760
Epoch 17/50
12/12 [==============================] - 4s 376ms/step - loss: 0.3724 - acc: 0.8902 - val_loss: 0.6440 - val_acc: 0.6720
Epoch 18/50
12/12 [==============================] - 4s 336ms/step - loss: 0.3935 - acc: 0.8351 - val_loss: 0.6178 - val_acc: 0.7480
Epoch 19/50
12/12 [==============================] - 4s 334ms/step - loss: 0.2949 - acc: 0.9042 - val_loss: 0.7082 - val_acc: 0.7400
Epoch 20/50
12/12 [==============================] - 4s 336ms/step - loss: 0.2276 - acc: 0.9234 - val_loss: 0.7059 - val_acc: 0.7440
Epoch 21/50
12/12 [==============================] - 4s 325ms/step - loss: 0.2561 - acc: 0.8967 - val_loss: 0.9920 - val_acc: 0.6080
Epoch 22/50
12/12 [==============================] - 4s 324ms/step - loss: 0.3445 - acc: 0.8129 - val_loss: 0.7695 - val_acc: 0.7280
Epoch 23/50
12/12 [==============================] - 4s 322ms/step - loss: 0.3999 - acc: 0.7718 - val_loss: 0.6474 - val_acc: 0.6000
Epoch 24/50
12/12 [==============================] - 4s 330ms/step - loss: 0.3869 - acc: 0.7256 - val_loss: 1.0462 - val_acc: 0.5400
Epoch 25/50
12/12 [==============================] - 4s 348ms/step - loss: 0.5651 - acc: 0.6890 - val_loss: 0.7888 - val_acc: 0.7440
Epoch 26/50
12/12 [==============================] - 4s 366ms/step - loss: 0.4958 - acc: 0.8671 - val_loss: 0.5955 - val_acc: 0.7360
Epoch 27/50
12/12 [==============================] - 4s 354ms/step - loss: 0.3138 - acc: 0.9130 - val_loss: 0.7231 - val_acc: 0.7160
Epoch 28/50
12/12 [==============================] - 4s 330ms/step - loss: 0.2183 - acc: 0.9386 - val_loss: 0.7489 - val_acc: 0.7360
Epoch 29/50
12/12 [==============================] - 4s 321ms/step - loss: 0.2112 - acc: 0.9353 - val_loss: 0.8334 - val_acc: 0.7360
Epoch 30/50
12/12 [==============================] - 4s 320ms/step - loss: 0.2336 - acc: 0.9256 - val_loss: 0.8929 - val_acc: 0.6800
Epoch 31/50
12/12 [==============================] - 4s 325ms/step - loss: 0.2843 - acc: 0.8972 - val_loss: 0.8821 - val_acc: 0.7280
Epoch 32/50
12/12 [==============================] - 4s 324ms/step - loss: 0.2211 - acc: 0.9382 - val_loss: 0.8275 - val_acc: 0.6640
Training Accuracy: 0.5387
Testing Accuracy: 0.5200
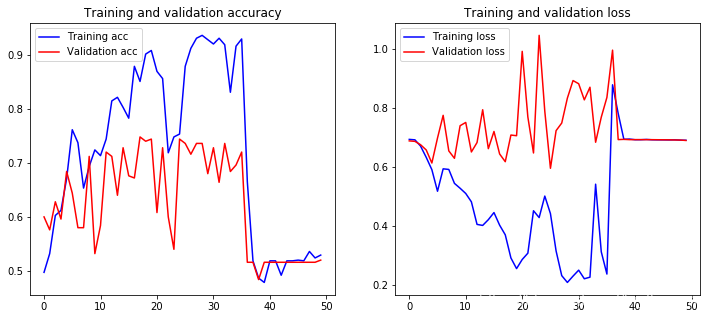
总结
上面LSTM模型结果不理想 最主要的原因是数据太少
下面是优化代码
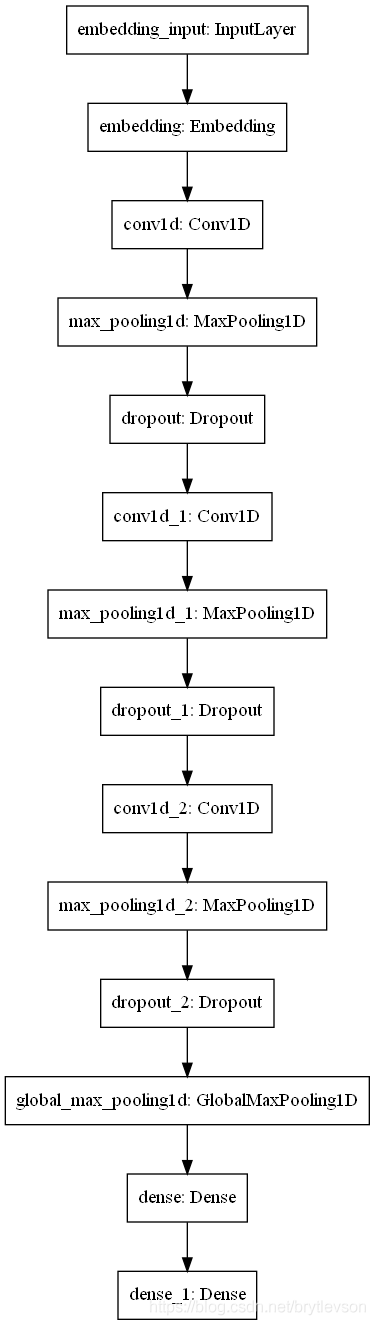
# 使用CNN
model = keras.Sequential()
# Embedding 输入一般都是语料库大小 (None, 30, 50) 每行文本输入不限制 每次输入30个词 每个词50个维度
# model.add(keras.layers.Embedding(input_dim=max_words, output_dim=embedding_dim, input_length=maxlen))
model.add(keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=maxlen))
model.add(keras.layers.Conv1D(64, 11, activation='relu', padding='same'))
model.add(keras.layers.MaxPooling1D())
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Conv1D(128, 11, activation='relu', padding='same'))
model.add(keras.layers.MaxPooling1D())
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Conv1D(256, 11, activation='relu', padding='same'))
model.add(keras.layers.MaxPooling1D())
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.GlobalMaxPool1D()) # 全局池化 变成二维的
model.add(keras.layers.Dense(10, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc'])
model.summary()
# keras.utils.plot_model(model, to_file='model1.png')
# 训练过程中降低学习速率 理解: 连续3个epoch学习速率没下降 lr*0.5 最后不超过最低值
# callbacks = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=3, factor=0.5, min_lr=0.00001)
history = model.fit(X_train, y_train, epochs=100, batch_size=128, validation_data=(X_test, y_test))
loss_train1, accuracy = model.evaluate(X_train, y_train, verbose=False) # verbose=False 不打印训练结果
print("Training Accuracy: {:.4f}".format(accuracy))
loss_test1, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
# 可视化
plot_history(history, name='base_Embedding Layer')
# 接着上次训练的步骤训练
callbacks1 = keras.callbacks.EarlyStopping(patience=2, monitor='val_loss')
# 设置保存最优参数
checkpoint = keras.callbacks.ModelCheckpoint(
filepath='./model1.h5',
monitor="val_loss",
verbose=1,
save_best_only=True,
mode="min",
)
callbacks = [callbacks1, checkpoint]
history = model.fit(X_train, y_train, epochs=100, batch_size=128, callbacks=callbacks, validation_data=(X_test, y_test))
总结:
用全部数据跑, 训练集和验证集acc能到95%.
















 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











