







数据类型
- 离散型数据:固定取值,值的数量是有限的
随机变量 X X X的分布律为: P ( X = x i ) = p i , i = 1 , 2 , ⋯ P(X=x_{i})=p_{i},i=1,2,\cdots P(X=xi)=pi,i=1,2,⋯,期望和方差如下
E ( x ) = ∑ i x i p i , D ( x ) = ∑ i ( x i − E ( x ) ) 2 p i E(x)=\sum_{i}x_{i}p_{i},D(x)=\sum_{i}(x_{i}-E(x))^{2}p_{i} E(x)=i∑xipi,D(x)=i∑(xi−E(x))2pi - 连续性数据:在给定范围内有无数取值
E ( x ) = ∫ a b x f ( x ) d x , D ( x ) = ∫ a b ( x − E ( x ) ) 2 f ( x ) d x E(x)=\int_{a}^{b} xf(x)dx,D(x)=\int_{a}^{b}(x-E(x))^{2}f(x)dx E(x)=∫abxf(x)dx,D(x)=∫ab(x−E(x))2f(x)dx
其中, f ( x ) f(x) f(x)表示随机变量的概率密度函数
期望和方差的关系:( E ( x ) E(x) E(x)为常数,则 E [ E ( x ) ] = E ( x ) E[E(x)]=E(x) E[E(x)]=E(x))
D ( x ) = E ( [ x − E ( x ) ] 2 ) = E ( x 2 − 2 x E ( x ) + E ( x ) 2 ) = E ( x 2 ) − 2 [ E ( x ) ] 2 + [ E ( x ) ] 2 = E ( x 2 ) − [ E ( x ) ] 2 D(x)=E([x-E(x)]^{2})=E\big(x^{2}-2xE(x)+E(x)^{2}\big)=E(x^{2})-2[E(x)]^{2}+[E(x)]^{2}=E(x^{2})-[E(x)]^{2} D(x)=E([x−E(x)]2)=E(x2−2xE(x)+E(x)2)=E(x2)−2[E(x)]2+[E(x)]2=E(x2)−[E(x)]2
期望和方差性质
期望:
来量化一个随机变量可能的平均水平。在实际应用中,期望常常被用来预测未来可能发生的平均情况
- 设 C C C是常数,则有 E ( C ) = C E(C)=C E(C)=C
- 设 X X X是一个随机变量, C C C是常数,则有 E ( C X ) = C E ( X ) E(CX)=CE(X) E(CX)=CE(X)
- 设 X , Y X,Y X,Y 是两个随机变量,则有 E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y)
- 设 X , Y X,Y X,Y 是相互独立的随机变量,则有 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
方差:
用来衡量随机变量或一组数据离散程度的度量。在实际应用中,方差常常被用来描述数据的波动性
- 设 C C C是常数,则 D ( C ) = 0 D(C)=0 D(C)=0
- 设 X X X是随机变量, C C C是常数,则有 D ( C X ) = C 2 D ( X ) , D ( X + C ) = D ( X ) D(CX)=C^{2}D(X),D(X+C)=D(X) D(CX)=C2D(X),D(X+C)=D(X)
- 设 X , Y X,Y X,Y是两个随机变量,则有 D ( X + Y ) = E ( [ ( X + Y ) − E ( X + Y ) ] 2 ) = D ( X ) + D ( Y ) + 2 E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] D(X+Y)=E([(X+Y)-E(X+Y)]^{2})=D(X)+D(Y)+2E[(X-E(X))(Y-E(Y))] D(X+Y)=E([(X+Y)−E(X+Y)]2)=D(X)+D(Y)+2E[(X−E(X))(Y−E(Y))],特别,若 X , Y X,Y X,Y相互独立,则有 D ( X + Y ) = D ( X ) + D ( Y ) D(X+Y)=D(X)+D(Y) D(X+Y)=D(X)+D(Y)
- D ( X ) D(X) D(X)的充要条件是 X X X以概率 1 取常数 E ( X ) E(X) E(X),即 P { X = E ( X ) } = 1 P\{X=E(X)\}=1 P{X=E(X)}=1
数据分布类型
正态分布
正态分布,也称为高斯分布,是一种在数学、物理及工程等领域都非常重要的概率分布。在统计学中,正态分布的数据形态呈现为钟型,两头低,中间高,左右对称。
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
u
)
2
2
σ
2
,
−
∞
<
x
<
∞
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-u)^{2}}{2\sigma^{2}}},-\infty < x < \infty
f(x)=2πσ1e−2σ2(x−u)2,−∞<x<∞
E
(
X
)
=
μ
,
D
(
x
)
=
σ
2
,
X
∼
N
(
μ
,
σ
)
E(X)=\mu,D(x)=\sigma^{2},X\sim N(\mu,\sigma)
E(X)=μ,D(x)=σ2,X∼N(μ,σ)
标准正态分布的均值为 0 0 0,方差为 1 1 1,密度为 f ( x ) = 1 2 π e − x 2 2 f(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^{2}}{2}} f(x)=2π1e−2x2
处理方法:正态分布是许多统计模型的基础,如果数据不符合正态分布,可以通过对数变换、平方根变换等方法尝试将其转化为正态分布。
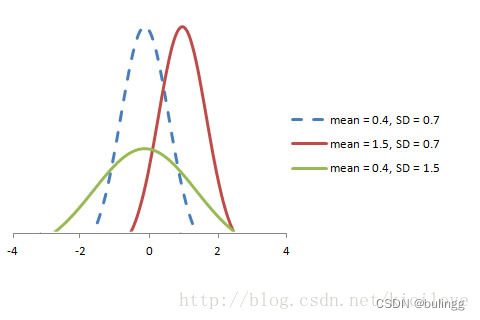
均匀分布
均匀分布是最简单的概率分布,它的所有值在相同长度的间隔内出现的概率是相等的。
f
(
x
)
=
1
b
−
a
f(x)=\frac{1}{b-a}
f(x)=b−a1
E
(
x
)
=
∫
a
b
x
f
(
x
)
d
x
=
∫
a
b
x
b
−
a
d
x
=
a
+
b
2
E(x)=\int_{a}^{b}xf(x)dx=\int_{a}^{b}\frac{x}{b-a}dx=\frac{a+b}{2}
E(x)=∫abxf(x)dx=∫abb−axdx=2a+b
D
(
x
)
=
∫
a
b
(
x
−
E
(
x
)
)
2
f
(
x
)
d
x
D(x)=\int_{a}^{b}(x-E(x))^{2}f(x)dx
D(x)=∫ab(x−E(x))2f(x)dx
处理方法:均匀分布通常不需要特殊处理,但如果需要,可以通过分箱、离散化等方法进行处理。
二项分布
二项分布是一种离散概率分布。它描述了在一系列独立的是/非试验中成功的次数的概率分布,其中每次试验的成功概率为p。
重复
n
n
n次实验,每次实验都是独立的,实验成功
x
x
x的概率为
p
(
x
)
=
C
n
x
p
x
(
1
−
p
)
n
−
x
=
n
!
(
n
−
x
)
!
x
!
p
x
(
1
−
p
)
n
−
x
p(x)=C_{n}^{x}p^{x}(1-p)^{n-x}=\frac{n!}{(n-x)!x!}p^{x}(1-p)^{n-x}
p(x)=Cnxpx(1−p)n−x=(n−x)!x!n!px(1−p)n−x
E
(
x
)
=
n
p
,
D
(
x
)
=
n
p
(
1
−
p
)
E(x)=np,D(x)=np(1-p)
E(x)=np,D(x)=np(1−p)
处理方法:二项分布通常用于分类问题中,可以通过逻辑回归、决策树等模型进行处理。
p
!
=
0.5
p!=0.5
p!=0.5时:
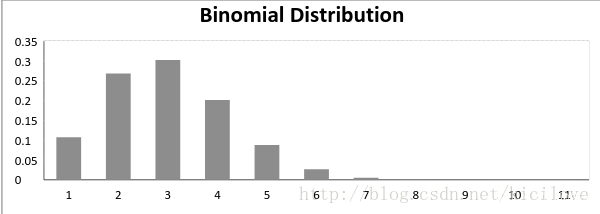
p
=
0.5
p=0.5
p=0.5时:

泊松分布
泊松分布是一种离散概率分布,描述了在固定时间或空间内发生的事件的次数的概率分布。
- 任何成功的事件都不应该影响另一个成功事件的结果。
- 在较短的时间间隔内成功的概率必须等于在较长的时间间隔内成功的概率。
- 随着间隔变小,间隔内成功的概率接近零
P ( X = x ) = e − u μ x x ! , x = 0 , 1 , 2 , ⋯ P(X=x)=e^{-u\frac{\mu^{x}}{x!}},x=0,1,2,\cdots P(X=x)=e−ux!μx,x=0,1,2,⋯
E ( x ) = μ , D ( x ) = μ E(x)=\mu,D(x)=\mu E(x)=μ,D(x)=μ
其中,
- μ \mu μ表示时间 t t t内事件发生的平均次数, μ = λ t \mu=\lambda t μ=λt,
- λ \lambda λ表示时间发生的速率,
- t t t表示时间间隔长度
-
X
X
X表示时间间隔
t
t
t内时间发生的次数
处理方法:泊松分布通常用于计数数据的模型,如泊松回归。

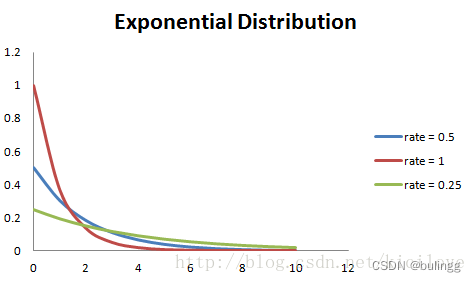
指数分布
指数分布是一种连续概率分布,可以用来表示独立随机事件发生的时间间隔。
f
(
x
)
=
λ
e
λ
x
,
x
≥
0
f(x)=\lambda e^{\lambda x},x\ge 0
f(x)=λeλx,x≥0
E
(
x
)
=
1
λ
,
D
(
x
)
=
1
λ
x
E(x)=\frac{1}{\lambda},D(x)=\frac{1}{\lambda^{x}}
E(x)=λ1,D(x)=λx1
其中,
λ
\lambda
λ表示速率,速率越大,曲线下降越快,速率越低,曲线越平滑
处理方法:指数分布通常用于生存分析或者可靠性分析的模型。
对数正态分布
对数正态分布是一种连续概率分布,如果一个随机变量的对数服从正态分布,那么该随机变量就服从对数正态分布。
l
o
g
(
x
)
∼
N
(
μ
,
σ
)
log(x)\sim N(\mu,\sigma)
log(x)∼N(μ,σ)
处理方法:对数正态分布的数据可以通过对数变换转化为正态分布,然后使用基于正态分布的统计模型进行处理。
分布之间关系
- 伯努利分布与二项分布
- 伯努利分布为二项分布的一个特例,只有一次实验
- 两者均只有两种可能的结果,即成功和失败
- 泊松分布与二项分布
泊松分布是二项分布的极限分布,条件如下:
- 试验次数足够多或者说 n → ∞ n \to \infty n→∞
- 每次试验成功的概率相同,无穷小,
- λ = n p \lambda=np λ=np,有限。
- 正态分布和二项分布 & 正态分布和泊松分布
正态分布是在以下条件下二项分布的另一种极限形式,条件如下:
- 试验次数无限大 n → ∞ n \to \infty n→∞
- p p p和 q q q都不是无限小的。
正态分布也是参数 n → ∞ n \to \infty n→∞的泊松分布的一个极限情况。















 6970
6970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









