










文章来源:http://my.oschina.net/zengjie/blog/197960
目录[-]
SolrCloud是被设计用来提供一个高可用性、可容错的环境用来索引您的数据再进行搜索。在SolrCloud里面,数据都被组织成多个“块”或者叫做“shards”(分片),使数据能够存放在多台物理机器上,并且使用replicas(复制块)提供的冗余来实现可伸缩性和容错性,该系统使用一个Zookeeper服务来帮助管理整个集群结构保证了所有的索引和搜索请求能够正确的被路由到不同的节点。
This section explains SolrCloud and its inner workings in detail, but before you dive in, it's best to have an idea of what it is you're trying to accomplish. This page provides a simple tutorial that explains how SolrCloud works on a practical level, and how to take advantage of its capabilities. We'll use simple examples of configuring SolrCloud on a single machine, which is obviously not a real production environment, which would include several servers or virtual machines. In a real production environment, you'll also use the real machine names instead of "localhost", which we've used here.
本段详细解释了SolrCloud和它的内部工作的一些细节,但在你阅读之前,你最好明白你想要通过阅读本文了解到什么。本页提供一个简单的指南用来说明SolrCloud是怎么在一个实用的水平上工作的,并且学习怎么利用它的一些功能。我们将使用简单的单机SolrCloud配置示例,很明显这并不是一个真实的生产环境,真实的生产环境通常会包含多台物理服务器或是虚拟机。在生产环境中,你也需要把我们在下面例子中使用的“localhost”替换成真实机器IP或机器名。
In this section you will learn:
- How to distribute data over multiple instances by using ZooKeeper and creating shards.
- How to create redundancy for shards by using replicas.
- How to create redundancy for the overall cluster by running multiple ZooKeeper instances.
在本段你将会学习到:
- 通过使用ZooKeeper和创建多个Shard如何将数据分布到多个实例上去。
- 怎么通过使用Replica来为Shard构建冗余。
- 如何通过运行多个ZooKeeper实例为整个集群创建冗余。
Simple Two-Shard Cluster on the Same Machine
在一台机器上创建一个有两个Shard的SolrCloud集群示例
Creating a cluster with multiple shards involves two steps:
- Start the "overseer" node, which includes an embedded ZooKeeper server to keep track of your cluster.
- Start any remaining shard nodes and point them to the running ZooKeeper.
创建一个带有多个shard的SolrCloud集群包含两个步骤:
- 启动一个“overseer”节点,这个节点包含一个内嵌的ZooKeeper服务器用来跟踪监控你的集群。
- 启动剩下的shard节点并且把他们连接注册到已经启动的ZooKeeper服务器实例。
Make sure to run Solr from the example directory in non-SolrCloud mode at least once before beginning; this process unpacks the jar files necessary to run SolrCloud. However, do not load documents yet, just start it once and shut it down.
请确保操作开始之前在非SolrCloud模式下至少运行一次example目录下的Solr应用;这个操作能够解压所有运行SolrCloud所必须的jar包文件。不要添加任何文档,只需要启动一次然后停止就可以了。
In this example, you'll create two separate Solr instances on the same machine. This is not a production-ready installation, but just a quick exercise to get you familiar with SolrCloud.
在这个例子中,你将在一台机器上创建两个独立的Solr实例。生产环境不会使用这样的模式,在这里只是让你能够快速的练习使用来熟悉SolrCloud。
For this exercise, we'll start by creating two copies of the example directory that is part of the Solr distribution:
为了练习,我们将通过创建Solr发布包下面的example目录的两个拷贝开始:
|
1
2
3
|
cd
<SOLR_DIST_HOME>
cp
-r example node1
cp
-r example node2
|
These copies of the example directory can really be called anything. All we're trying to do is copy Solr's example app to the side so we can play with it and still have a stand-alone Solr example to work with later if we want.
这些example目录的拷贝可以被命名为任意名字。我们把Solr的example应用拷贝到另一个地方是为了我们能够独立使用它,假如我们稍后想要再运行Solr的话我们仍然保留了一个单独的example目录副本。
Next, start the first Solr instance, including the -DzkRun parameter, which also starts a local ZooKeeper instance:
下一步,启动第一个Solr实例,在java启动参数中加入-DzkRun 参数用来启动一个本地的ZooKeeper实例:
|
1
2
|
cd
node1
java -DzkRun -DnumShards=2 -Dbootstrap_confdir=.
/solr/collection1/conf
-Dcollection.configName=myconf -jar start.jar
|
我们来看一下这些参数的含义:
-DzkRun Starts up a ZooKeeper server embedded within Solr. This server will manage the cluster configuration. Note that we're doing this example all on one machine; when you start working with a production system, you'll likely use multiple ZooKeepers in an ensemble (or at least a stand-alone ZooKeeper instance). In that case, you'll replace this parameter with zkHost=<ZooKeeper Host:Port>, which is the hostname:port of the stand-alone ZooKeeper.
-DzkRun 在Solr中启动一个内嵌的ZooKeeper服务器。该服务会管理集群的相关配置。需要注意的是我们在做这个示例的时候都是在一个单独的物理机器上完成的;当你在生产环境上运行的时候,你或许会在集群中使用多个ZooKeeper示例(或者至少是一个单独的ZooKeeper实例).在上述的情况下,你可以把这个参数给替换成zkHost=<ZooKeeper服务器IP:端口>,实际上是那个单独的ZooKeeper的"主机名:端口"这种形式
-DnumShards Determines how many pieces you're going to break your index into. In this case we're going to break the index into two pieces, or shards, so we're setting this value to 2. Note that once you start up a cluster, you cannot change this value. So if you expect to need more shards later on, build them into your configuration now (you can do this by starting all of your shards on the same server, then migrating them to different servers later).
-DnumShards 该参数确定了你要把你的数据分开到多少个shard中。在这个例子中,我们将会把数据分割成两个分块,或者称为shard,所以我们把这个值设置为2。注意,在你第一次启动你的集群之后,这个值就不能再改变了,所以如果你预计你的索引在日后可能会需要更多的shard的话,你现在就应该把他们规划到到你的配置参数中(你可以在同一个服务上启动所有的shard,在日后再把它们迁移到不同的Solr实例上去。)
-Dbootstrap_confdir ZooKeeper needs to get a copy of the cluster configuration, so this parameter tells it where to find that information.
-Dbootstrap_confdir ZooKeeper需要准备一份集群配置的副本,所以这个参数是告诉SolrCloud这些配置是放在哪里。
-Dcollection.configName This parameter determines the name under which that configuration information is stored by ZooKeeper. We've used "myconf" as an example, it can be anything you'd like.
-Dcollection.configName 这个参数确定了保存在ZooKeeper中的索引配置的名字。在这里我们使用了“myconf”作为一个例子,你可以使用任意你想要使用的名字来替换。
The -DnumShards, -Dbootstrap_confdir, and -Dcollection.configName parameters need only be specified once, the first time you start Solr in SolrCloud mode. They load your configurations into ZooKeeper; if you run them again at a later time, they will re-load your configurations and may wipe out changes you have made.
-DnumShards, -Dbootstrap_confdir和-Dcollection.configName参数只需要在第一次将Solr运行在SolrCloud模式的时候声明一次。它们可以把你的配置加载到ZooKeeper中;如果你在日后重新声明了这些参数重新运行了一次,将会重新加载你的配置,这样你在原来配置上所做的一些修改操作可能会被覆盖。
At this point you have one sever running, but it represents only half the shards, so you will need to start the second one before you have a fully functional cluster. To do that, start the second instance in another window as follows:
这时候你已经有一个Solr服务在运行了,但是它仅仅代表的是你全部shard的一半,所以在你组建成一个拥有完整功能的Solr集群之前还需要启动第二个Solr服务。接下来,在新的窗口中启动第二个实例,如下:
|
1
2
|
cd
node2
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
|
因为该节点不是一个overseer节点,所以它的参数就稍微没有那么复杂了:
-Djetty.port The only reason we even have to set this parameter is because we're running both servers on the same machine, so they can't both use Jetty's default port. In this case we're choosing an arbitrary number that's different from the default. When you start on different machines, you can use the same Jetty ports if you'd like.
-Djetty.port 我们需要设置这个参数的原因只有一个,那就是我们在一台机器上运行了两个Solr实例,所以它们不能全用jetty的默认端口作为http监听端口。在这个例子中,我们使用了一个和默认端口号不相同的任意端口号。当你在不同的机器上启动Solr集群的时候,你可以使用任意的端口号作为jetty的监听端口号。
-DzkHost This parameter tells Solr where to find the ZooKeeper server so that it can "report for duty". By default, the ZooKeeper server operates on the Solr port plus 1000. (Note that if you were running an external ZooKeeper server, you'd simply point to that.)
-DzkHost 这个参数告诉Solr去哪里找ZooKeeper服务来“报到”。默认情况下,ZooKeeper服务的端口号是在Solr的端口号上加上1000。(注意:如果你运行了一个外部的ZooKeeper服务的话,你只需要简单的将这个参数值指向ZooKeeper服务的地址)
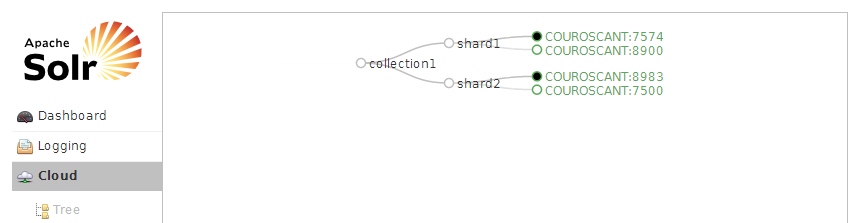
At this point you should have two Solr windows running, both being managed by ZooKeeper. To verify that, open the Solr Admin UI in your browser and go to theCloud screen:
现在你已经有两个Solr实例在运行了,它们都在同一个ZooKeeper的管理之下。为了验证一下,在你的浏览器中打开Solr Admin UI然后跳转到Cloud screen界面:
http://localhost:8983/solr/#/~cloud
Use the port of the first Solr you started; this is your overseer. You can go to the
You should see both node1 and node2, as in:
使用你启动的第一个Solr的端口号,它是你的SolrCloud集群的overseer节点。你可以在这个界面中同时看到节点1和节点2,如图所示:

Now it's time to see the cluster in action. Start by indexing some data to one or both shards. You can do this any way you like, but the easiest way is to use theexampledocs, along with curl so that you can control which port (and thereby which server) gets the updates:
现在是时候看看集群的运转情况了。开始索引若干数据到单个shard或者全部的两个shard。你可以用任意你喜欢的方式来提交数据,但是最简单的方式是使用example里面的示例文档数据连同curl一起使用,这样你就可以自己选择哪个端口(就是选择哪个Solr服务)来处理这些更新请求:
|
1
2
|
curl http:
//localhost
:8983
/solr/update
?commit=
true
-H
"Content-Type: text/xml"
-d
"@mem.xml"
curl http:
//localhost
:7574
/solr/update
?commit=
true
-H
"Content-Type: text/xml"
-d
"@monitor2.xml"
|
到这个时候每个shard都包含了全部文档中的一部分数据,任意一个到达Solr的搜索请求最终都会跨越两个shard处理。举个例子,下面的这两个搜索操作都会返回同样的结果集:
http://localhost:8983/solr/collection1/select?q=*:*
http://localhost:7574/solr/collection1/select?q=*:*
The reason that this works is that each shard knows about the other shards, so the search is carried out on all cores, then the results are combined and returned by the called server.
出现这样结果的原因是因为每个shard都知道集群中其他的shard的情况,所以搜索操作都会在所有的core上执行,最终结果是由最初接受请求的Solr合并并且返回给调用者的。
In this way you can have two cores or two hundred, with each containing a separate portion of the data.
通过这种方式你可以得到两个solr core,每个core都包含了整个数据集的一部分。
If you want to check the number of documents on each shard, you could add distrib=false to each query and your search would not span all shards.
如果你想要检查每个shard上面的文档数量,你可以在每个查询请求上添加一个参数 distrib=false,这样搜索操作就不会跨越每一个shard操作了。
But what about providing high availability, even if one of these servers goes down? To do that, you'll need to look at replicas.
但是在这些Slor服务中如果有一台服务宕机的情况下如何继续提供高可用性呢?为了实现这个目标,你需要了解一下Replica节点
Two-Shard Cluster with Replicas
带有两个Shard节点以及若干Replica节点的集群
In order to provide high availability, you can create replicas, or copies of each shard that run in parallel with the main core for that shard. The architecture consists of the original shards, which are called the leaders, and their replicas, which contain the same data but let the leader handle all of the administrative tasks such as making sure data goes to all of the places it should go. This way, if one copy of the shard goes down, the data is still available and the cluster can continue to function.
为了提供高可用性,你可以创建Replica,或者可以称为和该Shard的主core并行运行的一个副本。这个结构由原始的Shard和它的一些副本构成,我们把原始的那个Shard叫做Leader,用来处理所有的管理相关的请求,例如用来确保数据去往它应该去的地方,而Replica仅仅是包含了和Leader一模一样的数据的一个副本。通过这种方式,假如该Shard的一个副本宕机了,那么整个Shard的数据仍然是可用的,并且集群仍然可用继续正常提供服务。
Start by creating two more fresh copies of the example directory:
首先创建原始example目录的两个新副本:
|
1
2
3
|
cd
<SOLR_DIST_HOME>
cp
-r example node3
cp
-r example node4
|
就像我们第一次创建两个shard一样,你可以给这些拷贝的目录命名为任意的名字。
If you don't already have the two instances you created in the previous section up and running, go ahead and restart them. From there, it's simply a matter of adding additional instances. Start by adding node3:
如果在上一段中你已经创建好的两个实例还没有启动并正常运行,先重启它们。然后,添加额外的SolrCloud实例就是一件简单的事情了。开始添加节点3:
|
1
2
|
cd
node3
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
|
需要注意的是这些参数恰恰是和我们启动的第二个节点的参数是一样的;简单的将你的新实例指向原来的ZooKeeper即可。这时候你看一下SolrCloud的管理页面,你就会发现新添加的节点并没有成为第三个Shard,而是第一个Shard的一个Replica(副本)

This is because the cluster already knew that there were only two shards and they were already accounted for, so new nodes are added as replicas. Similarly, when you add the fourth instance, it's added as a replica for the second shard:
这是因为集群已经知道它负责维护的Shard只有两个并且都已经存在了,所以新添加的节点只能够作为Replica存在了。同样道理,当你添加第四个实例的时候,它会被当做第二个Shard的Replica添加进集群:
|
1
2
|
cd
node4
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
|

If you were to add additional instances, the cluster would continue this round-robin, adding replicas as necessary. Replicas are attached to leaders in the order in which they are started, unless they are assigned to a specific shard with an additional parameter of shardId (as a system property, as in -DshardId=1, the value of which is the ID number of the shard the new node should be attached to). Upon restarts, the node will still be attached to the same leader even if the shardId is not defined again (it will always be attached to that machine).
如果你继续添加额外的实例,集群将会继续进行重复上述的操作,必要时把它们当做Replica添加进去。每当Replica启动后它们会自动有序的附加到Leader节点上,除非它们通过一个额外的shardId参数(这个参数声明为system property参数,例如 -DshardId=1,这个参数的值就是新的节点想要附加的Shard的id值)来分配到指定的Shard。如果重启了某一个节点,它仍然会被附加到原来的Leader上(无论如何,它总会附加到同一台机器上),前提是shardId没有重新定义。
So where are we now? You now have four servers to handle your data. If you were to send data to a replica, as in:
那我们现在处在一种什么情况下?我们已经有了4个Solr服务来处理你的数据。如果你想要发送数据到replica节点的话,执行:
|
1
|
curl http:
//localhost
:7500
/solr/update
?commit=
true
-H
"Content-Type: text/xml"
-d
"@money.xml"
|
- Replica (in this case the server on port 7500) gets the request.
- Replica forwards request to its leader (in this case the server on port 7574).
- The leader processes the request, and makes sure that all of its replicas process the request as well.
执行的情况可能跟下面描述的相似:
- Replica(在本例中是端口为7500的节点)接收到请求
- Replica将请求转发至它的Leader节点(在本例中是端口为7574的节点)
- Leader节点最终处理该请求,并且确保所有附加在它上面的Replica节点也处理这个请求。
In this way, the data is available via a request to any of the running instances, as you can see by requests to:
通过这种方式,请求到集群中任意一个实例的请求数据都能够得到有效处理,你可以通过下面的请求观察:
http://localhost:8983/solr/collection1/select?q=*:*
http://localhost:7574/solr/collection1/select?q=*:*
http://localhost:8900/solr/collection1/select?q=*:*
http://localhost:7500/solr/collection1/select?q=*:*
But how does this help provide high availability? Simply put, a cluster must have at least one server running for each shard in order to function. To test this, shut down the server on port 7574, and then check the other servers:
但是这种方式是怎么帮助我们提供高可用性的呢?简单的说,如果一个集群想要正常运行则每一个Shard都必须至少有一个节点是正常运行的。为了测试一下这种情况,关闭端口为7574的节点,然后检查其他节点:
http://localhost:8983/solr/collection1/select?q=*:*
http://localhost:8900/solr/collection1/select?q=*:*
http://localhost:7500/solr/collection1/select?q=*:*
You should continue to see the full set of data, even though one of the servers is missing. In fact, you can have multiple servers down, and as long as at least one instance for each shard is running, the cluster will continue to function. If the leader goes down – as in this example – a new leader will be "elected" from among the remaining replicas.
接下来你应该可以看到完整的数据,即便是一个节点已经挂掉。事实上,你可以停掉多个节点,只要某一个shard有一个节点处于正常运行状态,整个集群都可以正常运行。像本例中这样,如果Leader节点宕机了,一个新的Leader将会从剩下的Replica节点中被选举出来。
Note that when we talk about servers going down, in this example it's crucial that one particular server stays up, and that's the one running on port 8983. That's because it's our overseer – the instance running ZooKeeper. If that goes down, the cluster can continue to function under some circumstances, but it won't be able to adapt to any servers that come up or go down.
需要注意的是本例中所说并不是所有的节点都可以随时宕机,在本例中我们有一个特殊的重要节点需要一直保持正常运行,就是那个运行在端口8983上的节点。这是因为它是我们的overseer节点,这个节点实例中运行了维护集群状态的ZooKeeper。如果这个节点也挂掉了的话,整个集群在某些情况下可能仍然能够正常运转,但是却不能处理任何节点新增或者宕机的情况。
That kind of single point of failure is obviously unacceptable. Fortunately, there is a solution for this problem: multiple ZooKeepers.
这种单点故障的情况显然是无法接受的。幸运的是,有一个方法可以解决这个问题:多ZooKeeper集群。
Using Multiple ZooKeepers in an Ensemble
在集群中使用多ZooKeeper集群
To simplify setup for this example we're using the internal ZooKeeper server that comes with Solr, but in a production environment, you will likely be using an external ZooKeeper. The concepts are the same, however. You can find instructions on setting up an external ZooKeeper server here:http://zookeeper.apache.org/doc/r3.3.4/zookeeperStarted.html
为了使本例能够简单的安装使用,我们使用了Solr中内置的ZooKeeper服务,但是在生产环境上,你很可能会使用一个外部的ZooKeeper服务。它们的功能是一样的。你可以在下面这个网址上面找到怎么单间一个外部的ZooKeeper服务的介绍:http://zookeeper.apache.org/doc/r3.3.4/zookeeperStarted.html
To truly provide high availability, we need to make sure that not only do we also have at least one shard server running at all times, but also that the cluster also has a ZooKeeper running to manage it. To do that, you can set up a cluster to use multiple ZooKeepers. This is called using a ZooKeeper ensemble.
为了提供真正的高可用性,我们需要确保的不仅仅只是至少有一个Shard节点一直在运行,我们还要确保整个集群至少有一个ZooKeeper服务来管理这个集群。为了达到这个目的,你可以使用多个ZooKeeper服务器来搭建集群。也可以叫做使用ZooKeeper ensemble集群。
A ZooKeeper ensemble can keep running as long as more than half of its servers are up and running, so at least two servers in a three ZooKeeper ensemble, 3 servers in a 5 server ensemble, and so on, must be running at any given time. These required servers are called a quorum.
一个ZooKeeper ensemble能够在集群中有一半以上的节点存活的时候正常运行,所以在3个ZooKeeper ensemble中我们需要至少两个节点正常运行,5个的话需要3个节点正常,以此类推,必须在任意特定的时间都需要保持正常运行。这个在一个集群中必须同时正常运行的节点数叫做quorum。
In this example, you're going to set up the same two-shard cluster you were using before, but instead of a single ZooKeeper, you'll run a ZooKeeper server on three of the instances. Start by cleaning up any ZooKeeper data from the previous example:
在本例中,你将会建立一个和之前一模一样的带有两个Shard的集群,但是不是使用一个单独的ZooKeeper,ZooKeeper会在这些实例中的三个上面运行。先清除一下上一个例子中所产生的所有ZooKeeper数据:
|
1
2
|
cd
<SOLR_DIST_DIR>
rm
-r node*
/solr/zoo_data
|
接下来重启所有的Solr节点,但是这次,每个节点都会运行ZooKeeper而且监听ZooKeeper ensemble中的剩下节点以执行相关指令,而不是将他们简单的指向一个单独的ZooKeeper实例。
You're using the same ports as before – 8983, 7574, 8900 and 7500 – so any ZooKeeper instances would run on ports 9983, 8574, 9900 and 8500. You don't actually need to run ZooKeeper on every single instance, however, so assuming you run ZooKeeper on 9983, 8574, and 9900, the ensemble would have an address of:
你可以使用和之前例子中使用的相同的端口号——8983,7574,8900 和7500,这样的话所有ZooKeeper实例将会分别运行在端口9983,8574,9900和8500上。事实上你并不需要在每一个实例上面都运行一个ZooKeeper服务,但是如果仅仅在993,8574和9900上运行zookeeper服务的话,ZooKeeper ensemble会拥有如下地址:
|
1
|
localhost:9983,localhost:8574,localhost:9900
|
This means that when you start the first instance, you'll do it like this:
这意味着你启动第一个实例的时候,你将这样做:
|
1
2
|
cd
node1
java -DzkRun -DnumShards=2 -Dbootstrap_confdir=.
/solr/collection1/conf
-Dcollection.configName=myconf -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
|
Note that the order of the parameters matters. Make sure to specify the -DzkHost parameter after the other ZooKeeper-related parameters.
注意相关参数声明的顺序问题,确保把-DzkHost声明在所有其他和ZooKeeper相关的参数之前。
You'll notice a lot of error messages scrolling past; this is because the ensemble doesn't yet have a quorum of ZooKeepers running.
你将会看到大量的错误信息滚动过屏幕;这是因为这个ZooKeeper ensemble中运行的节点数还没有达到需要的数量。
Notice also, that this step takes care of uploading the cluster's configuration information to ZooKeeper, so starting the next server is more straightforward:
同样需要注意的是,这个步骤上传了集群的相关配置信息到ZooKeeper中去,所以启动下一个节点就变得略简单了:
|
1
2
|
cd
node2
java -Djetty.port=7574 -DzkRun -DnumShards=2 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
|
Once you start this instance, you should see the errors begin to disappear on both instances, as the ZooKeepers begin to update each other, even though you only have two of the three ZooKeepers in the ensemble running.
一旦你启动了这个实例,你应该看到错误在两个实例中都开始消失了,因为ZooKeeper开始更新了彼此的信息,即使在你的三个节点组成的ZooKeeper ensemble中只有两个节点在运行。
Next start the last ZooKeeper:
接下来启动最后一个ZooKeeper:
|
1
2
|
cd
node3
java -Djetty.port=8900 -DzkRun -DnumShards=2 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
|
Finally, start the last replica, which doesn't itself run ZooKeeper, but references the ensemble:
最后,启动最终的Replica节点,这个节点本身不运行ZooKeeper,但是会引用到已经启动的ZooKeeper ensemble。
|
1
2
|
cd
node4
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
|
为了确保所有环节都正常的工作了,执行一个查询请求:
http://localhost:8983/solr/collection1/select?q=*:*
and check the SolrCloud admin page:
然后检查SolrCloud管理界面:
Now you can go ahead and kill the server on 8983, but ZooKeeper will still work, because you have more than half of the original servers still running. To verify, open the SolrCloud admin page on another server, such as:
现在你可以返回前面的目录然后关掉在端口8983上面的节点,但是ZooKeeper将仍然正常运行,因为你拥有超过原始ZooKeeper节点数一半的节点都在正常运行。为了确保这一点,打开其他节点的SolrCloud管理页面,如下所示:
http://localhost:8900/solr/#/~cloud

第一章 完

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









