






前言: 解析不够, 逆向来凑
需求
需求爬取个人信息
问题
python 爬取站点个人信息, 发现页面展示和爬虫源码不符合,含有加密信息;
# 需求预期邮箱
#mailto:mbillingslea@hudson.org
<div class="social-meta">
<a href="mailto:mbillingslea@hudson.org" class="social-item email">Email</a>
</div>
# 爬虫获取邮箱
# /cdn-cgi/l/email-protection#7f121d1613131611180c131a1e3f170a1b0c101151100d18
<div class="social-meta">
<a href="/cdn-cgi/l/email-protection#7f121d1613131611180c131a1e3f170a1b0c101151100d18" class="social-item email">Email</a>
</div>
查找封装处理js
!function(){"use strict";function e(e){try{if("undefined"==typeof console)return;"error"in console?console.error(e):console.log(e)}catch(e){}}function t(e){return d.innerHTML='<a href="'+e.replace(/"/g,""")+'"></a>',d.childNodes[0].getAttribute("href")||""}function r(e,t){var r=e.substr(t,2);return parseInt(r,16)}function n(n,c){for(var o="",a=r(n,c),i=c+2;i<n.length;i+=2){var l=r(n,i)^a;o+=String.fromCharCode(l)}try{o=decodeURIComponent(escape(o))}catch(u){e(u)}return t(o)}function c(t){for(var r=t.querySelectorAll("a"),c=0;c<r.length;c++)try{var o=r[c],a=o.href.indexOf(l);a>-1&&(o.href="mailto:"+n(o.href,a+l.length))}catch(i){e(i)}}function o(t){for(var r=t.querySelectorAll(u),c=0;c<r.length;c++)try{var o=r[c],a=o.parentNode,i=o.getAttribute(f);if(i){var l=n(i,0),d=document.createTextNode(l);a.replaceChild(d,o)}}catch(h){e(h)}}function a(t){for(var r=t.querySelectorAll("template"),n=0;n<r.length;n++)try{i(r[n].content)}catch(c){e(c)}}function i(t){try{c(t),o(t),a(t)}catch(r){e(r)}}var l="/cdn-cgi/l/email-protection#",u=".__cf_email__",f="data-cfemail",d=document.createElement("div");i(document),function(){var e=document.currentScript||document.scripts[document.scripts.length-1];e.parentNode.removeChild(e)}()}();
js 简化
简单来说, 就是剔除不需要的,尽量简化到能看明白; LOOK:
function fn(n){
var a = parseInt(n.substr(0,2), 16)
for(var o="",i=0+2;i<n.length;i+=2){
var l = parseInt(n.substr(i,2), 16)^a
o+=String.fromCharCode(l)
}
return o
}
处理方式
两种处理结果方式:
1、 方法处理成 python 函数,封装结果解析;
2、 直接使用现成轮子包,处理 js2py
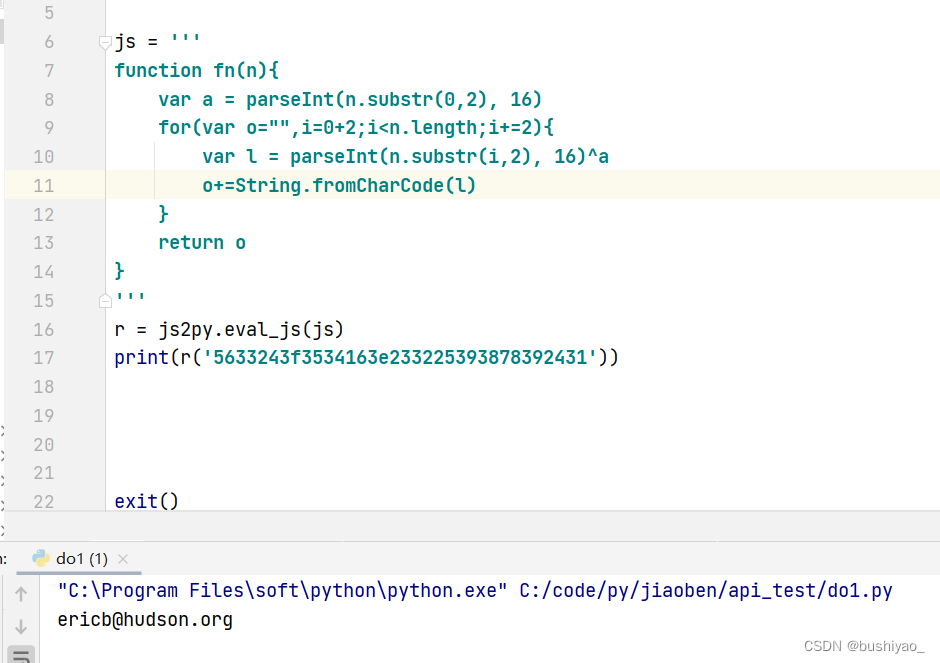
最终结果
LOOK:














 9038
9038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









