










目录
requests模块的编码流程:
-指定url
-发起请求
-获取响应数据
-持久化存储
环境安装:
pip install requests
实战编码:
-需求:爬取搜狗首页的页面数据
# 爬取搜狗首页的页面数据
import requests
if __name__ == "__main__":
# step1:指定url
url = "https://www.sogou.com/"
# step2:发起请求,get方法会返回一个响应对象
response = requests.get(url=url)
# step3:获取响应数据,用.text返回字符串形式的响应数据
page_text = response.text
print(page_text)
# step4:持久化储存
with open('./sogou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
print('爬取结束!!!')
-需求:简易的网页收集器
UA介绍:User_Agent(请求载体的身份标识)
UA检测:服务端对接收请求的来源的一个判断,判断来源是来自浏览器还是来自爬虫
UA伪装:将爬虫发送的请求伪装成浏览器发送的请求
import requests
if __name__=="__main__":
# UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.55"
}
# step1:获取指定url
url="https://www.sogou.com/web?"
keyword=input('请输入关键词:')
# 实现可变动的查询
param={
'query':keyword
}
fileName=keyword+'.html'
# step2:发起请求
response=requests.get(url=url,params=param,headers=headers)
# step3:响应数据
page_text=response.text
# step4:持续化储存
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'保存成功!!!')
User_Agent查看方法:
点击鼠标右键,选择检查,看到网络,之后选择全部,再输入搜索词,再抓包,再关注到User_Agent
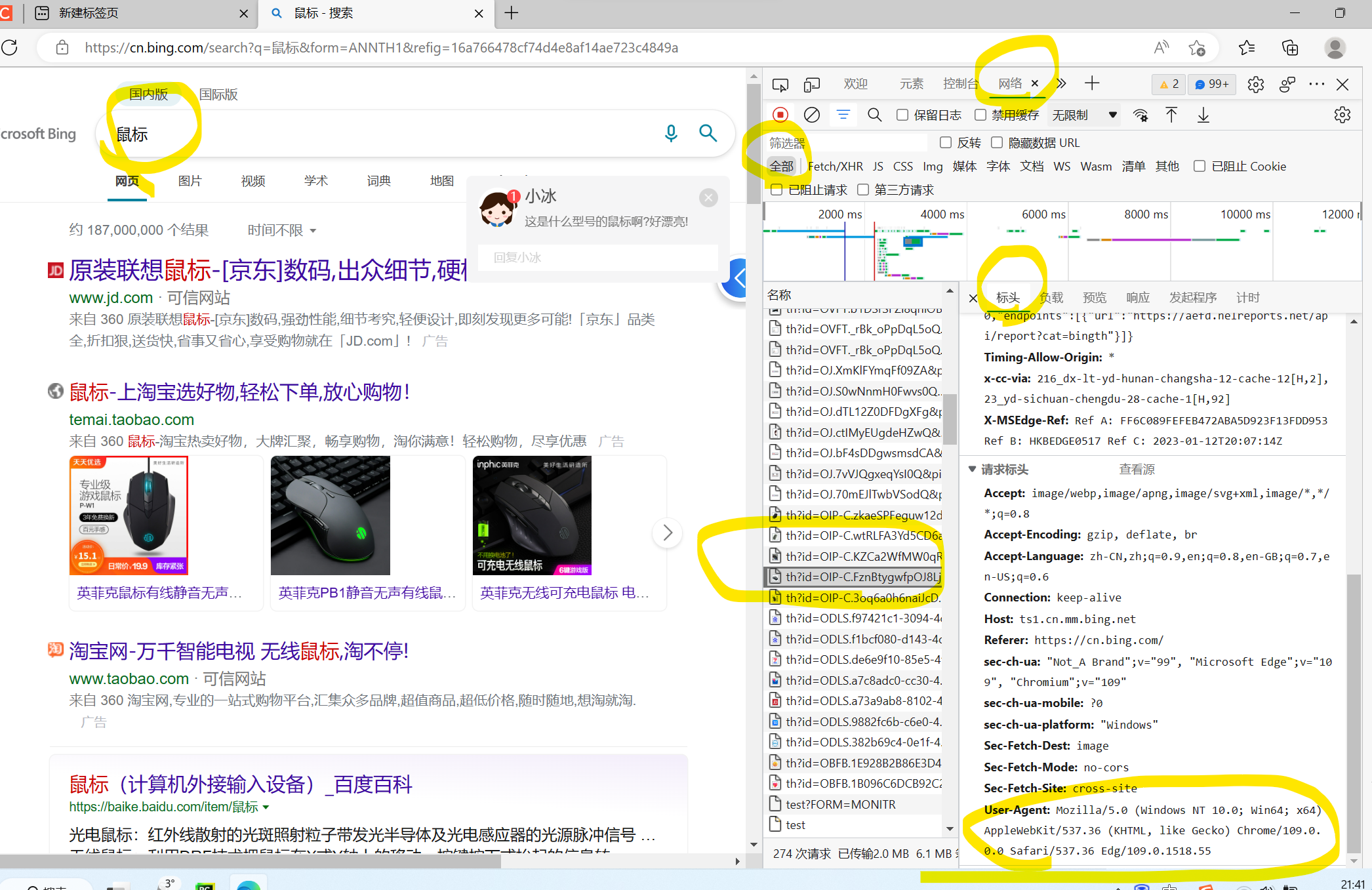
-需求:破解百度翻译
import requests
import json
if __name__=="__main__":
# step1:指定url
post_url='https://fanyi.baidu.com/sug'
# step2:进行UA伪装
header={
'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.55'
}
# step3:post请求参数处理
keyword=input('请输入要查询的单词:')
data={
'kw':keyword
}
# step4:发送请求
response=requests.post(url=post_url,data=data,headers=header)
# step5:获取响应数据,返回类型是json形式所以使用.json()方法
dic_obj=response.json()
# step6:持续化存储
fpName=keyword+'.json'
fp=open(fpName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print(fpName,'保存成功')主要看标头,负载和预览,从标头中可以通过content-type判断是json还是text等,然后还要看请求方法,预览可以看到对应的信息,负载也可以看到输入的东西
















 2451
2451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











