






Datawhale X 李宏毅苹果书 AI夏令营【Task 1】
因为比较小白,所以内容理解的可能比较浅(私密马赛),没什么很深的理解
1、基础概念:
1.1 函数
这个函数我理解的就像一个转换器,可以输入xxx,然后转换成你需要的数据或者是任何东西
eg:
比如语音识别,机器听一段声音,产生这段声音对应的文字。
> 由这个"函数"可以引出下面这些概念:👉
1.2 回归
假设要找的函数的输出是一个数值,一个标量(scalar),这种机器学习的任务叫做回归
eg:
假设机器要预测未来某一个时间的 PM2.5 的数值。机器要找一个函数 f,其输入是可能是种种跟预测 PM2.5 有关的指数,包括今天的 PM2.5 的数值、平均温度、平均的臭氧浓度等等,输出是明天中午的 PM2.5的数值
1.3 分类
分类任务要让机器做选择题。人类先准备好一些选项,这些选项称为类别(class),现在要找的函数的输出就是从设定好的选项里面选择一个当作输出,该任务称为分类
eg:
每个人都有邮箱账户,邮箱账户里面有一个函数,该函数可以检测一封邮件是否为垃圾邮件。分类不一定只有两个选项,也可以有多个选项。
1.4 结构化学习
指不仅仅让机器输出一个简单的结果(比如选择题的答案或一个数字),而是让机器生成或预测一个有特定结构的复杂对象。这个对象可能是有很多部分组成的,有一定的关系和组织形式。
eg:
比如让机器画一张图,写一篇文章。
1.5 领域知识(domain knowledge)
领域知识是指在某个特定领域或学科中积累的专业知识和经验。
eg:
如果你学习很多关于数学的知识,那么你在数学这个领域就有一定的领域知识。领域知识帮助你更好地理解和解决在这个领域里遇到的问题。
1.6 线性回归方程
from案例学习(结合苹果书的案例可能会有更好的理解)
y = w x + b y = wx + b y=wx+b
模型(model)
带有参数的未知数,这里的w和b就是未知数,即模型
特征(feature)
函数里面的已知的部分,就是这里的x,我们需要根据这个x去进行预测,是已知的,即特征
权重(weight)
权重就是一个数字,它告诉我们每个部分有多重要。机器学习模型会用这些权重来决定哪些信息更重要,然后做出决定。也就是这里的w
偏置(bias)
偏置就像是一个额外的分数,帮助模型得到更合理的结果。可以把它想成“秘密武器”,让模型的预测更准确!来修正结果用的
1.7 损失(loss)(损失函数)
案例学习(结合苹果书的案例可能会有更好的理解)
用来告诉机器学习模型它做得好不好的一种方法。可以把它想象成一个“错误评分”。
输入参数
函数的输入是模型里面的参数,模型是 y = b + w ∗ x1,而 b 跟 w 是未知的,损失是函数 L(b, w),其输入是模型参数 b 跟w
输出值
也就是上面说的“错误评分”,当然是越小越好(模型的目标就是通过不断调整内部参数(比如权重和偏置),来最小化这个“错误评分”)
几种常见的损失函数
平均绝对误差(Mean Absolute Error, MAE)
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
用来衡量模型的预测值和真实值之间的平均差异
使用场景:
常用于回归
案例:
预测房价、股票价格、温度等
均方误差 (Mean Squared Error, MSE)
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
用来衡量模型的预测值和真实值之间的平方的差距
使用场景:
常用于回归问题
需要强调大错误的场景(平方后,对于错误更加敏感),常常使用梯度下降法(下面会提到)来最小化 MSE。
数据分布均匀的场景
案例:
金融预测(小的错误,会造成大的损失)
交叉熵损失(Cross-Entropy Loss)
H ( p , q ) = − ∑ i p ( x i ) log ( q ( x i ) ) H(p, q) = -\sum_{i} p(x_i) \log(q(x_i)) H(p,q)=−i∑p(xi)log(q(xi))
交叉熵的核心思想是通过一个公式来衡量两个概率分布之间的差异。根据不同的场景会有不同的变式,上面是交叉熵基础公式(演变成其他公式)
使用场景:
多使用于分类问题
案例:
垃圾邮件分类器
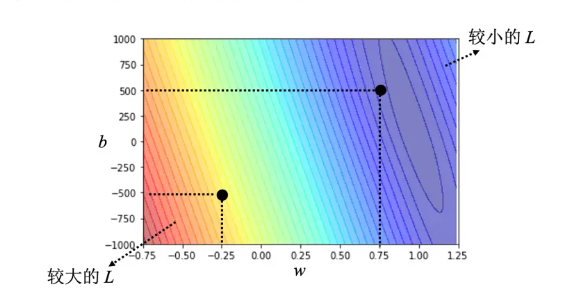
下面是一个根据交叉熵画出的误差表面(from案例学习)
可以看成一个等高线图,越偏红色系,代表计算出来的损失越大,就代表这一组 w 跟 b 越差,越偏蓝色系,就代表损失越小,就代表这一组 w 跟 b 越好,放到函数里面,预测会越精准,明显(0.75,500)这一组要好于(-0.25,-500)这一组
铰链损失(Hinge Loss)
Loss = max ( 0 , 1 − y i ⋅ y ^ i ) \text{Loss} = \max \left(0, 1 - y_i \cdot \hat{y}_i \right) Loss=max(0,1−yi⋅y^i)
对数损失 (Logarithmic Loss)
二分类:
Loss
=
−
1
n
∑
i
=
1
n
[
y
i
log
(
y
^
i
)
+
(
1
−
y
i
)
log
(
1
−
y
^
i
)
]
\text{Loss} = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right]
Loss=−n1i=1∑n[yilog(y^i)+(1−yi)log(1−y^i)]
多分类:
Loss
=
−
1
n
∑
i
=
1
n
∑
c
=
1
C
y
i
,
c
log
(
y
^
i
,
c
)
\text{Loss} = -\frac{1}{n} \sum_{i=1}^{n} \sum_{c=1}^{C} y_{i,c} \log(\hat{y}_{i,c}) \
Loss=−n1i=1∑nc=1∑Cyi,clog(y^i,c)
1.8 梯度下降(gradient descent)
目标:
我们有一个“错误分数”(也就是损失函数),这个分数告诉我们模型做得有多差。我们的目标是让这个分数尽可能小,模型就会表现得更好。
调整步骤:
梯度下降就像是你在玩一款迷宫游戏。你站在一个高处,想要走到最低点。梯度下降会告诉你每一步该往哪个方向走才能尽快到达低点。
不断重复:
你会一遍又一遍地走,每次都稍微调整一下方向,直到你到达最低点(也就是错误最小的地方)。
缺点:
1 容易陷入局部最小值,可能找不到最好的结果(在wT的时候停了,但最右边红点才是全局最优解)
2 学习率难控制
步子太大:走得步子太大,可能会错过目标点,反而变得更糟。
步子太小:走得步子太小,虽然能更稳,但可能需要很长时间才能到达目标点
3 训练时间长
数据多:如果有很多数据,每次训练都会很慢,就像你要检查每一个数据点。
模型复杂:如果模型很复杂,每一步的计算都可能很耗时。
4 无法收敛(可能不能停止在最好的地方)
有时候,尽管你一直在努力训练,模型可能也无法找到最好的解
(图from案例学习)
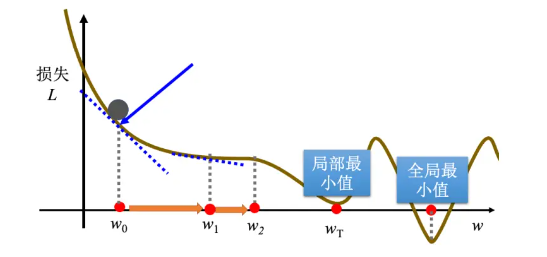
1.9 学习率:
学习率决定了你每次沿着斜率方向走多远。就像你在下坡时选择迈多大的步子。
学习率就是调整模型参数时的步子大小。它决定了模型在学习过程中每一步的幅度,要么走得快但可能不准确,要么走得慢但更精确。选择合适的学习率能够帮助模型更快地找到最佳答案。
1.10 超参数(hyperparameter)
指在机器学习模型训练过程中需要预先设定的参数,它们不会在模型训练过程中自动更新,而是由我们手动设置的。
常见的超参数
学习率
迭代次数(Epochs):让模型看几遍数据的次数。
批量大小(Batch Size):这是每次训练时使用的数据量。
正则化参数:防止模型过拟合
2、隐藏任务
③ 找出机器学习找函数的3个步骤!并查找资料,交叉佐证这些步骤。
1、写出一个带有未知参数的函数(确定模型)
2、设置损失函数loss
3、求解出使损失达到最小的参数(最优解)
④ 归纳梯度下降的步骤。
选择初始参数:开始时随便选一个起点。
计算梯度:找出当前点的坡度。
更新参数:根据坡度和学习率调整参数。
重复:不断更新参数,直到满足停止条件。
举个例子:
开始:你在一个山上,随便选择一个位置开始。
看坡度:你看看哪个方向下坡最陡。
走一步:你向下坡最陡的方向走一步。
重复:你继续走,每次都查看坡度,找到更低的地方。
停止:你走到一个坡度很小的地方,或者走了很长时间,就停下。
⑤ 为什么局部最小是一个假问题,局部最小怎么解决?真正的难题是什么?
怎么解决:
多试几次:从不同的地方开始找,可能会找到更好的地方。
使用特殊的方法:像是随机变化(随机梯度下降)或记住过去的步子(动量法),这些方法可以找到更好的结果。
难题:
有很多小的局部最小,找到全局最优很困难。















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









