






【2023.5.10】


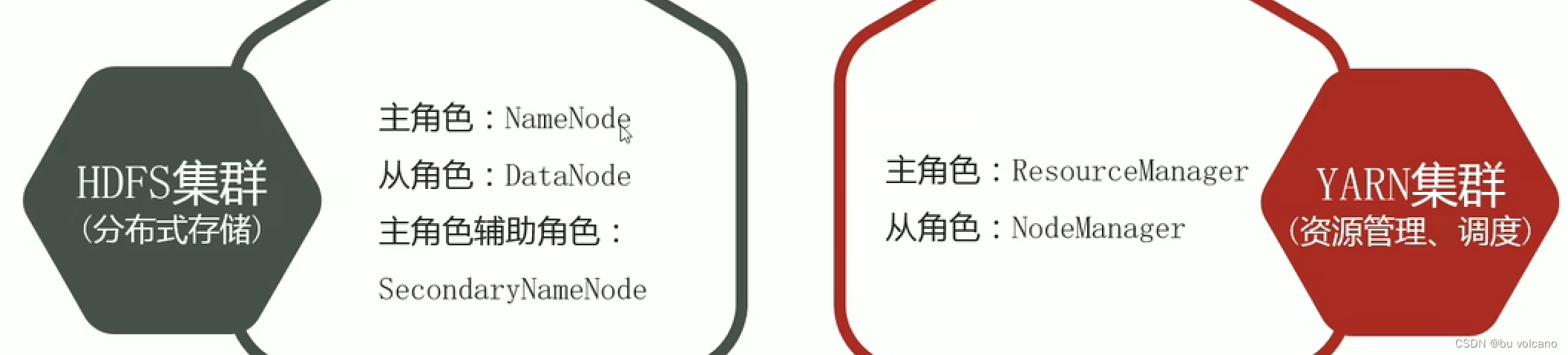
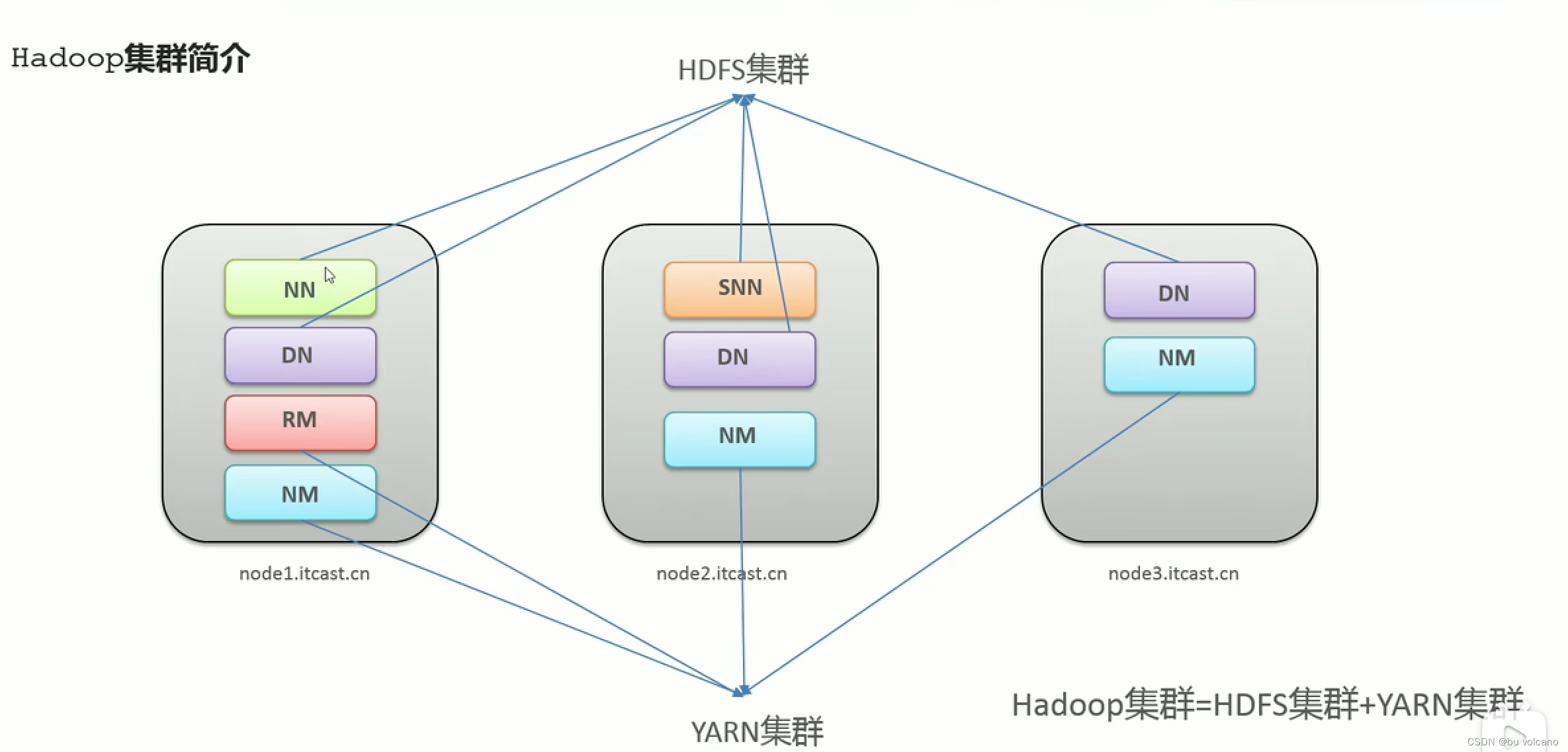
两个集群逻辑上独立,物理上在一起




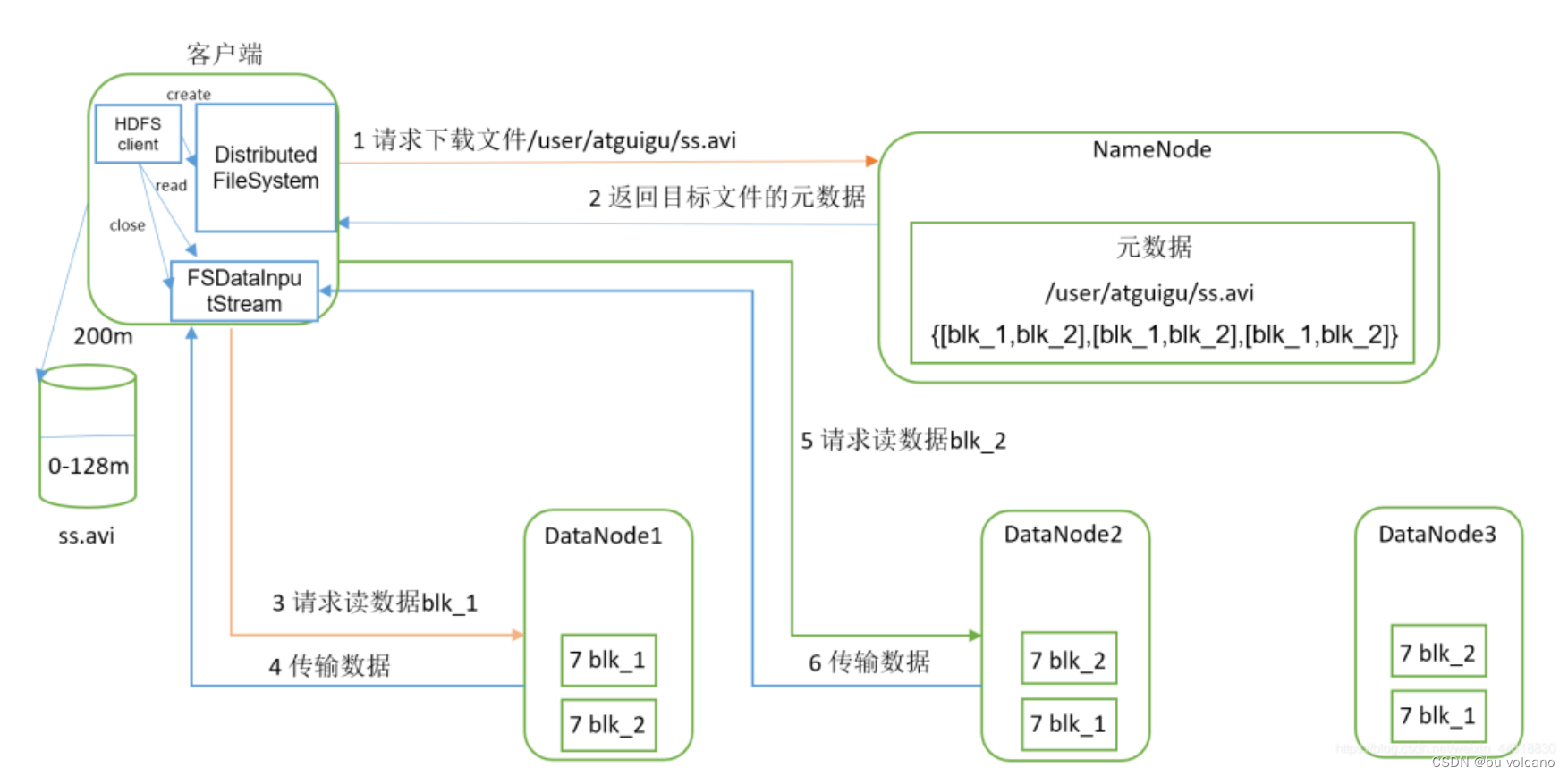
HDFS的读写流程:【5.28】
(1)写流程
①客户端向NameNode发出写文件请求。
②NameNode检查是否已存在文件、检查权限。若通过检查,响应可以上传文件。
③client端按128MB的块切分文件,向NameNode请求上传第一个Block (0-128M),请返回DataNode
④NameNode返回dn1,dn2,dn3节点,表示采用这三个节点存储数据
⑤client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
⑥将所有packet发送完毕,写完数据,关闭输输出流。
⑦client发送完成信号给NameNode。
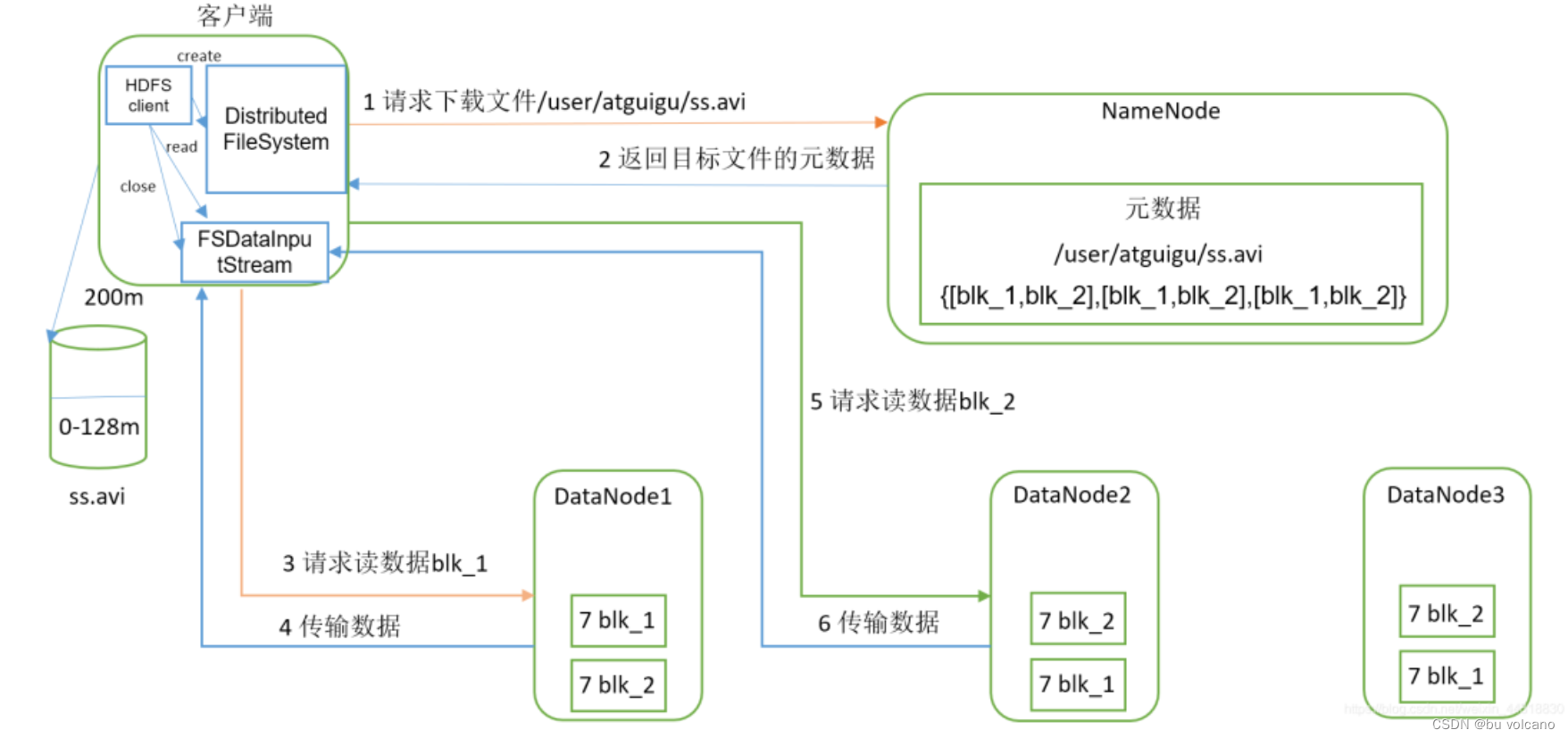
(2)读流程
①client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
②就近挑选一台datanode服务器,请求建立输入流 。
③DataNode向输入流中中写数据,以packet为单位来校验。
④关闭输入流
【5.17】

【5.20】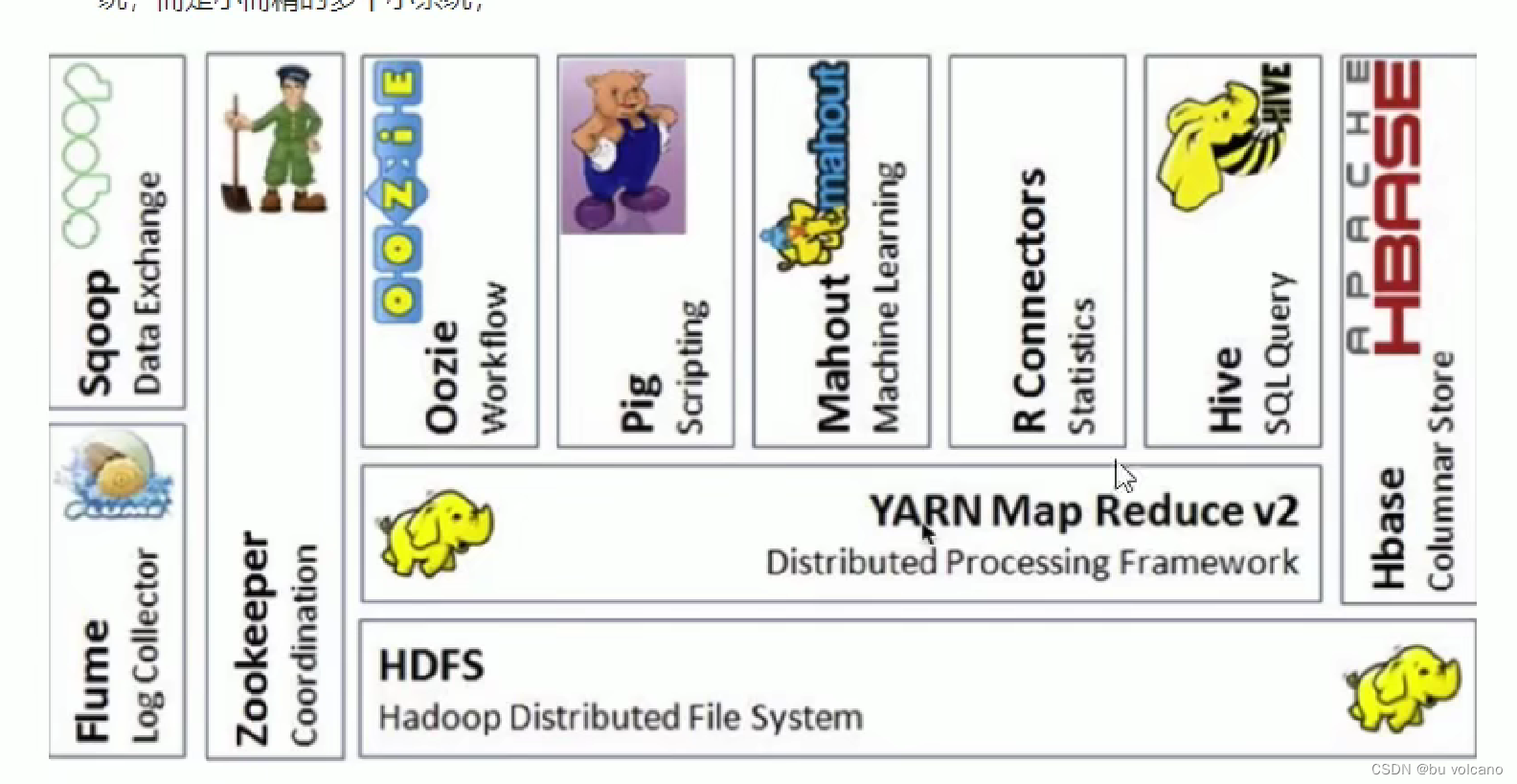
Hive架构
用户接口: shell命令行
元数据存储
数据库表都保存到那些位置上。
表中的字段名字类型
mysql derby(自带)
Drive
负责把HQL翻译成mapreduce
或者翻译成shell命令
Hive和Hadoop关系
利用hdfs存数据利用mr算
Hive只需要跟Master节点打交道不需要集群
常用命令
创建表(通过空格来切分) CREATE TABLE student(classNo string,stuNo string,score int) row format delimited fields terminated by ', ';
将数据导入表中 load data local inpath '/home/hadoop/tmp/student.txt ' overwrite into table student ;
【5.21】Sqoop
【6.10】Spark
Spark 框架模块
Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
SparkStreaming,可 以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。















 3193
3193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











