







 文章提出了HeroGRAPH,一个用于多目标跨领域推荐的异构图框架,旨在通过构建共享图和循环注意力机制来缓解数据稀疏性,提高各个领域的推荐性能。实验结果显示,HeroGRAPH在处理稀疏性问题上表现出色。
文章提出了HeroGRAPH,一个用于多目标跨领域推荐的异构图框架,旨在通过构建共享图和循环注意力机制来缓解数据稀疏性,提高各个领域的推荐性能。实验结果显示,HeroGRAPH在处理稀疏性问题上表现出色。
HeroGRAPH: A Heterogeneous Graph Framework for Multi-Target Cross-Domain Recommendation
HeroGRAPH:一种面向多目标跨领域推荐的异构图框架
ResSys 2020
摘要:
跨域推荐(Cross-Domain Recommendation**:CDR**)是推荐系统中的一项重要任务。通过将其他领域的信息迁移到目标领域,可以提高目标领域的性能,缓解稀疏性问题。以往的工作大多是单目标CDR (STCDR),最近一些研究人员提出研究双目标CDR (DTCDR)。然而,有几个限制。这些工作倾向于捕捉域之间的成对关系。如果将它们扩展到多目标CDR (MTCDR),则需要学习更多的关系。此外,已有的CDR工作倾向于利用额外的信息或重叠的用户来缓解数据稀疏问题。这就导致了大量的预操作,比如特性工程( feature-engineering)和寻找普通用户。在这项工作中,我们提出了一个MTCDR的异构图框架(HeroGRAPH),首先,通过收集来自多个领域的用户和物品,构建共享图;只需对图进行一次建模,即可获得每个领域的跨域信息,而无需进行任何关系建模。其次,通过聚合来自多个域的用户或物品的邻居来缓解稀疏性。然后,我们设计了一个循环注意力(recurrent attention)来为每个节点建模异构邻居。这种循环结构可以帮助迭代地改进选择重要邻居的过程。在真实数据集上的实验表明,HeroGRAPH能够有效地在领域间传递信息,缓解领域间的稀疏性问题。
异构图、多目标、跨领域
设计一个异构图存储跨领域节点(如何划分的、数据量庞大),然后通过一个循环注意力网络(咋循环的)建模。
1 介绍
协同过滤(CF)方法经常面临稀疏性问题,跨域推荐(Cross-Domain Recommendation, CDR)被证明是缓解稀疏性的有效方法。它可以将丰富的信息从一个域传递到另一个域,以提高性能。
已有的研究工作主要集中在STCDR和DTCDR,而对多目标CDR( multi-target CDR,MTCDR)的研究较少。MTCDR是DTCDR的泛化。
单目标CDR (single-target CDR, STCDR):它将信息从源域传递到目标域,通过丰富的边信息缓解稀疏性。
双目标CDR (dual-target CDR, DTCDR):来自源领域和目标领域的信息相互利用,以提高两个领域的性能。通常有两种方法进行双目标建模。第一种方法主要基于用户,因为他们可以清楚地从多个域恢复信息。第二种方法利用映射函数作为域之间的桥梁。
给定至少3个领域以及特征和反馈,MTCDR的目标是提高所有领域的性能。以往成功的DTCDR方法如果扩展到MTCDR,会存在一些问题。
1、DTCDR通常对域之间的成对关系进行建模;如果它们直接处理n个域 则至少有 C_n^2 个关系。
2、大多是通过用户传递信息。这是一种间接整合跨域信息的方式,因为多个域的用户行为仍然在每个域内处理。
也许我们可以收集所有的行为来设计一个共享结构,比如图谱。这种结构可以直接对域内和跨域行为进行建模,因为它可以从所有域获取用户或物品的反馈信息。
在这项工作中,本文提出了一个MTCDR的异构图框架(HeroGRAPH)。首先,我们从多个域收集用户和物品的ID信息,并构建共享图。节点包括用户和项目。如果用户购买了一件商品,那么图中就会有一条边。然后利用各域内信息进行域内建模,利用共享图处理跨域信息;此外,我们提出了一种对来自多个域的邻居进行聚合的循环注意力。最后,结合域内嵌入和跨域嵌入计算用户偏好并训练模型。主要贡献如下:
现在看上去就是把所有特征扔到图谱里面调用注意力网络大杂烩,继续往下看
本文贡献:
1、我们建议引入一个共享结构来对来自多个领域的信息进行建模,比如一个图。这种结构可以极大地简化交叉建模过程。
2、我们建议为用户和项目聚合来自所有域的邻居,以缓解稀疏性问题。此外,我们还引入了循环注意来迭代地细化聚合。
3、在真实数据集上的实验表明,HeroGRAPH优于最先进的方法,在处理稀疏性方面是有效的
2 相关工作
在本节中综述了相关工作,包括STCDR、DTCDR和图神经网络。
与单域推荐相比,STCDR能够充分利用源域信息来提升目标域的推荐性能。
与STCDR不同,DTCDR试图利用目标域的信息对源域进行加权
图神经网络的兴起使得本文可以通过聚合邻居来缓解稀疏性。
3 方法
示意图如图1所示。我们首先将问题形式化。然后,收集每个域的反馈,得到每个用户和物品的域内嵌入;然后,我们收集所有反馈来构建共享图并获得跨域嵌入。最后,计算用户偏好并应用贝叶斯个性化排序(BPR)对模型进行训练。
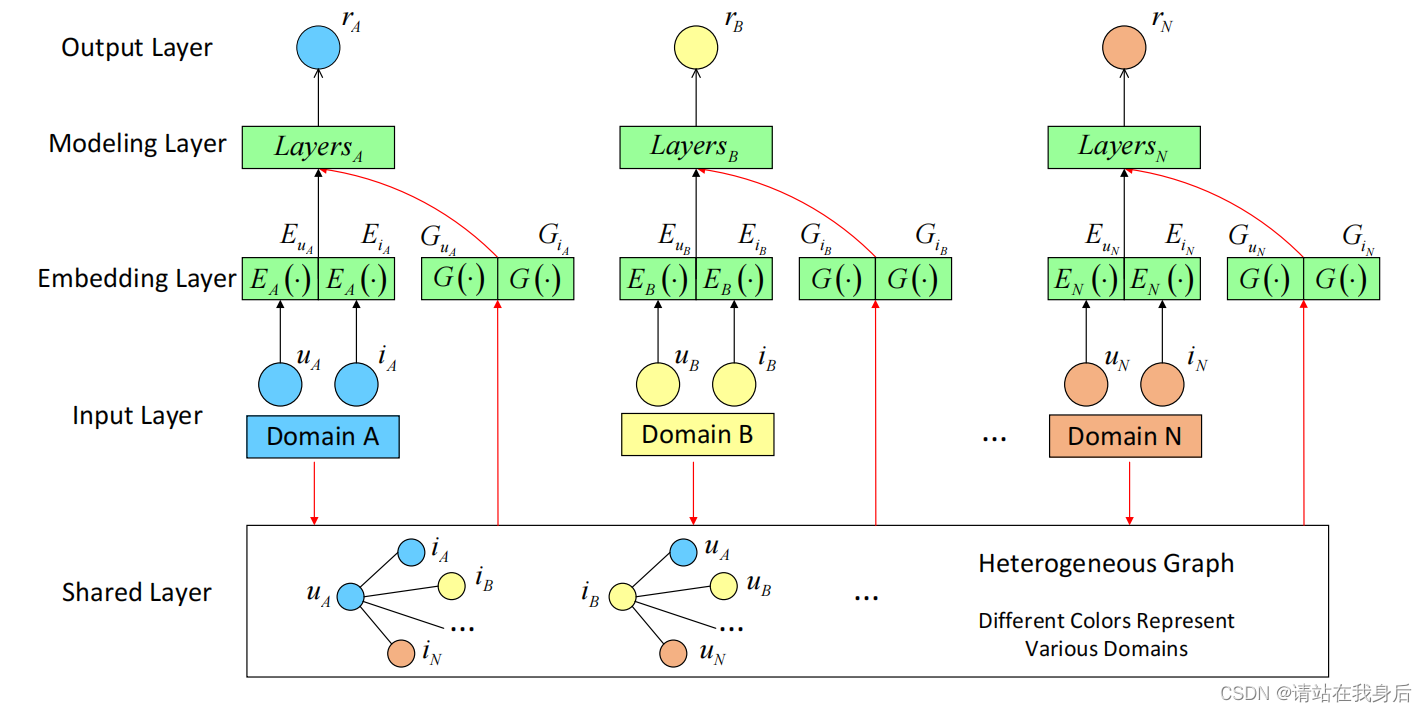
图1:HeroGRAPH模型示意图。不同层之间的黑色和红色箭头分别表示域内建模和跨域建模。该模型从多个领域收集信息,构建异构图来迁移知识并提升每个领域的性能。
3.1 符号说明
U A 、 I A 代表用户和项目的集合,下标 A 代表领域 A u A 、 i A 、( u A , i A )表示用户 I D ,项目 I D 以及一个正反馈对 无其他辅助信息 目标:提高所有领域的推荐性能 U_A、I_A 代表用户和项目的集合,下标A代表领域A\\ u_A、i_A、(u_A,i_A) 表示用户ID,项目ID以及一个正反馈对 \\无其他辅助信息\\目标:提高所有领域的推荐性能 UA、IA代表用户和项目的集合,下标A代表领域AuA、iA、(uA,iA)表示用户ID,项目ID以及一个正反馈对无其他辅助信息目标:提高所有领域的推荐性能
3.2 域内建模
由于拥有的唯一特征是ID,因此可以轻松地为每个ID分配一个向量作为初始嵌入
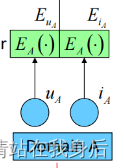
u A 和 i A 的嵌入分别为 E u A 和 E i A u_A 和i_A的嵌入分别为 E_{uA} 和E_{iA} uA和iA的嵌入分别为EuA和EiA
3.3 共享图谱和跨域建模
使用所有领域的反馈构建异构图:
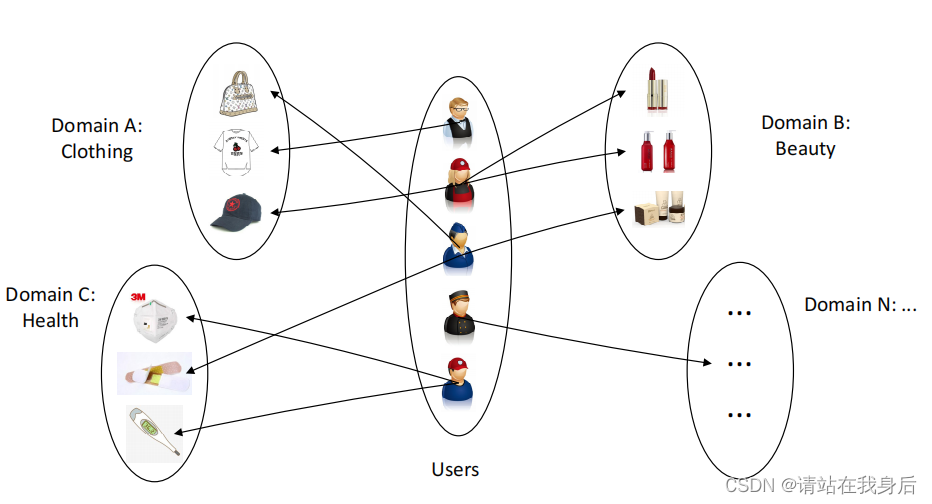
图2:异构图的说明。用户可能在不同的领域有反馈,我们将所有用户和项目作为共享结构收集到一个图中。这个图是域之间的桥梁。请注意,这些域名仅限于一个平台,如Facebook或亚马逊。
跨域建模可以认为是图建模
u
A
和
i
A
的嵌入分别为
G
u
A
和
G
i
A
u_A 和i_A的嵌入分别为 G_{uA} 和G_{iA}
uA和iA的嵌入分别为GuA和GiA
假设我们在域 A 中有一个用户,其 I D 为 u A , 其邻居为 N ( u A ) = { i A , i B , … , i N } 假设我们在域A中有一个用户,其ID为u_A,其邻居为N(u_A)=\{i_A,i_B,…,i_N\} 假设我们在域A中有一个用户,其ID为uA,其邻居为N(uA)={iA,iB,…,iN}
它们的中间图嵌入可以表示为
q
=
h
u
A
K
=
{
h
j
∣
j
∈
(
u
A
)
}
=
{
h
i
A
,
h
i
B
,
…
,
h
i
N
}
V
=
{
p
h
j
+
p
∣
h
j
∈
K
}
q = h_{u_A}\\ K=\{h_j | j \in (u_A)\} = \{h_{i_A},h_{i_B},…,h_{i_N}\}\\ V= \{ph_j+p|h_j \in K\}
q=huAK={hj∣j∈(uA)}={hiA,hiB,…,hiN}V={phj+p∣hj∈K}
其中,q、K、V分别为全连接网络得到的用户向量、邻居向量和嵌入邻居表示。然后,利用这些向量计算跨域嵌入
o
V
=
m
a
x
(
V
)
G
u
A
=
R
e
L
U
(
W
⋅
C
O
N
C
A
T
(
q
,
o
V
)
+
w
)
o
V
是聚合的近邻表示
,
而最终的图嵌入
G
u
A
是
q
和
o
V
的非线性组合
o_V =max(V)\\ G_{u_A}=ReLU(W\cdot CONCAT(q,o_V)+w)\\ o_V 是聚合的近邻表示,而最终的图嵌入G_{u_A}是q和o_V的非线性组合
oV=max(V)GuA=ReLU(W⋅CONCAT(q,oV)+w)oV是聚合的近邻表示,而最终的图嵌入GuA是q和oV的非线性组合
在建模过程中不再需要寻找重叠用户,但图建模仍然依赖于重叠用户来合并跨域信息
3.4 邻域聚合的循环注意力
通过自动检测每个邻居的重要性来循环关注每个节点的聚合邻居。
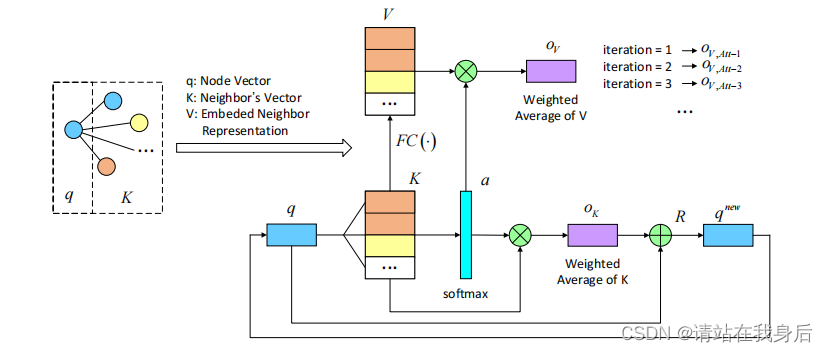
图3:循环注意力。注意力充当节点邻居的聚合器。注意力可以总结多个因素,开发了一个循环版本,以逐步完善这个过程。循环操作在节点向量q和邻居向量k中进行。在每次迭代中,我们通过注意力权重a和嵌入的邻居表示V计算邻居聚合的输出。
通过Bahdanau attention【1】计算q和K之间的注意力权重a,我们可以通过得到一种新的oV形式
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In ICLR.
o V = V ⋅ a o_V=V \cdot a oV=V⋅a
由于邻居来自多个域,我们期望逐步完善获取注意力权重a的过程。为此,我们对K进行聚合,对q进行更新
o
K
=
k
⋅
a
q
n
e
w
=
R
⋅
(
q
+
o
K
)
其中
R
是一个线性映射,
q
+
o
K
是一个捷径连接。
接下来,
q
n
e
w
作为
n
e
w
q
重新计算
a
o_K = k \cdot a\\ q^{new} = R \cdot (q +o_K)\\ 其中R是一个线性映射,q +o_K是一个捷径连接。\\ 接下来,q^{new}作为new\ q重新计算a
oK=k⋅aqnew=R⋅(q+oK)其中R是一个线性映射,q+oK是一个捷径连接。接下来,qnew作为new q重新计算a
此外,我们为q和K添加一个dropout层,以避免在首次获得它们时过度拟合。
3.5 训练框架
在这一小节中,我们获取用户偏好并训练模型。给出了基于域A的方程。
基于矩阵分解计算用户正向偏好:
x
^
u
i
A
t
=
E
u
A
t
⋅
E
i
A
t
+
G
u
A
t
⋅
G
i
A
t
\hat x^t_{ui_A} = E^t_{u_A} \cdot E^t_{i_A}+G^t_{u_A}\cdot G^t_{i_A}
x^uiAt=EuAt⋅EiAt+GuAt⋅GiAt
上标t表示具有特定时间戳的样本(uA,iA)
然后采用BPR (pairwise Bayesian Personalized Ranking)算法对模型进行训练
l
u
i
j
A
t
=
−
l
n
σ
(
x
^
u
i
A
t
−
(
x
^
u
j
A
t
)
其中
x
^
u
j
A
t
是基于负反馈对(
u
A
,
j
A
)的负偏好。
l^t _{uij_A} = -ln \sigma(\hat x^t_{ui_A}-(\hat x^t_{uj_A})\\ 其中\hat x^t_{uj_A}是基于负反馈对(u_A,j_A)的负偏好。
luijAt=−lnσ(x^uiAt−(x^ujAt)其中x^ujAt是基于负反馈对(uA,jA)的负偏好。
最后,A域的损失函数为
Θ
A
∗
=
a
r
g
m
i
n
Θ
∑
u
∑
t
=
1
t
=
∣
u
∣
l
u
i
j
A
t
+
λ
Θ
2
∣
∣
Θ
∣
∣
2
\Theta ^*_A = argmin_\Theta \sum_u \sum_{t=1}^{t=|u|} l^t_{uij_A}+\frac {\lambda_\Theta}{2}||\Theta||^2
ΘA∗=argminΘu∑t=1∑t=∣u∣luijAt+2λΘ∣∣Θ∣∣2
其中|u|表示用户u的所有样本数
全部损失为:
Θ
∗
=
Θ
A
∗
+
Θ
B
∗
+
Θ
C
∗
+
…
…
\Theta ^*=\Theta ^*_A+\Theta ^*_B+\Theta ^*_C+……
Θ∗=ΘA∗+ΘB∗+ΘC∗+……
Adam用默认值更新参数。
4 实验
数据集。
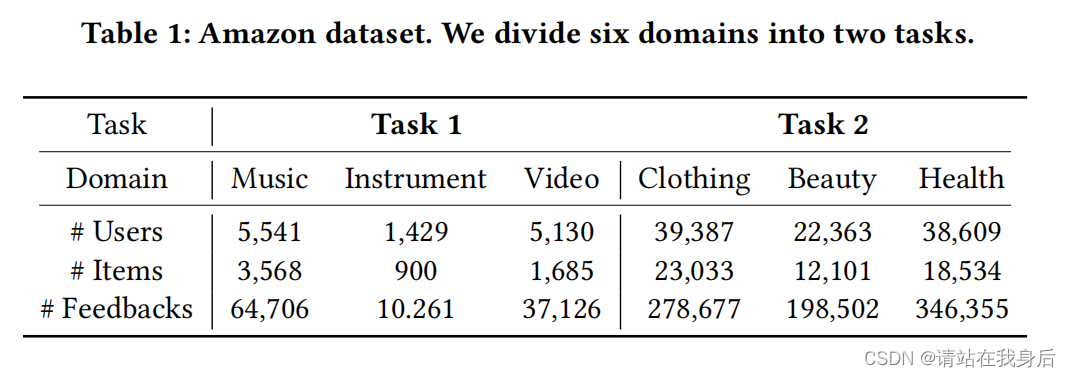
实验在Amazon 5核数据集[10]上进行。我们选择了6个领域,并将它们分为两个任务。每个任务有三个域。表1列出了每个域的统计信息。请注意,反馈的数量等于网站上列出的评论的数量
评估协议。
所有数据集按时间分为训练集、验证集和测试集。其中,验证集的时间范围为1-Mar。-2014年和2014年4月30日。三组反馈量之比约为8:1:1。通过AUC在测试集上对性能进行评估。
Baselines
(1) BPR (2) DDTCDR(3) GraphSAGE-poo
参数设定
利用Tensorflow 2.2实现了该方法,并根据验证集选择超参数。每个ID的嵌入大小为8。正则化参数为0.01。在图建模方面,采用GraphSAGE中采用的均匀采样方法进行邻居选择,一阶邻居和二阶邻居的样本大小分别为10和5。对应的,第一层聚合和第二层聚合的输出嵌入大小分别为64和16。这些参数用于我们工作中的所有任务。
超参数优化
选择最佳的Dropout为0.2。
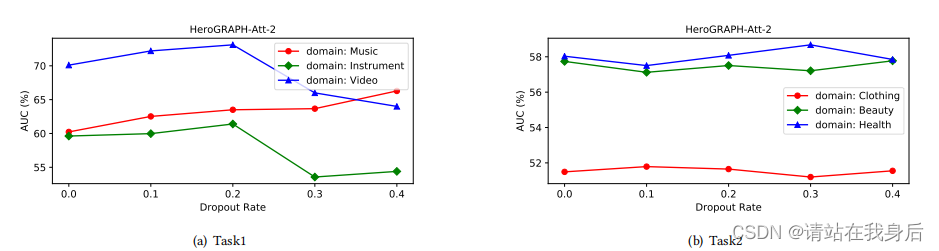
4.3 性能比较
HeroGRAPH获得了最好的性能。它在任务1上取得了显著的提高,而在任务2上的性能并不大。
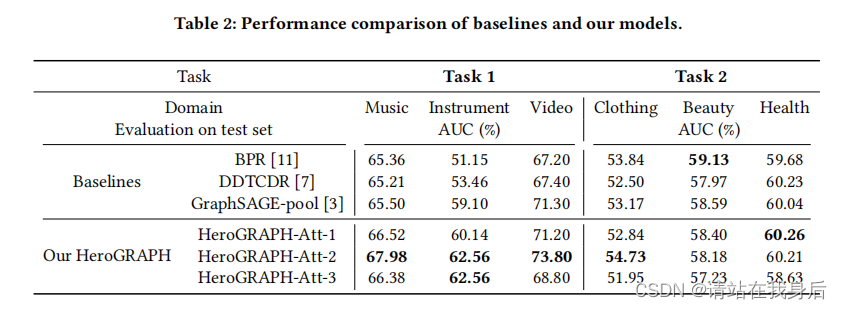
任务2的三个域拥有比任务1更多的数据。数据量越大,就越容易学会一个好的表达式。在这种情况下,单域方法可以取得很好的效果,并且不受其他域数据的影响。因此,在这些领域将很难改进。其次,我们将多个域作为一个整体,并使用全局最优超参数。这将导致我们的模型无法在每个域上实现最佳性能。在这种不利的情况下,我们的模型仍然取得了很好的效果
4.4 稀疏性问题分析
从整个测试集中选择一个稀疏集。我们计算测试集中每个项目的出现次数,反馈不超过5个的项目构成稀疏集。我们计算稀疏集和测试集反馈的总数,并将它们分割得到一个比例。比例越高,稀疏性问题越严重。
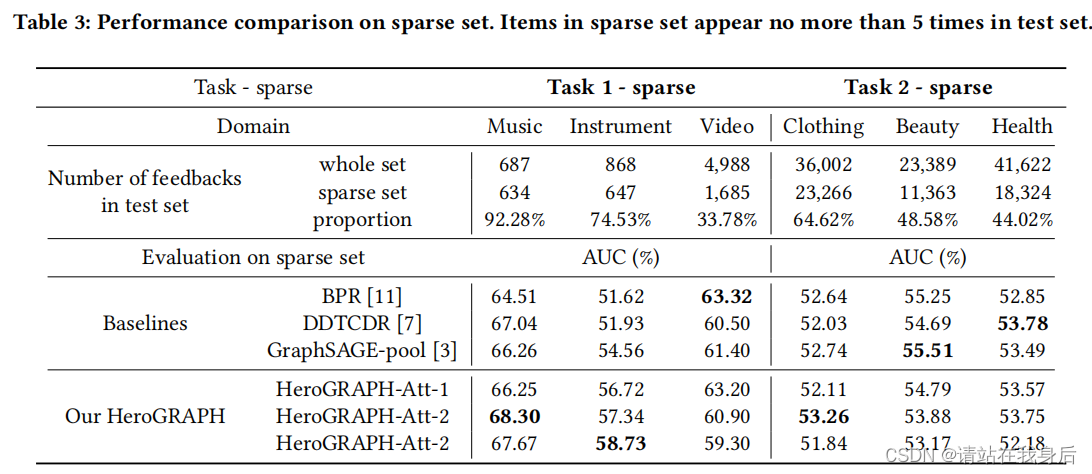
在任务1和任务2上,如果该领域具有较高比例的稀疏项,该模型可以取得很大的改进。如果稀疏项较少,例如在视频、美容和健康领域,由于超参数是全局最优的,所以我们的英雄图不够好。这意味着,通过对用户和物品的邻居进行建模,我们的模型可以帮助缓解稀疏性问题。
4.5 循环注意力
对重复注意的分析基于表2和表3,因为我们的变体在每个表的最后三行中列出。一般来说,Att-2优于Att-1和Att-3,也优于GraphSAGE。这意味着注意力可能更有用,重复注意力可以减少数据的方差。另一方面,Att-2在任务2上的表现与Att-1相当。Att-3的值几乎都小于Att-2。我们可以得出结论,如果我们有太多的迭代,我们的模型可能会过拟合。因此,我们不会进行更多的迭代。
5 结论
对重复注意的分析基于表2和表3,因为我们的变体在每个表的最后三行中列出。一般来说,Att-2优于Att-1和Att-3,也优于GraphSAGE。这意味着注意力可能更有用,重复注意力可以减少数据的方差。另一方面,Att-2在任务2上的表现与Att-1相当。Att-3的值几乎都小于Att-2。我们可以得出结论,如果我们有太多的迭代,我们的模型可能会过拟合。因此,我们不会进行更多的迭代。
5 结论
提出了一种面向多目标跨领域推荐的异构图框架(HeroGRAPH)。这是一项具有挑战性但有希望的任务。首先,我们建议使用共享结构来建模来自所有领域的信息,如图。然后提出一种循环注意力机制来逐步细化邻居聚集过程,以缓解稀疏性问题。实验证明了该模型的有效性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











