







存储过程是一条或者多条SQL语句的集合,可视为批文件,但是其作用不仅限于批处理。
创建存储过程和函数
创建存储过程
基本语法如下:
CREATE PROCEDURE sp_name ( [proc_parameter]) [characteristics ...] routine_body;
CREATE PROCEDURE 为用来创建存储函数的关键字;sp_name为存储过程的名称;
pro_parameter:参数列表。
列表形式: [ IN | OUT | INOUT ] param_name type
characteristics:存储过程的特性,有以下取值
language sql:说明toutine_body部分是由SQL组成;
[NOT] DETERMINISTIC:指明相同的输入是否会得到相同的输出,DETERMINISTIC表示结果确定,NOT DETERMINISTIC表示不确定,默认为NOT DETERMINISTIC;
{CONTAINS SQL | NOT SQL | READS SQL DATA | MODIFIES SQL DATA }:指明子程序使用SQL的限制,其中CONTAINS SQL指不包含读写数据的SQL语句;NOT SQL 表示不包含sql语句;READS SQL DATA说明子程序包含读数据的语句;MODIFIES SQL DATA表明子程序包含写数据的语句。默认CONTAINS SQL。
SQL SECURITY{DEFINER | INVOKER }:指明谁有权限来执行,DEFINER 表示只有定义者才能执行,INVOKER 表示拥有权限的调用者可以执行,默认情况下为DEFINER。
COMMENT 'String':注释信息,可以用来描述存储过程。
routine_body:SQL代码内容,用BEGIN ... END来表示SQL代码的开始和结束。
下面的代码演示了存储过程的内容,返回所有水果的平均价格:
CREATE PROCEDURE AvgFruitPrice()
BEGIN
SELECT AVG(f_price) AS avg_price FROM fruits;
END;
BEGIN
SELECT AVG(f_price) AS avg_price FROM fruits;
END;
再例如,创建一个查看fruits表的存储过程,代码如下:
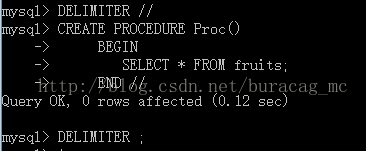
其中,DELIMITER 是将MySQL的结束符设置为 ‘//’
创建存储函数
基本语法如下:
CREATE FUNCTION func_name ( [func_parameter] )
RETURNS type
[characteristic...] routine_body
其中:
1.CREATE FUNCTION为用来创建存储函数的关键字
2.func_name表示存储函数的名称
3.func_parameter为存储过程的参数列表,参数列表形式为[IN|OUT|INOUT] param_name type,和存储过程一样
4.RETURNS type表示函数返回数据的类型
5.characteristic表示存储函数的特性,和存储过程一样
2.func_name表示存储函数的名称
3.func_parameter为存储过程的参数列表,参数列表形式为[IN|OUT|INOUT] param_name type,和存储过程一样
4.RETURNS type表示函数返回数据的类型
5.characteristic表示存储函数的特性,和存储过程一样
举个栗子~

这里创建了一个名为NameByZip的存储函数,该函数返回SELECT语句的查询结果,数值类型为字符串型。
变量的使用
1.定义变量,基本语法如下:
DECLARE var_name [,var_name] ... date_type[DEFAULT value];
var_name是局部变量名称,DEFAULT value子句为变量提供初始值。
2.为变量赋值,基本语法如下:
SET var_name = expr1[,var_name = expr2] ...;
声明三个变量,分别为var1,var2,var3,数据类型为int,使用set为变量赋值,代码如下:
DECLARE var1, var2, var3 int;
SET var1=10, var2=20;
SET var3 = var1 + var2;
还可以通过SELECT... INTO为一个或多个变量赋值:SELECT col_name[, ...] INTO var_name[, ...] table_expr。
DECLARE var_name [,var_name] ... date_type[DEFAULT value];
var_name是局部变量名称,DEFAULT value子句为变量提供初始值。
2.为变量赋值,基本语法如下:
SET var_name = expr1[,var_name = expr2] ...;
声明三个变量,分别为var1,var2,var3,数据类型为int,使用set为变量赋值,代码如下:
DECLARE var1, var2, var3 int;
SET var1=10, var2=20;
SET var3 = var1 + var2;
还可以通过SELECT... INTO为一个或多个变量赋值:SELECT col_name[, ...] INTO var_name[, ...] table_expr。
其中SELECT 语法把选定的列直接存储到相应位置的变量,col_name表示字段名称;var_name表示定义的变量名称;table_expr表示查询条件表达式,报错表名称和WHERE字句。
定义条件和处理程序
1.定义条件使用DECLARE语句,基本语法如下:
DECLARE condition_name CONDITION FOR [condition_type]
[condition_type]:
SQLSTATE [VALUE] sqlstate_value | mysql_error_code
其中,condition_name参数表示条件的名称;condition_value参数表示条件的类型;sqlstate_value参数和mysql_error_code参数都可以表示MySQL的错误。例如ERROR 1142 (42000)中,sqlstate_value值是42000,mysql_error_code值是1142。
其中,condition_name参数表示条件的名称;condition_value参数表示条件的类型;sqlstate_value参数和mysql_error_code参数都可以表示MySQL的错误。例如ERROR 1142 (42000)中,sqlstate_value值是42000,mysql_error_code值是1142。
例如:如果定义"ERROR 1142 (42000)"这个错误,名称为can_not_find。可以用两种不同的方法来定义,代码如下:
//方法一:使用sqlstate_value
//方法一:使用sqlstate_value
DECLARE can_not_find CONDITION FOR SQLSTATE '42000';
//方法二:使用mysql_error_code
DECLARE can_not_find CONDITION FOR 1142;
2.定义处理程序
使用DECLARE关键字来定义处理程序。其基本语法如下:
DECLARE handler_type HANDLER FOR condition_value [,...] sp_statement
使用DECLARE关键字来定义处理程序。其基本语法如下:
DECLARE handler_type HANDLER FOR condition_value [,...] sp_statement
handler_type: CONTINUE | EXIT | UNDO
condition_value: SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT FOUND
| SQLEXCEPTION
| mysql_error_code
其中,handler_type参数指明错误的处理方式,该参数有3个取值。这3个取值分别是CONTINUE、EXIT和UNDO。CONTINUE表示遇到错误不进行处理,继续向下执行;EXIT表示遇到错误后马上退出;UNDO表示遇到错误后撤回之前的操作,MySQL中暂时还不支持这种处理方式。
注意:通常情况下,执行过程中遇到错误应该立刻停止执行下面的语句,并且撤回前面的操作。但是,MySQL中现在还不能支持UNDO操作。因此,遇到错误时最好执行EXIT操作。如果事先能够预测错误类型,并且进行相应的处理,那么可以执行CONTINUE操作。
condition_value参数指明错误类型,该参数有6个取值。sqlstate_value和mysql_error_code与条件定义中的是同一个意思。condition_name是DECLARE定义的条件名称。SQLWARNING表示所有以01开头的sqlstate_value值。NOT FOUND表示所有以02开头的sqlstate_value值。SQLEXCEPTION表示所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值。sp_statement表示一些存储过程或函数的执行语句。
其中,handler_type参数指明错误的处理方式,该参数有3个取值。这3个取值分别是CONTINUE、EXIT和UNDO。CONTINUE表示遇到错误不进行处理,继续向下执行;EXIT表示遇到错误后马上退出;UNDO表示遇到错误后撤回之前的操作,MySQL中暂时还不支持这种处理方式。
注意:通常情况下,执行过程中遇到错误应该立刻停止执行下面的语句,并且撤回前面的操作。但是,MySQL中现在还不能支持UNDO操作。因此,遇到错误时最好执行EXIT操作。如果事先能够预测错误类型,并且进行相应的处理,那么可以执行CONTINUE操作。
condition_value参数指明错误类型,该参数有6个取值。sqlstate_value和mysql_error_code与条件定义中的是同一个意思。condition_name是DECLARE定义的条件名称。SQLWARNING表示所有以01开头的sqlstate_value值。NOT FOUND表示所有以02开头的sqlstate_value值。SQLEXCEPTION表示所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值。sp_statement表示一些存储过程或函数的执行语句。
例如定义处理程序的几种方式。代码如下:
//方法一:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info='CANNOTFIND';
//方法二:捕获mysql_error_code
DECLARE CONTINUE HANDLER FOR 1146 SET @info='CANNOTFIND';
//方法三:先定义条件,然后调用
DECLARE can_not_find CONDITIONFOR1146;
DECLARE CONTINUE HANDLER FOR can_not_find SET @info=' CANNOTFIND ';
//方法四:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info='ERROR';
//方法五:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info='CANNOTFIND';
//方法六:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTIONSET @info='ERROR';
这里附上一篇比较详细的文章:
定义条件和处理程序
光标的使用
查询语句可能返回多条记录,如果数据量非常大,需要在存储过程和存储函数中使用光标来逐条查询结果集中的记录。应用程序可以根据需要滚动或浏览其中的数据。
1.声明光标:DECLARE
cursor_name CURSOR FOR select_statement;
2.打开光标:OPEN cursor_name;
3.使用光标:FETCH cursor_name INTO var_name [,var_name]…{参数名称}
4.关闭光标:CLOSE cursor_name;
3.使用光标:FETCH cursor_name INTO var_name [,var_name]…{参数名称}
4.关闭光标:CLOSE cursor_name;
流程控制
1.IF语句,基本语法如下:
IF expr_condition THEN statement_list
[ELSEIF expr_condition THEN statement_list]...
[ELSE statement_list]
END IF
2.case语句,基本语法如下:
CASE case_expr
2.case语句,基本语法如下:
CASE case_expr
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]...
[ELSE statement_list]
END CASE
3.LOOP语句(循环操作的过程),基本语法如下:
[loop_label:] LOOP
statement_list
END LOOP [loop_label]
4.LEAVE语句(退出循环)
举个栗子~
END CASE
3.LOOP语句(循环操作的过程),基本语法如下:
[loop_label:] LOOP
statement_list
END LOOP [loop_label]
4.LEAVE语句(退出循环)
举个栗子~
Delare id int default 0;
add_loop:LOOP
SET id = id + 1;
IF id >= 10 THEN LEAVE add_loop;
END IF;
END LOOP add_loop;
5.ITERATE 语句,基本语法:ITERATE label
该语句只能出现在循环内,意为“再次循环”。
6.REPEAT语句
REPEAT创建一个带条件判断的循环的过程,每次语句执行完毕,会对条件表达式进行判断,如果表达式为真,则循环结束,否则重复循环,基本语法如下:
[repeat_label:] REPEAT
statement_list
UNTIL expr_condition
END REPEAT [repeat_label]
repeat_label为标注名称(可省略),直至expr_condition条件为真,才会退出循环。
7.WHILE语句
该语句创建带条件判断的循环过程,与REPEAT语句不同,WHILE 执行语句时先对表达式进行判断,如果为真则执行循环内语句,否则退出循环,语法形式如下:
add_loop:LOOP
SET id = id + 1;
IF id >= 10 THEN LEAVE add_loop;
END IF;
END LOOP add_loop;
5.ITERATE 语句,基本语法:ITERATE label
该语句只能出现在循环内,意为“再次循环”。
6.REPEAT语句
REPEAT创建一个带条件判断的循环的过程,每次语句执行完毕,会对条件表达式进行判断,如果表达式为真,则循环结束,否则重复循环,基本语法如下:
[repeat_label:] REPEAT
statement_list
UNTIL expr_condition
END REPEAT [repeat_label]
repeat_label为标注名称(可省略),直至expr_condition条件为真,才会退出循环。
7.WHILE语句
该语句创建带条件判断的循环过程,与REPEAT语句不同,WHILE 执行语句时先对表达式进行判断,如果为真则执行循环内语句,否则退出循环,语法形式如下:
[while_label:] WHILE expr_condition DO
statement_list
END WHILE [while_label]
statement_list
END WHILE [while_label]
调用存储过程
调用存储过程
基本语法:CALL sp_name([parameter[,...]])
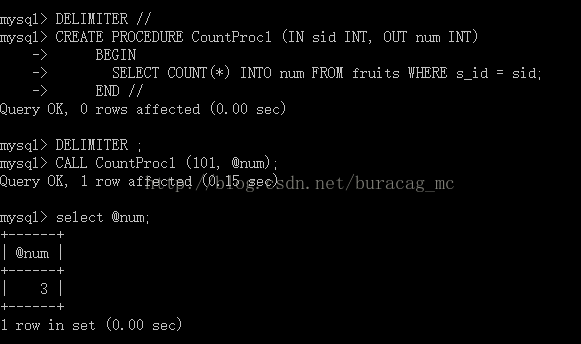
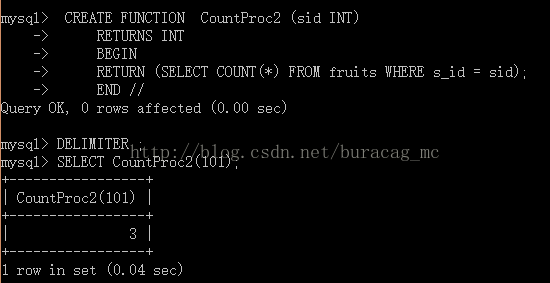
调用存储函数
MySQL中调用存储函数的使用方法和MySQL内部函数的使用方法是一样的;
示例如下:
查看存储过程和函数
1.
SHOW STATUS可以查看存储过程核函数的状态,其基本语法如下:
SHOW {PROCEDURE | FUNCTIOn} STATUS [LIKE 'pattern'];
2.使用SHOW CREATE,其基本语法如下:
SHOW CREATE {PROCEDURE | FUNCTION} sp_name;
3.从information_schema.Routines表中查看存储过程和函数,其基本语法如下:
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME = ' sp_name';
修改存储过程和函数
基本语法如下:
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
其中characteristic参数指定存储函数的特性,可能的取值有:
CONTAINS SQL:表示子程序包含SQL语句,但不包含读或写数据的语句;
NO SQL:表示子程序中不包含SQL语句;
READS SQL DATA:表示子程序中包含读数据的语句;
MODIFIES SQL DATA:表示子程序中包含写数据的语句;
SQL SECURITY { DEFINER | INVOKER }:指明谁有权限来执行;DEFINER表示只有定义者自己才能够执行,INVOKER表示调用者可以执行。
COMMENT 'string':是注释信息。
删除存储过程和函数
删除存储过程核函数,可以使用DROP语句,基本语法如下:
DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name;
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









