






基本概念:
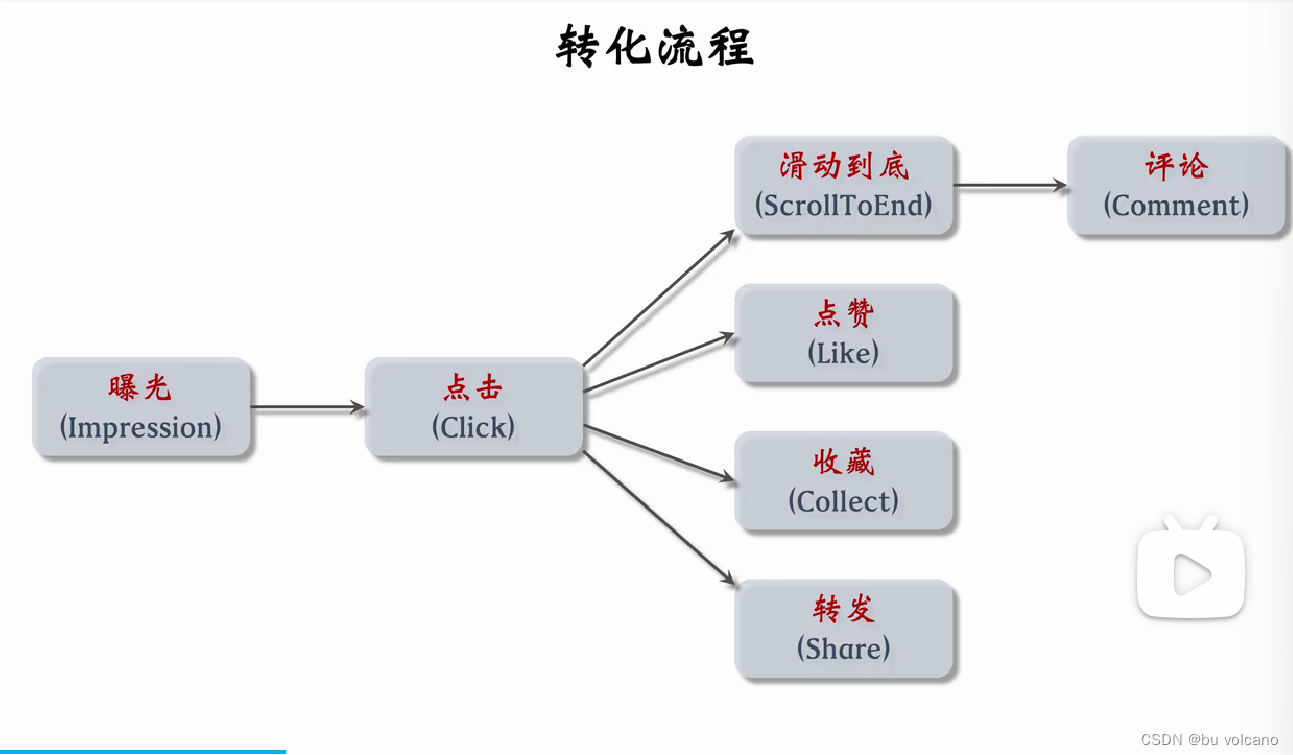


一、基本流程 王树森老师课程笔记
召回(retrieval):快速从海量数据中取回几千个用户可能感兴趣的物品。
方法:
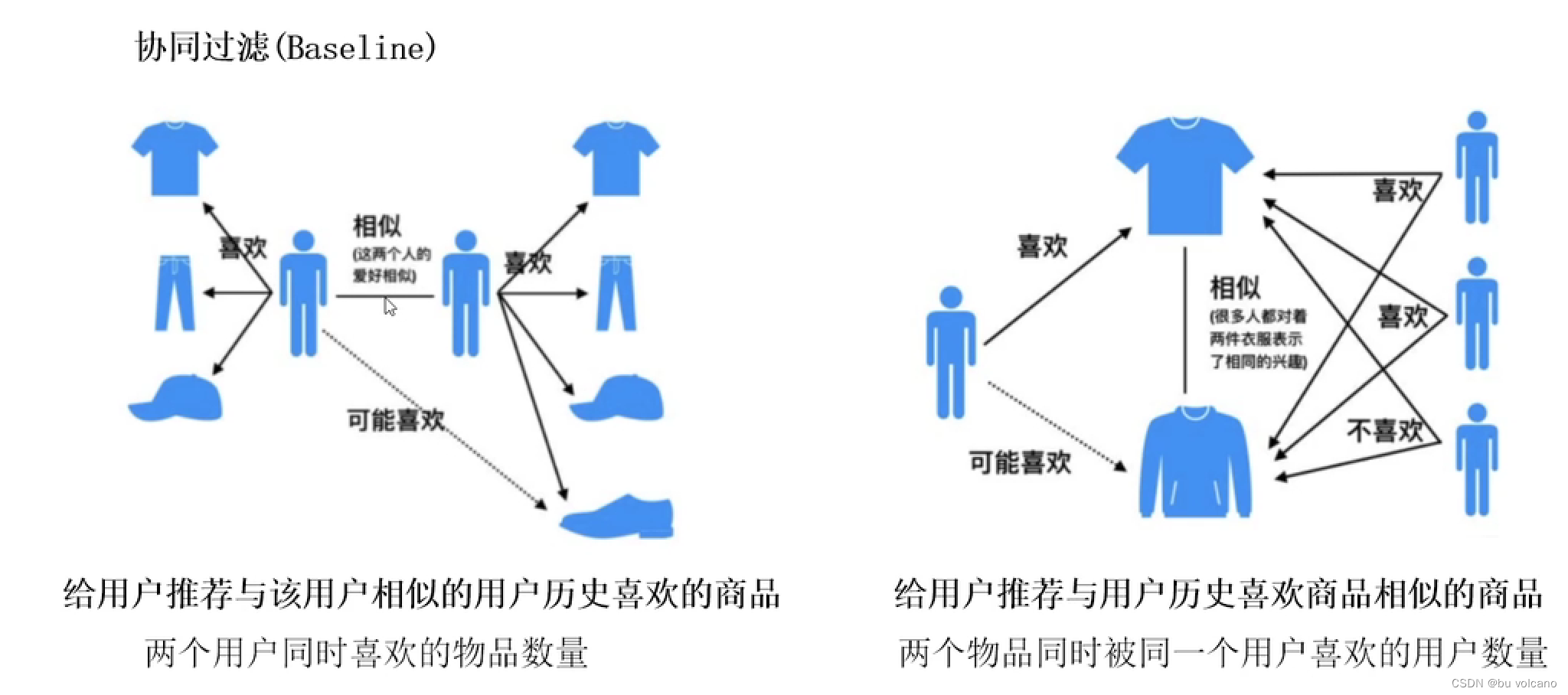
协同过滤
相似度计算:
余弦,
杰卡德
矩阵分解:
将一个稀疏的用户评分矩阵MxN分解为MxK KxN,分解出来的K就是隐语义特征
BiasSVD方法
jieba是中文分词包
hanlp情感分析工具包
关注的作者…
粗排:用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
精排:用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。
重拍:对精排结果做多样性抽样,得到几十个物品,然后用规则调整物品的排序。
方法:MMR、DPP
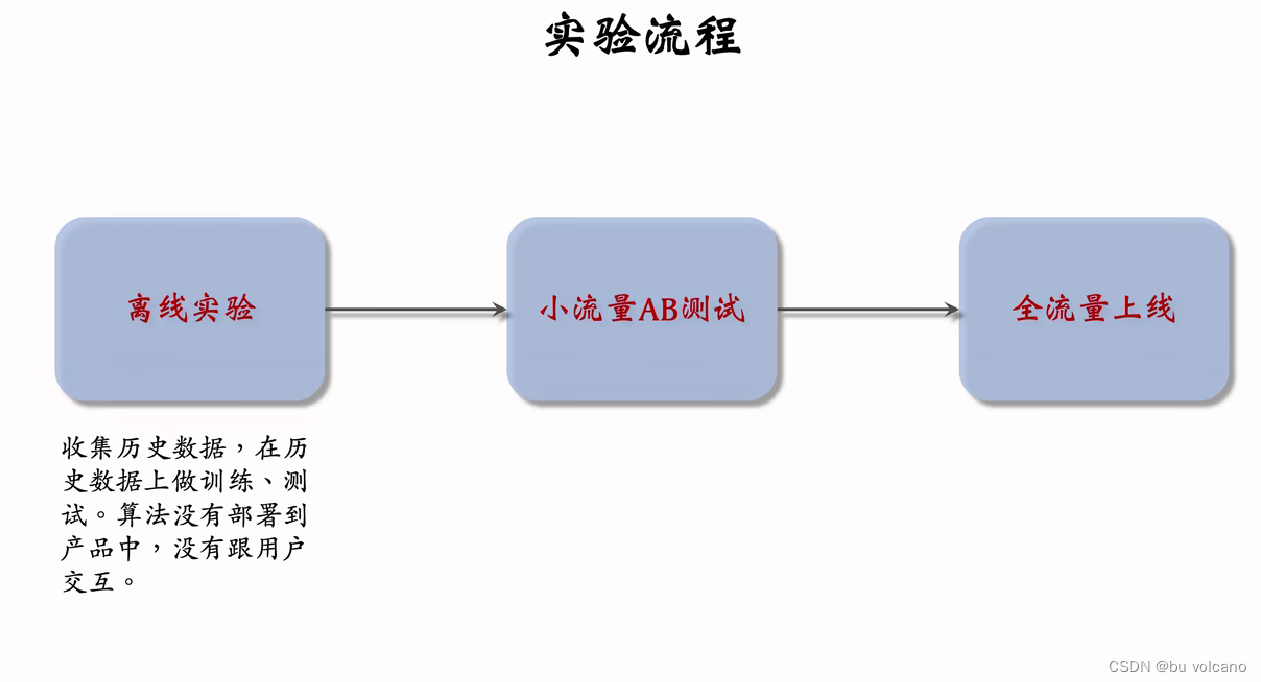
AB测试
推荐系统算法工程师的日常工作就是改进模型和策略,目标是提升推荐系统的业务指标。所有对模型和策略的改进,都需要经过线上 AB 测试,用实验数据来验证模型和策略是否有效。
1.对用户进行随机分桶 用哈希函数映射到一个整数范围中
分层实验:(同层互斥,不同层正交)
在每一个阶段可以单独使用100%的全部用户,即同一层中某一用户不能受两种召回实验
Holdout :保留10%的用户﹐完全不受实验影响﹐可以考察整个部门对业务指标的贡献。
实验推全∶新建一个推全层﹐与其他层正交。
反转实验︰在新的推全层上﹐保留一个小的反转桶﹐使用旧策略·长期观测新旧策略的diff o
一、召回

协同压缩算法
基于用户的

log为了缩小最热门和最冷门的差距
基于物品的:
同时喜欢物品1,2的人÷喜欢物品1和物品2人的总和
Swing:
额外考虑重合的用户是否来自一个小圈子。
·同时喜欢两个物品的用户记作集合V 。
·对于V中的用户u1和u2,重合度记作overlap(u1,u2)
·两个用户重合度大,则可能来自一个小圈子,放在公式分母上来降低权重。
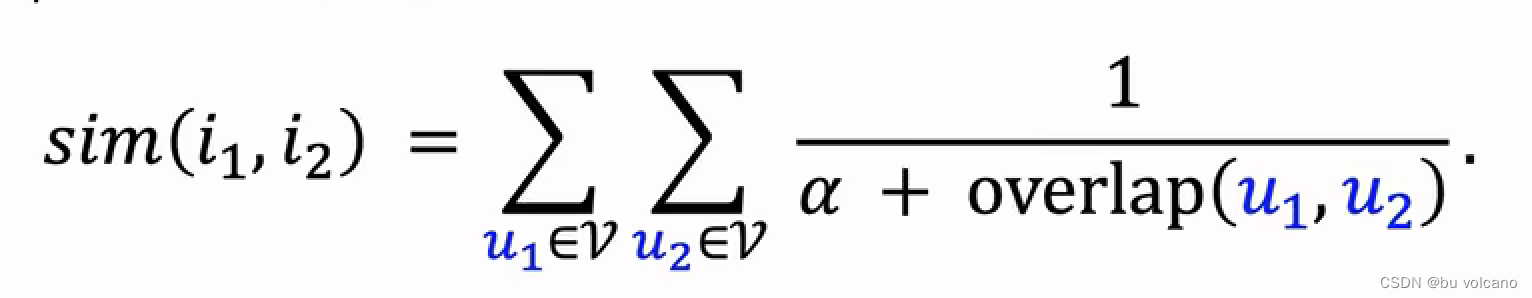
矩阵补充模型【5.8】
双塔模型:也叫 DSSM,是推荐系统中最重要的召回通道,没有之一
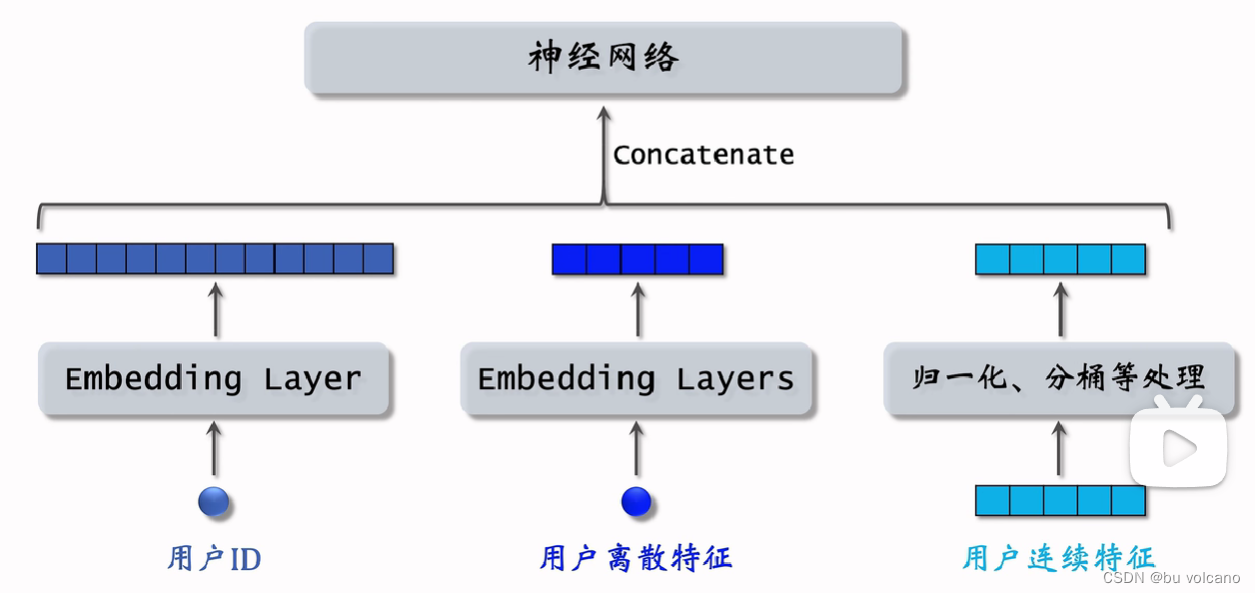
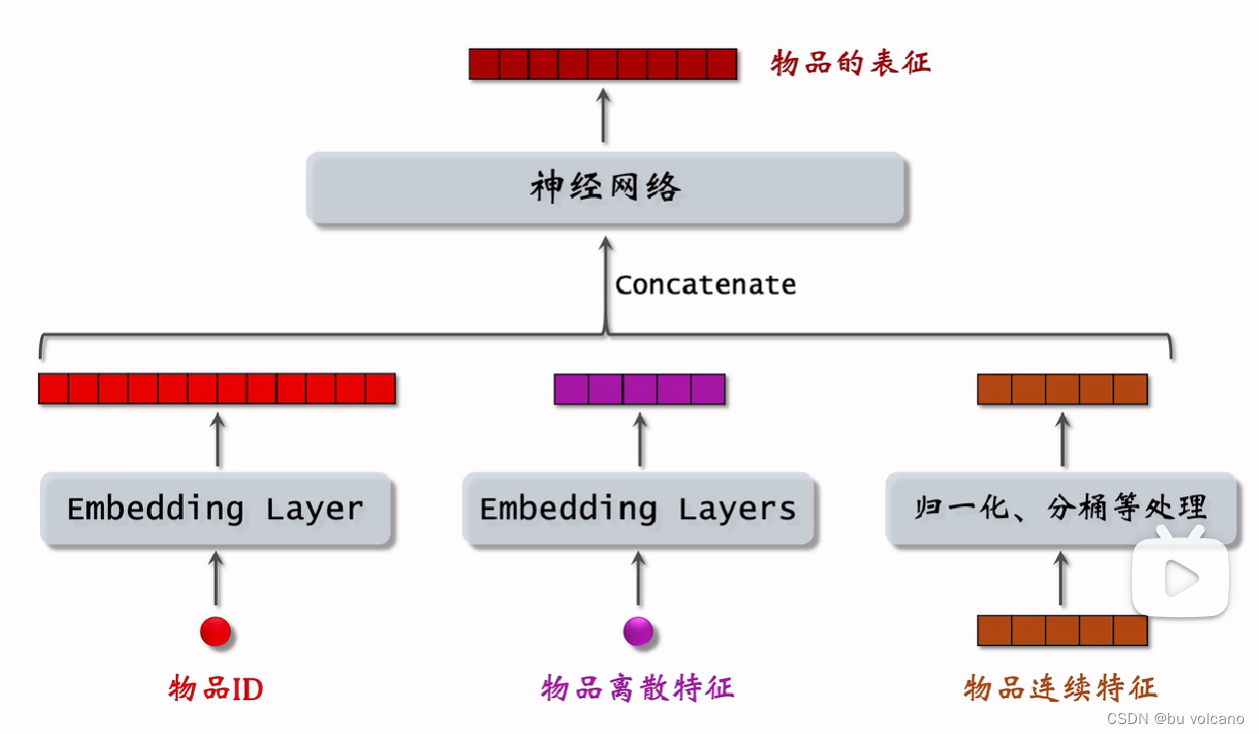
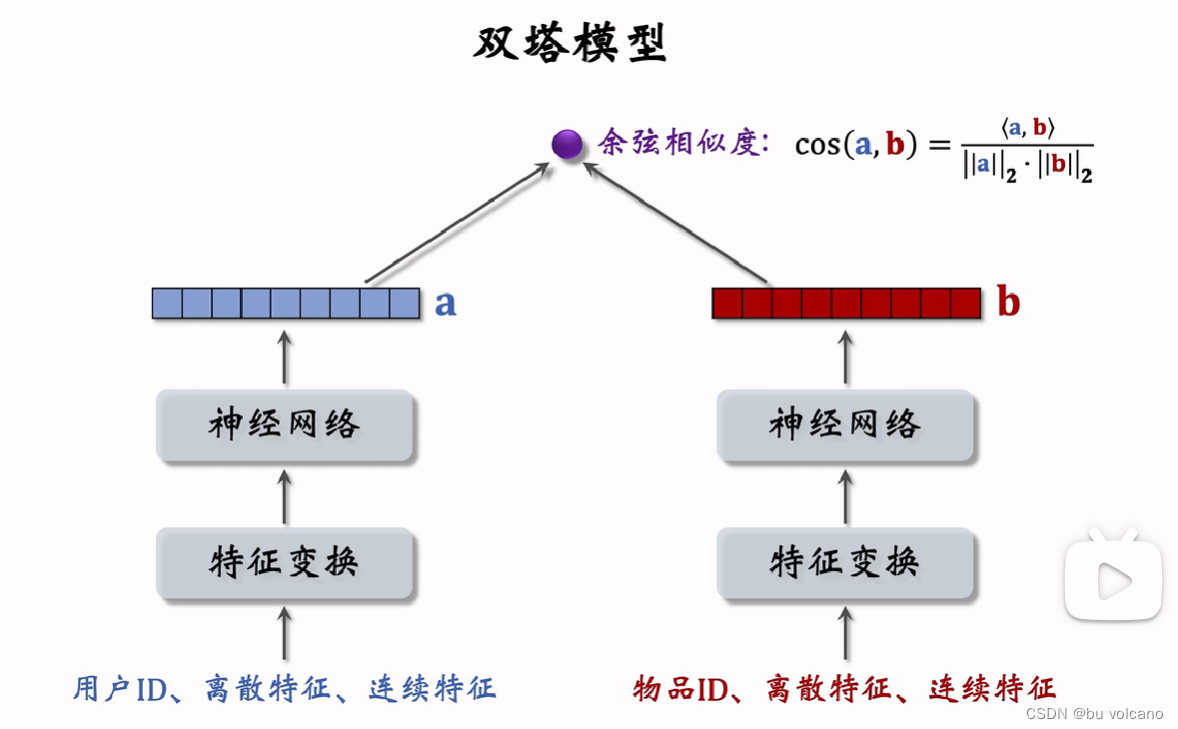


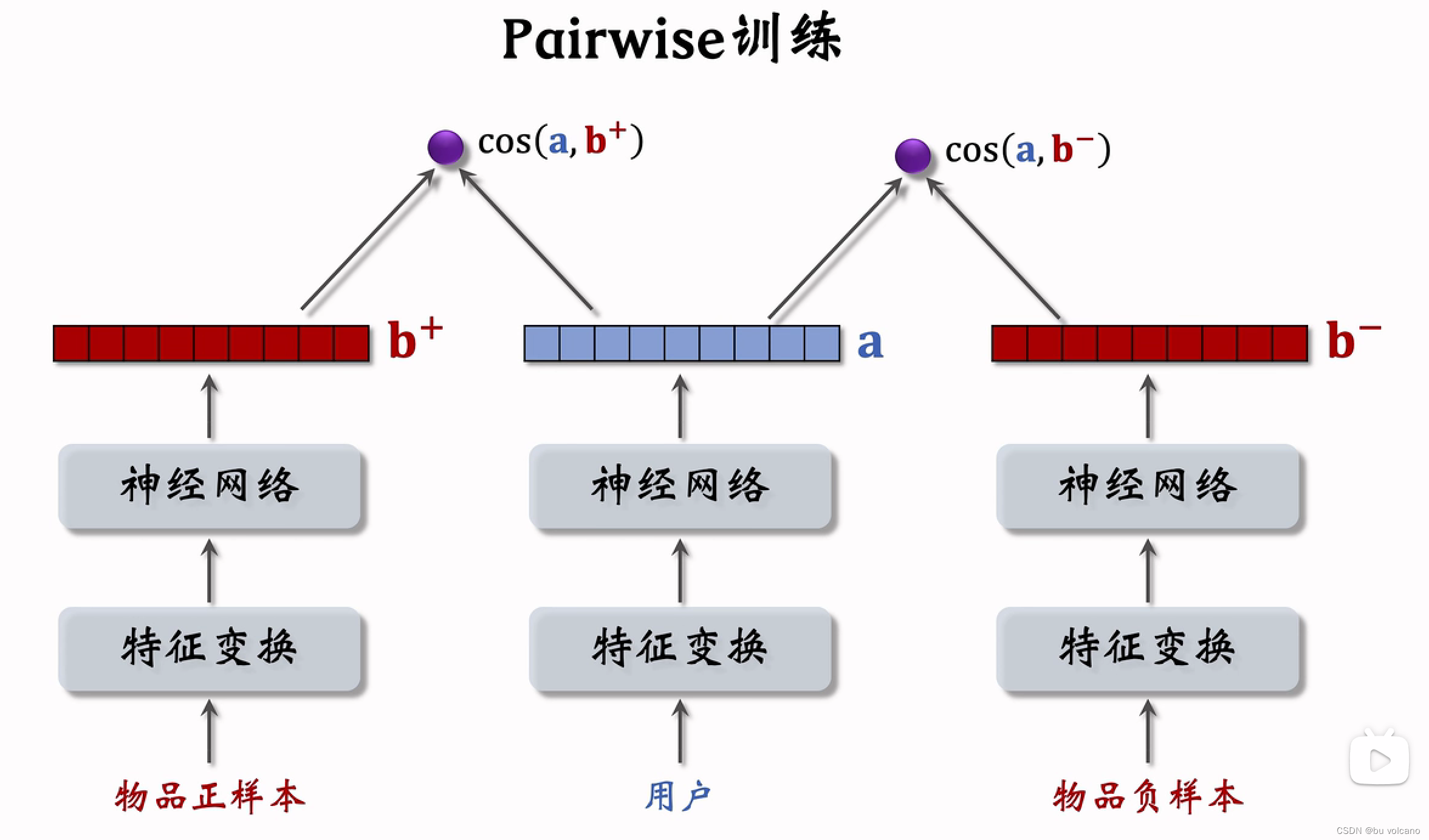

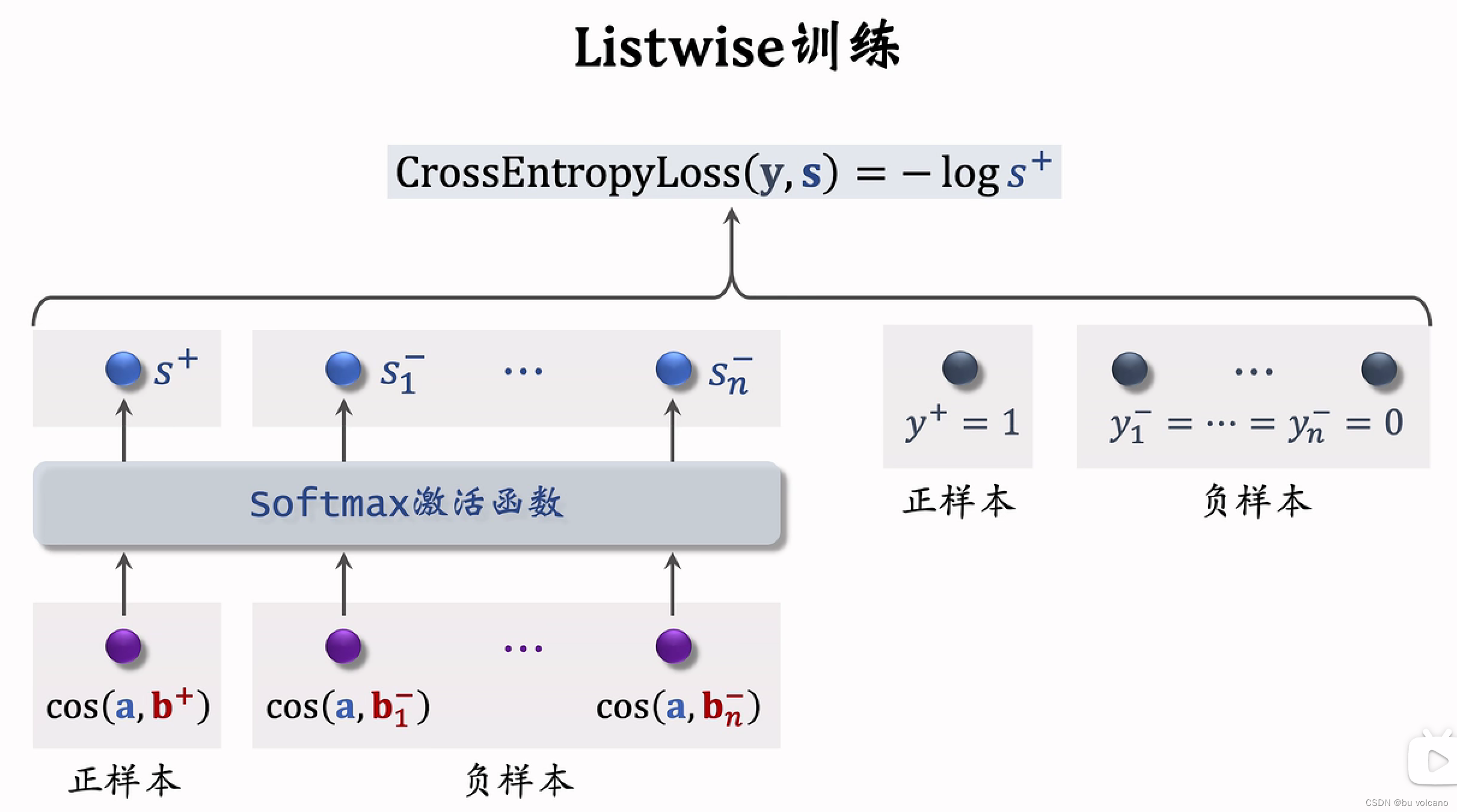
后期融合是召回
前期融合是粗排或精排
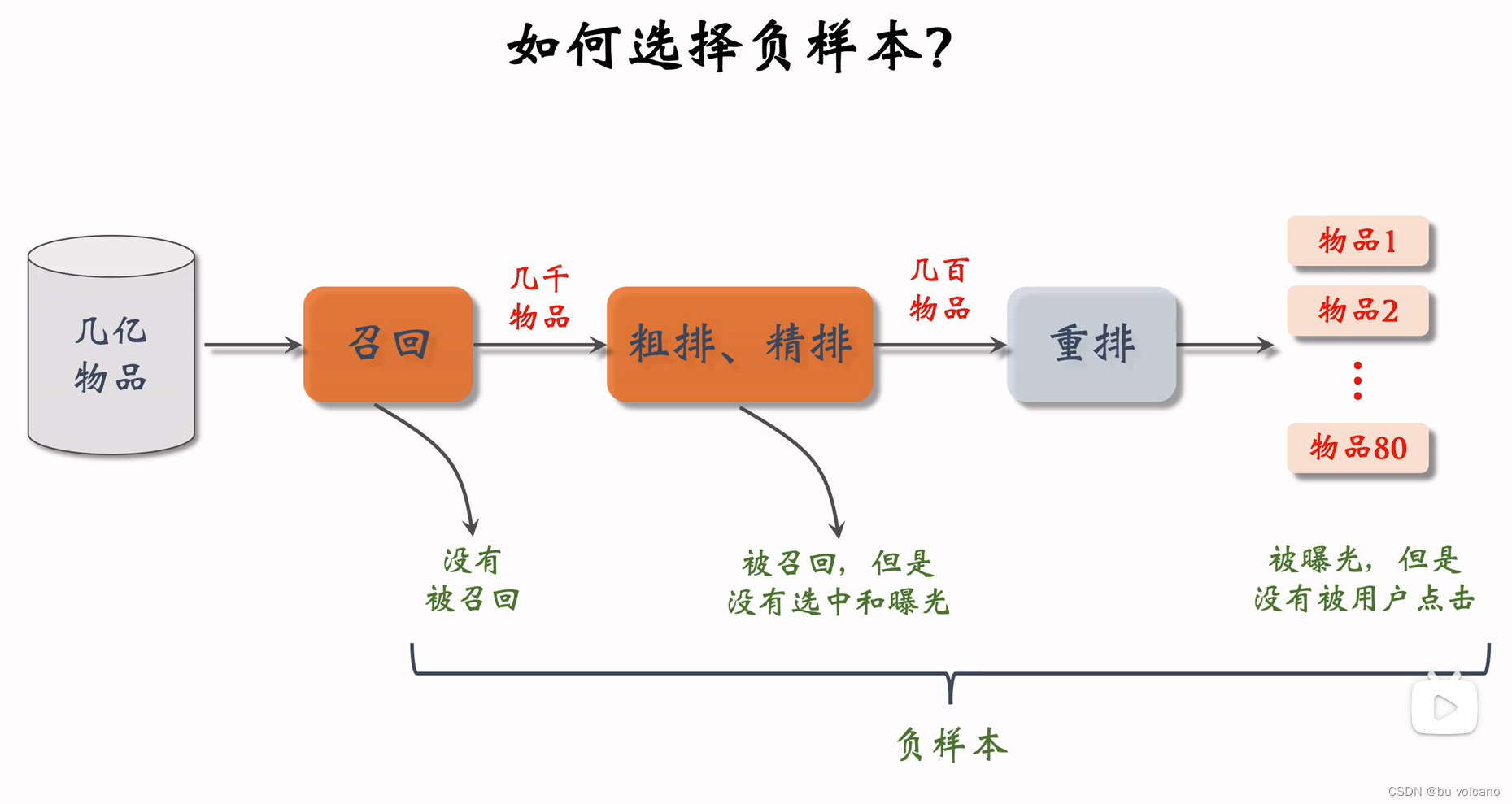
不能拿最后曝光用户没有点击的当做召回模型训练的负样本,因为这个推荐已经非常精确了
可以将这个当做排序的负样本,用来训练用户非常感兴趣样本和一般感兴趣样本的区别



双塔模型有缺点:
·推荐系统的头部效应严重∶
·少部分物品占据大部分点击。·大部分物品的点击次数不高。
·高点击物品的表征学得好﹐长尾物品的表征学得不好。
·自监督学习∶做data augmentation,更好地学习长尾物品的向量表征。
其余召回方式:
GeoHash:对经纬度的编码,地图上一个长方形区域,相当于同城召回
作者召回
有交互的作者
相似作者召回
缓存召回
二、排序
依据排序模型对点击率、点赞率、收藏率、转发率的预估分数,然后进行加权融合的总分数进行排序
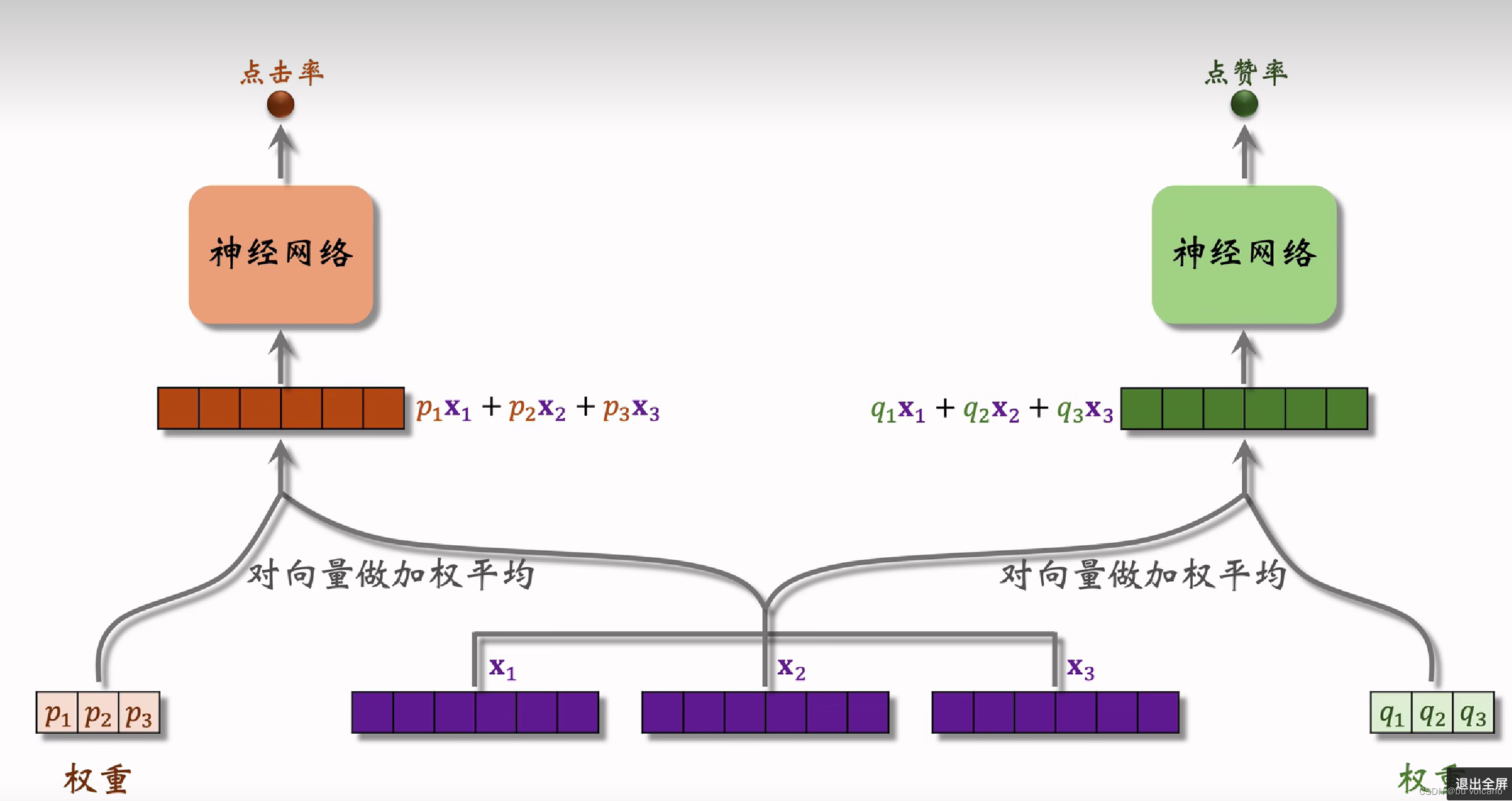
多目标模型
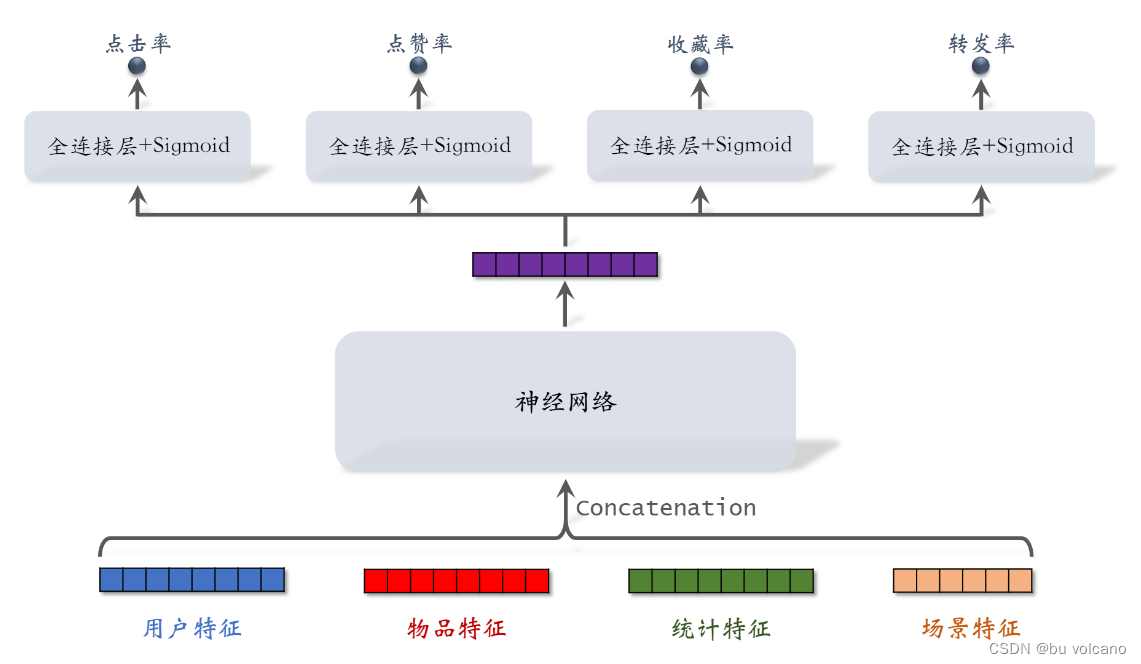
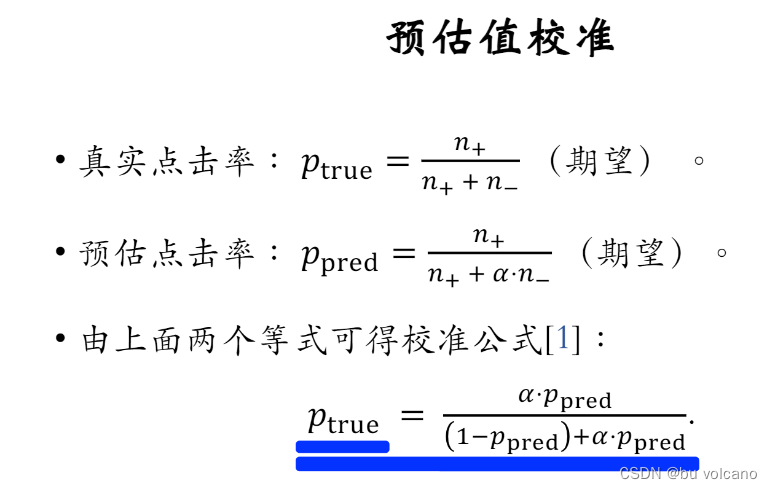
对负样本进行随机降采样,来消除样本的不平衡,但是因为负样本比真实时少了特别多,模型对点击率的预估会偏大,因此要对预测出来的值进行校准
MMOE
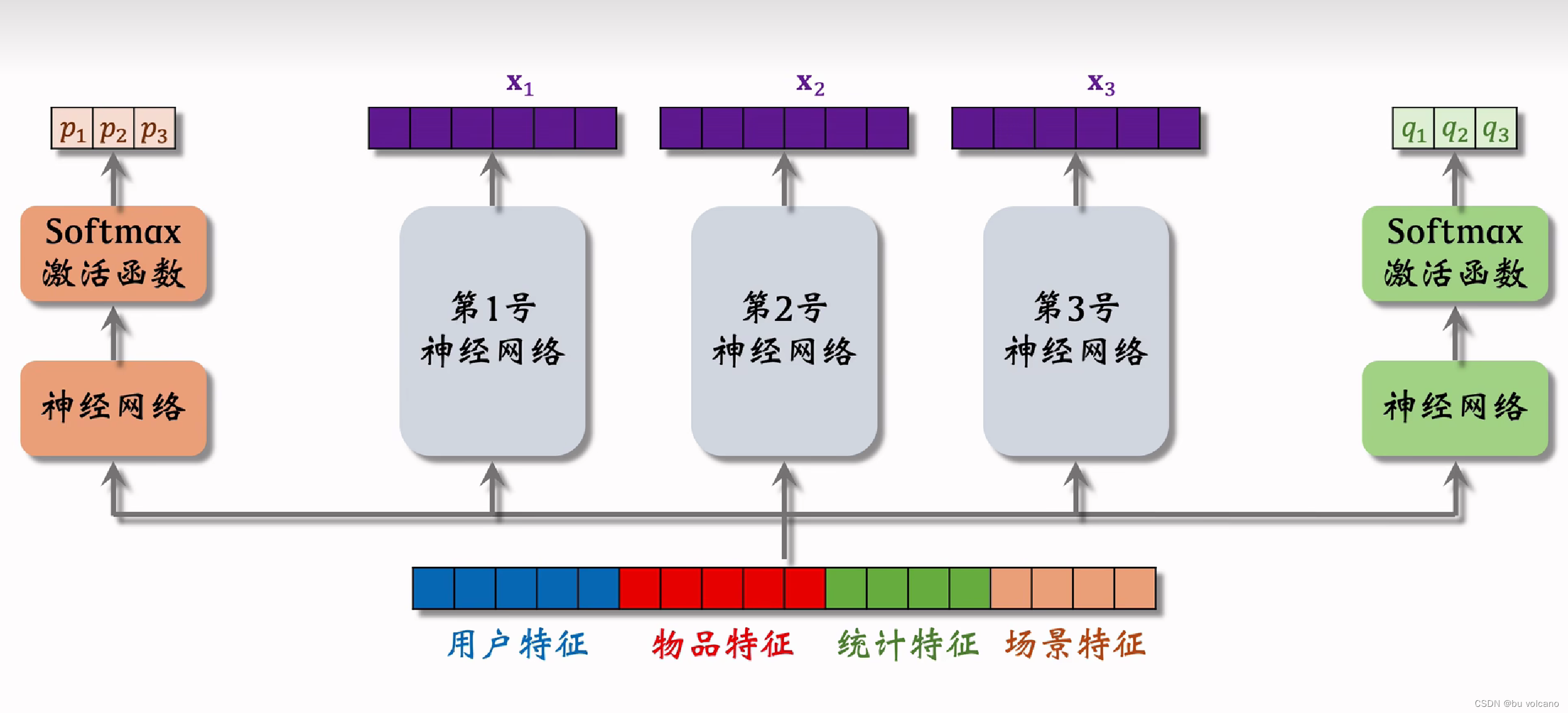
极化现象:当softmax中有值趋向于1时,其0所在权重的神经网络相当于死掉了,这违背了专家网络设计的初衷。



对完播率建模
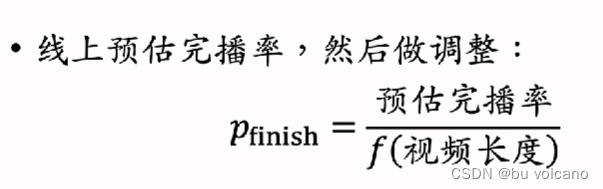







线上服务:
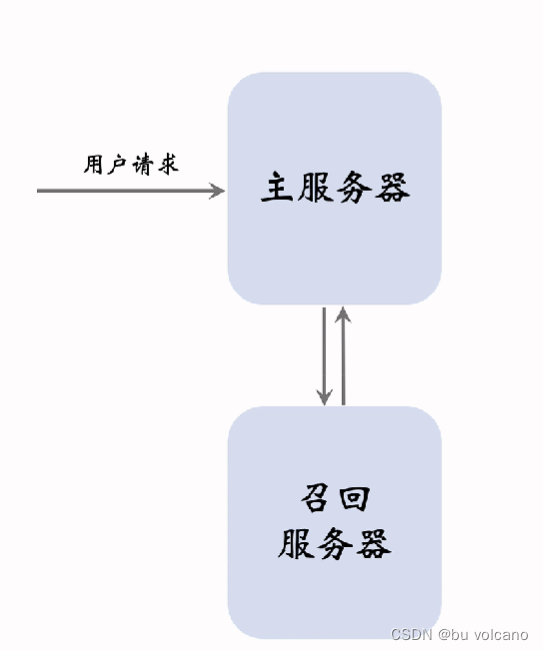
用户发送请求后,主服务器将请求发送到召回服务器,召回服务器返回多路召回归并后结果返回到主服务器;
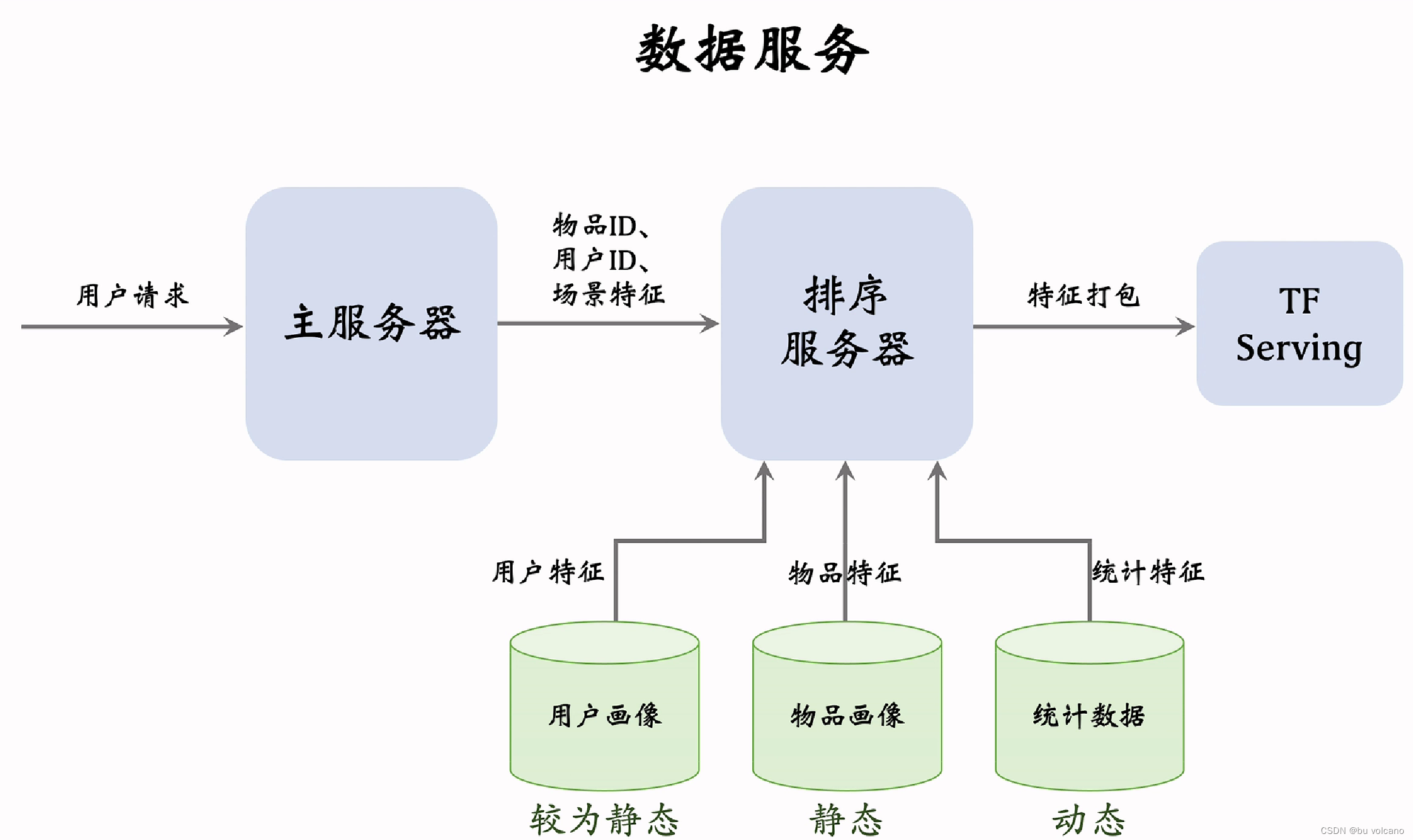
主服务器将一个用户ID和很多笔记ID发送到排序服务器,排序服务器从数据库中取出所需要特征(用户画像和用户统计数据库查询压力比较小,物品数据库要承受比较大的查询,所以内部向量不是很大的。所以会把用户和物品数据缓存在排序服务器,统计数据库数据需要比较实时的更新,因此不能缓存在排序服务器)。排序后将所有特征打包后发送给深度学习模型serving,深度学习将笔记打的分数后返回排序服务器,然后排序服务器根据分数规则进行排序后返回主服务器。
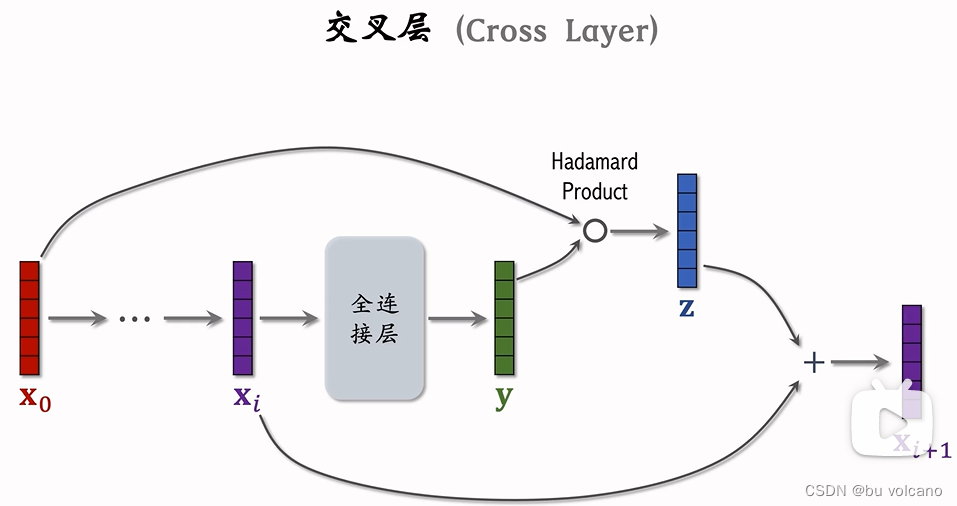
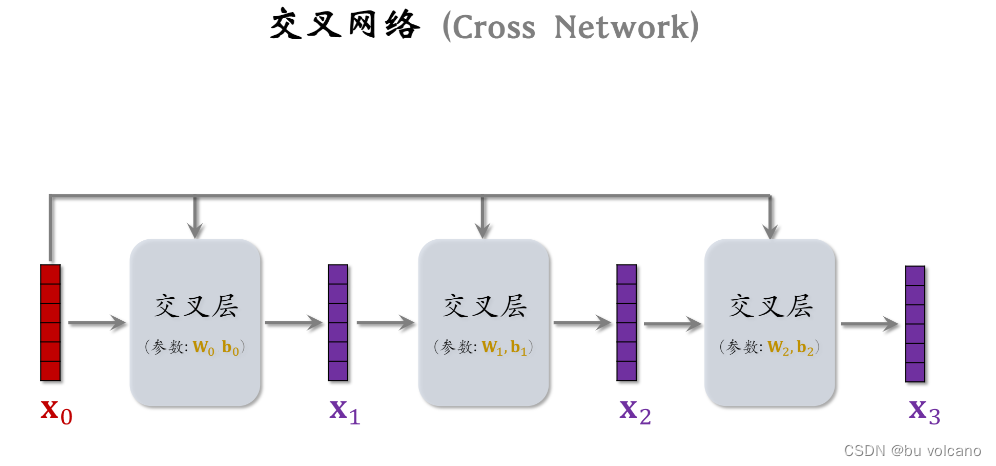
特征交叉:
使用单一特征并不好,比如预测房价,房屋面积特征和单价特征做相乘变为一个特征,模型就能得到很大的提升。

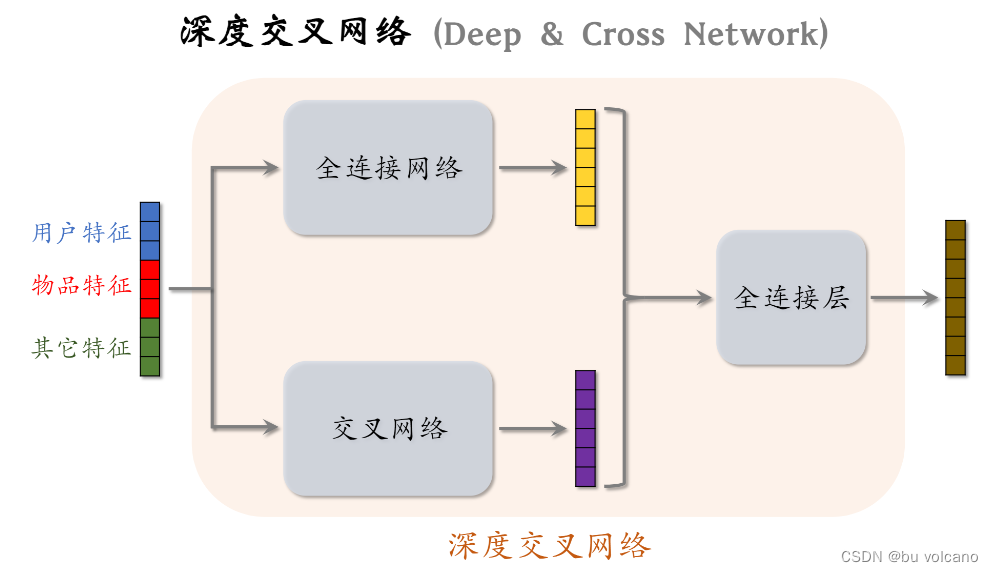
DCN:
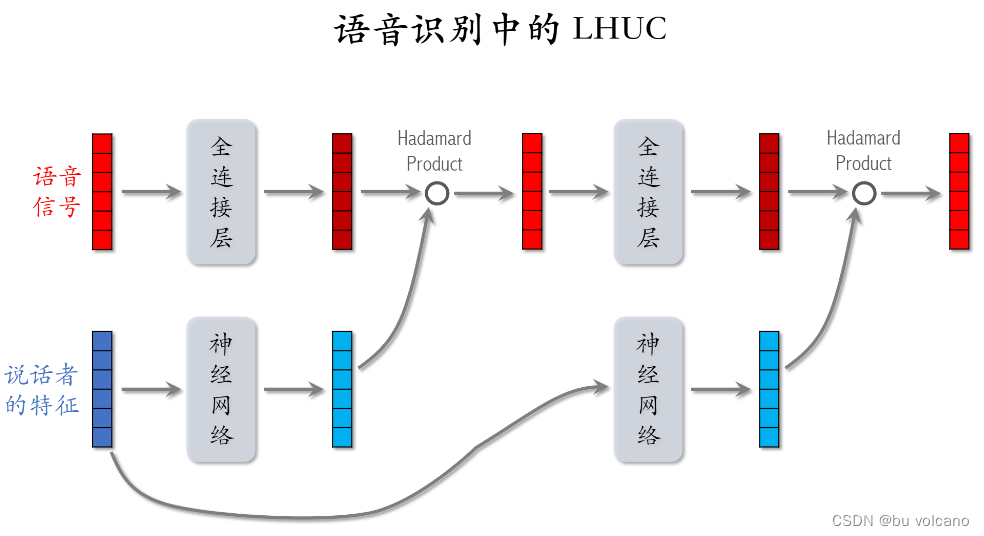
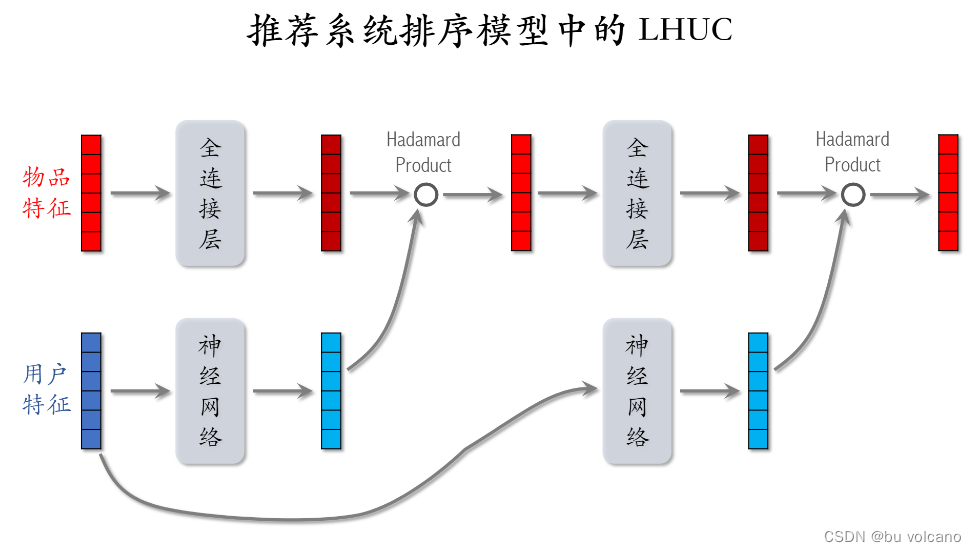
LHUC
对个人特征向量做了sigmiod*2,这样会将某些特征放大,某些特征缩小
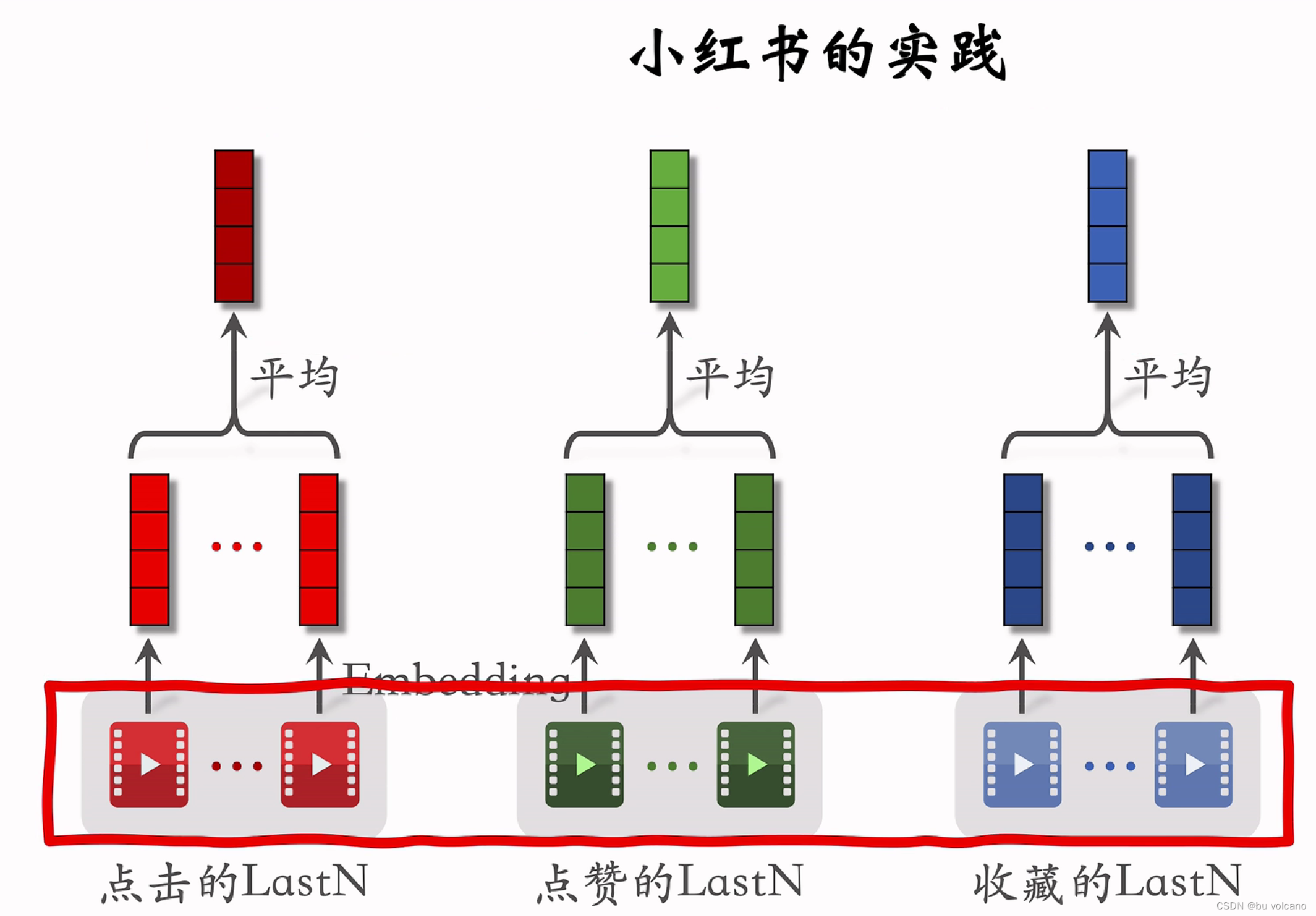
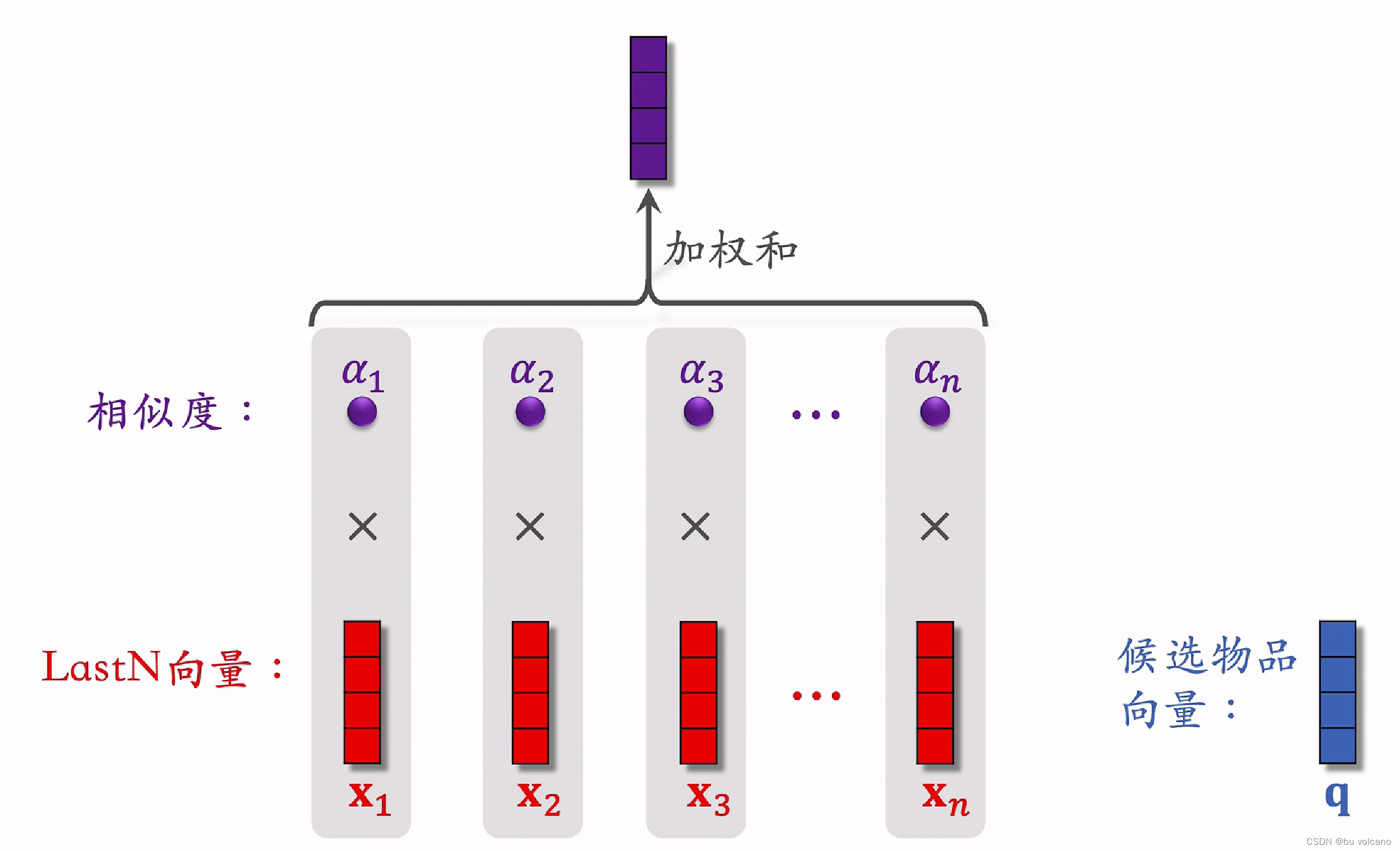
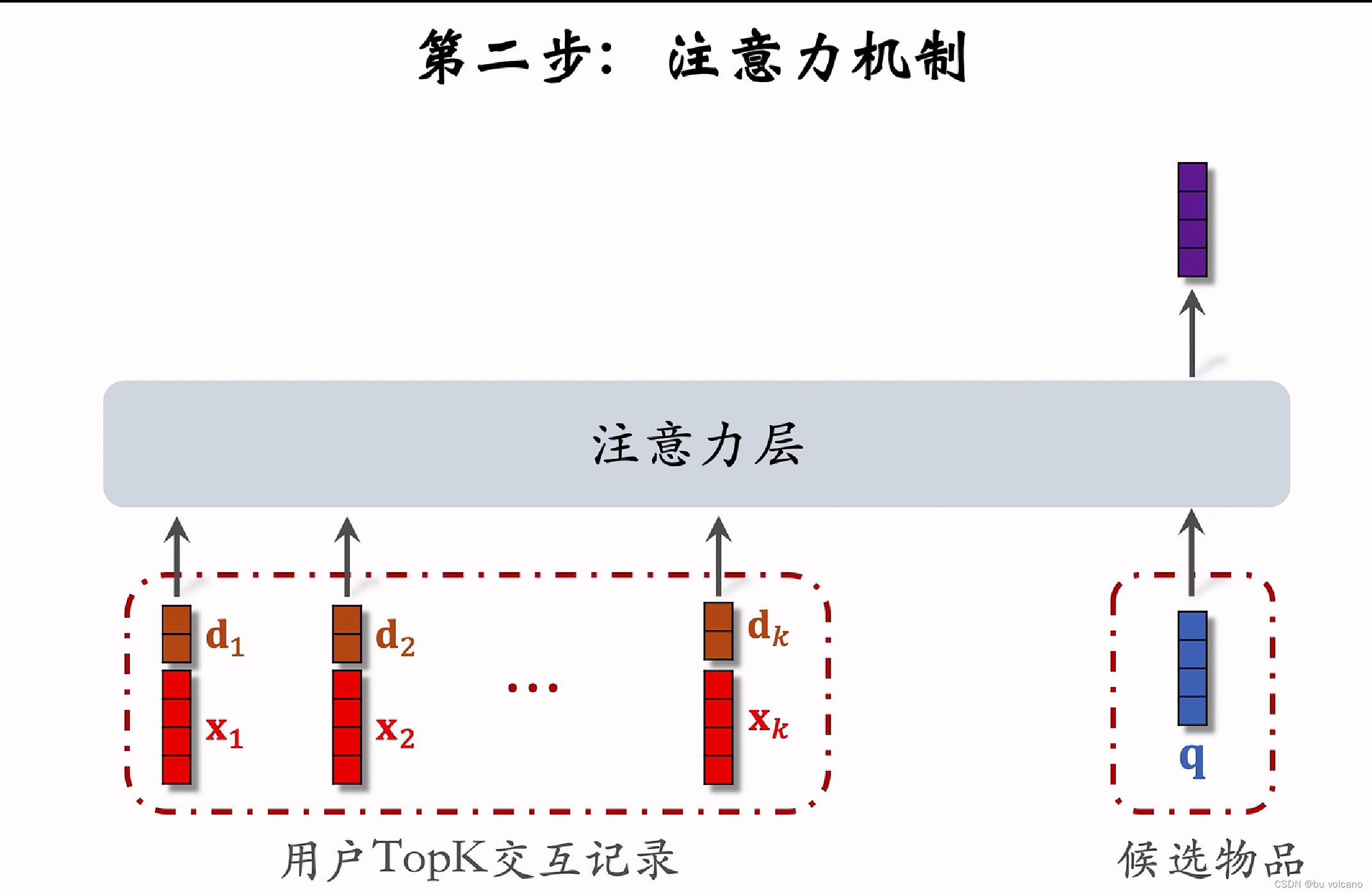
用户行为序列
DIN
是将简单的平均改为利用粗排后的候选物品来做相似度得到权重,对lastN做加权平均。本质上是注意力模型
base模型:
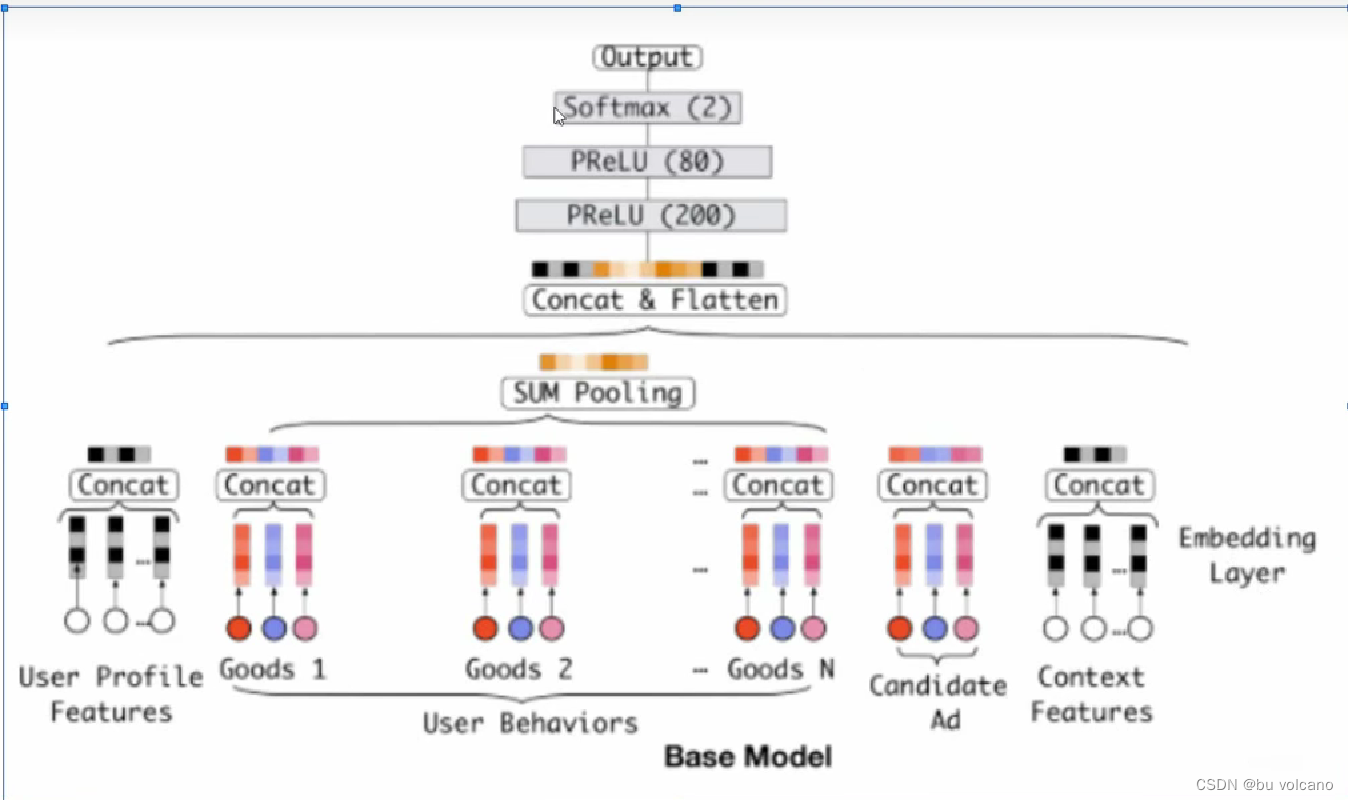
首先因为User Behaviors的交互行为数量不同,因此使用sum pooling进行求和压缩成为一个定长向量,后面flatten是固定的输入维度。
然后进入MLP学习特征之间的各种交互
缺点:
1、用户的历史行为特征和当前的候选广告特征在全都拼起来给神经网络之前,是一点交互的过程都没有。
2、拼起来之后给神经网络,虽然是有了交互了,但是既丢失了部分信息,也引入了一定的噪声
DIN模型:
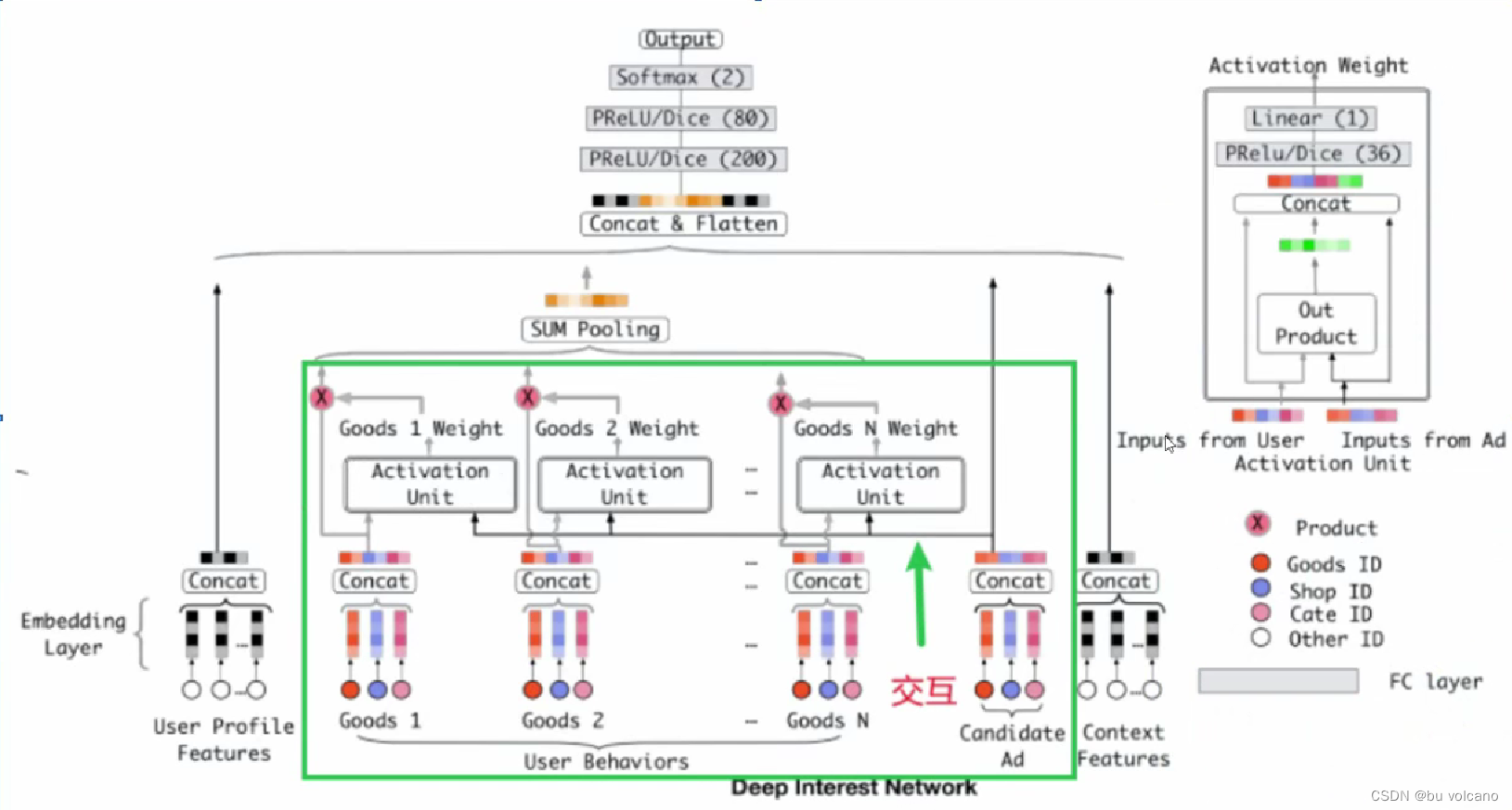
让每个历史交互与候选商品做交互计算出来一个activation weight,然后乘以自身原向量,再进入sum pooling。
DIN模型的缺点
注意力层的计算量 n (用户行为序列的长度)。·
只能记录最近几百个物品﹐否则计算量太大。
关注短期兴趣,遗忘长期兴趣,因此有了SIM。
采用了mini-batch aware regularization :①是因为为了防止过拟合使用L2正则化时会更新上亿参数的embedding字典。应对措施是通过自适应正则针对出现频率高的给较小的正则化强度(惩罚强度)。
②用户数据符合长尾定律,在数据集当中,出现次数很多的往往是一小部分特征,大多数特征(比较冷门、比较偏的)只出现了几次,容易加重过拟合。
为了解决ICS问题提出了DATA Adaptive Activation Function :Dice
改变激活函数来适应这一层的数据分布,求出数据的均值,然后让分割点移动到均值位置。
AUC和GAUC:
采用新的指标后比base模型性能提升多少。

SIM长序列模型
目的是在于改进DIN的最近几百个物品,但是计算量还不能大;因此对用户过往几千个物品在算候选物品相似度的时候,快速抛弃掉相似度低即无关的物品。也就是说把之前的lastN变成了Topk。在这个过程中我们可以将时间也考虑到,因为长期序列以前的时间信息也很重要,DIN都是最新的物品。


粗排后的后处理或者是精排后的重排:
- 物品相似性的度量。可以用物品标签或向量表征度量物品的相似性。最好的方法是基于图文内容的向量表征,比如 CLIP 方法。
- 提升多样性的方法。在推荐的链路上,在粗排和精排的后处理阶段,综合排序模型打分和多样性分数做选择。

MMR多样性算法Maxial Marginal Relevance
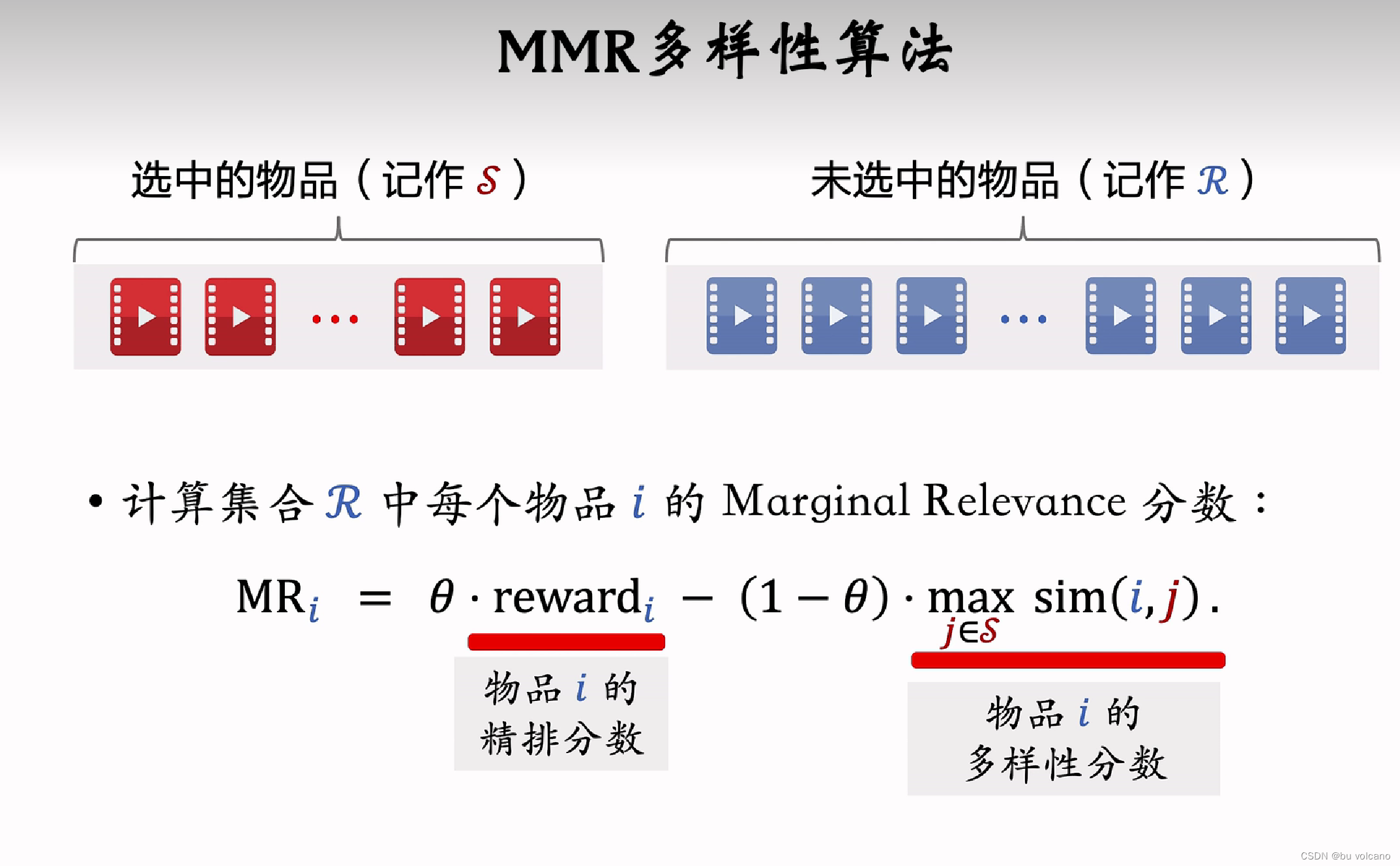

当S集合多样性已经很丰富时,再计算sim(i,j)时都会趋向1,因此MMR失效。采用滑动窗口能够改进这一缺点,即是从S集合中选出来最近的W个物品,考虑i和W中的多样性。因为用户在浏览时只要和最近的种类不同就可以了,100多条前看过的种类用户早已不记得。

DPP

物品冷启动
八、比赛实战-新闻推荐
1.分析理解过程
1.1题目理解
预测用户下一次点击的文章
预测五个,按顺序提交,第一个就预测对了得5分,依次递减。
1.2数据集理解
2.召回阶段
2.1基于物品的协同过滤
因为题目所给了,每个新闻有被那个用户点击的记录,所以可以直接计算新闻间的相似度。但是因为有大量的新闻未被
交互过,所以上面一种方式求出来了大量的0。
建立用户到物品的倒排表,使用用户浏览过的新闻(用户1访问过新闻1、新闻2,计算新闻1和2的相似度)进行计算相似度,这样就排除掉了没人看的新闻。这样做的缺点就是只要不是同时出现在一个用户中的新闻不会被计算相似度(仅考虑到了共现时的相似度),也就是说有可能两个新闻都被访问过,但是没有计算相似度。在计算相似度时可以使用log惩罚看文章比较多的人。
对上面共现的物品相似度进行改进,在实际应用中,应该考虑点击次序带来的影响。在计算同一序列中两个新闻的相似度时,不仅需要考虑共现次数,也需要考虑两个新闻之间的次序关系。同一点击序列中两个新闻位置越远,相关性应该减小。新闻对顺序和逆序的权重也不同,在点击序列A,B,C中,"BC"这样的正序权重应该大于"BA"这样的逆序权重。
2.2.热度召回:
不考虑用户的兴趣,只度量文章的热度,需要根据考虑文章本身是否热门
实际的数据指标有:点击率,收藏率,评论数等一些正反馈的动作,来直观的判断,选择最热门的一些文章作为召回结果。
就是,文章被点击的次数。当然也可以考虑在一个时间段内文章被点击的次数。
本赛题只给了用户点击的文章。
2.2类别召回
计算新闻相似度时,因为很多新闻没有被访问到,所以出现了很多0。因此采用循环访问每个人的新闻列表计算相似度。
根据共现(啤酒和尿不湿)的一个频次进行召回,用户点了A就推荐B。
地域召回
分析用户是爱好广泛类型还是专一类型
文章长度
文章发布时间,相当于文章的生存周期
3.排序
对召回得到的列表文章进行打分预测然后排序。
对召回得到的新闻列表进行拆分,将题目给的数据集最后一条点击记录与召回得到结果进行对比,如果相同则这一条训练数据的label就是1,否则就是0。也就是将问题转换成了0-1的二分类问题,得到的概率分数也就是预测的点击率。
此时会大量出现0的负样本,要尽量保证召回的结果中有正确的,也就是召回率要好一些。
模型可以使用CTR点击率预估模型
3.特征工程
对召回得到的候选文章通过特征工程再次筛选达到一个比较精确的推荐结果.
因为召回时使用的模型比较简单且用户特征较少,仅使用了新闻之间的相似度;所以得出的候选文章不够精确。
因此对得出结果加上题目所给其余特征构造一个有监督的学习(每一个候选结果的label可以通过train_clieck_log的已知最后一次结果来构建)。
上一步结束后训练集仅有召回的特征,因此我们采用以下思路构造特征
3.1物品特征:
文章生存周期、
文章字数
新闻创建时间
新闻被阅读数量
3.2用户特征:
用户新闻阅读数量
用户某种类新闻阅读数量
用户点击新闻的点击时间统计值
用户看过的文章的平均字数
用户看过的文章的最小字数
用户看过的文章的最大字数
最后两次点击的间隔,若不存在设为nan
最后两次点击的文章的投稿间隔,若不存在设为nan
最后一篇文章和平均字数的差值
最后一次点击时刻与文章投稿时刻的差值















 2113
2113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











