






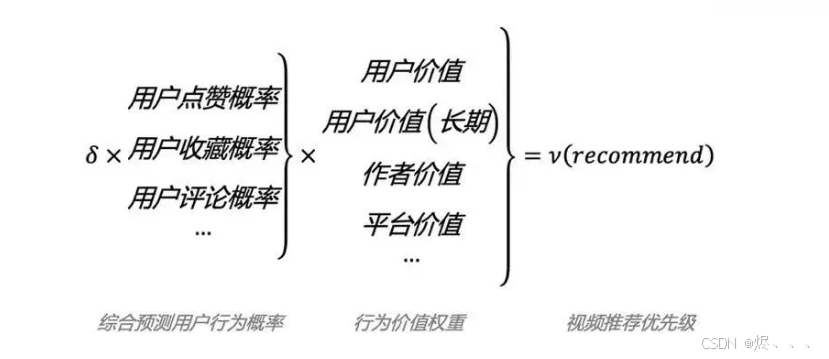
核心问题:信息太多,看不过来!
想象一下,现在的互联网就像一个超级巨大的图书馆,每秒钟都有成千上万本新书、新杂志、新视频、新音乐冒出来。你一个人根本不可能看完所有东西,甚至都不知道从哪里开始找自己喜欢的内容。这就叫“信息爆炸”。
推荐系统
推荐系统就像一个特别懂你的“私人助理”或者“信息快递员”。它的任务就是从这堆积如山的信息里,帮你挑出你最可能感兴趣的东西,然后送到你面前。
- 例子:
- 你打开抖音、快手,它会自动给你刷你喜欢看的短视频。
- 你逛淘宝、京东,它会给你推荐你可能想买的商品(比如“猜你喜欢”)。
- 你看奈飞、腾讯视频,它会给你推荐你可能想看的电影电视剧。
- 你听网易云音乐、QQ音乐,它会给你推荐你可能喜欢的歌曲。
这些都是推荐系统在背后悄悄帮你“过滤”和“挑选”。
推荐系统是怎么发展来的?
- 门户网站(像以前的新浪、搜狐首页): 就像一个大报纸或大商场,把信息分门别类(新闻、体育、娱乐等)。你自己去找感兴趣的栏目。
- 搜索引擎(像百度、谷歌): 你想知道什么,就输入关键词去搜。你得主动。
- 社交网络(像微信朋友圈、微博早期): 你关注了谁,谁就能把信息“推”给你。信息来源是你自己选的人。
- 推荐系统(现在的主流): 系统更主动、更“聪明”地猜你喜欢什么,然后推送给你。
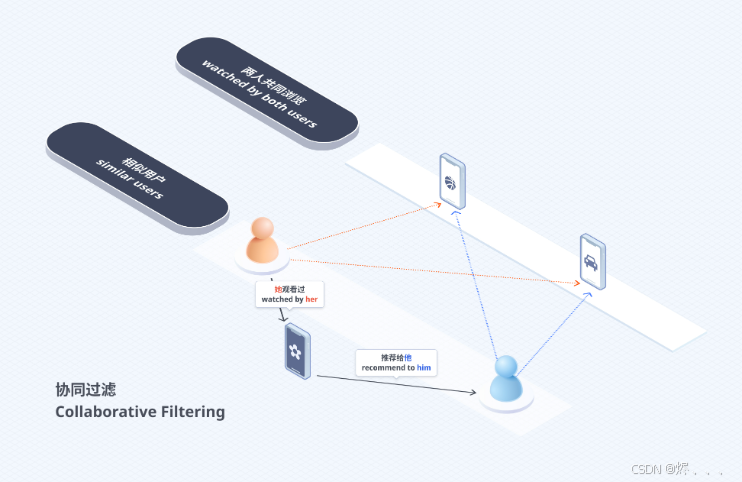
“老办法”:协同过滤(CF)—— “物以类聚,人以群分”
这是最早也很有用的一种方法,核心思想很简单:
- “跟你口味差不多的人,他们喜欢的东西,你可能也喜欢。”
- 例子1(用户相似): 比如你喜欢电影A、B、C。小明也喜欢电影A、B、C。这时候小明又看了一部电影D,并且非常喜欢。那系统就会猜,你可能也会喜欢电影D,于是推荐给你。
- 例子2(物品相似): 很多人都同时喜欢了奶茶和炸鸡。那么,如果你买了奶茶,系统可能会给你推荐炸鸡。
- 它不需要“理解”内容本身: 系统不用知道电影A是科幻片,电影D是爱情片。它只看“用户行为”(比如谁看了什么,谁买了什么,谁给什么点了赞)。
- 数学小工具: 文中提到的“余弦相似度”就是一种计算“你和小明有多像”或者“奶茶和炸鸡关联度有多高”的数学方法。可以想象成,把每个人的喜好画在图上,如果两个人的点离得很近,那他们口味就相似。
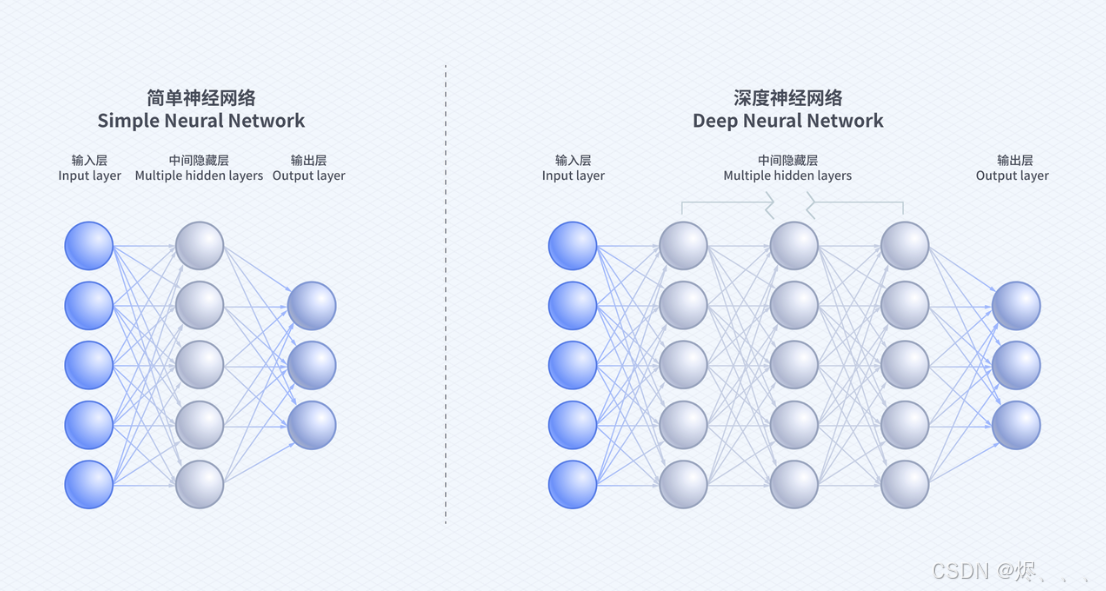
“新武器”:深度学习与神经网络 —— 更聪明的大脑
随着技术发展,推荐系统也升级了,用上了“深度学习”,它的大脑就是“神经网络”。
-
什么是神经网络?
- 它是模仿我们人类大脑神经元工作方式的一种计算模型。
- 例子(抓小偷):
- 输入层(小区保安): 保安收集小偷的原始特征,比如“戴黑帽子”、“穿红衣服”、“背双肩包”。这些是基本信息。
- 隐藏层(一群侦探):
- 侦探A发现:“黑帽子+红衣服”的人经常在便利店出现。
- 侦探B发现:“双肩包+上午8点”可能跟快递被偷有关。
- 侦探C综合所有线索,画出更精准的嫌疑人画像。
- “隐藏层”可以有很多层,每层侦探都在前一层的基础上做更复杂的分析和推理。层数越多,分析能力可能就越强(所以叫“深度”学习)。
- 输出层(警长): 警长拿到所有侦探的分析报告,做出最终判断:“没错,就是上周那个惯犯张三!”
- 训练过程: 一开始侦探们也可能抓错人。警长会告诉他们:“上次把外卖小哥当小偷了,因为你们没注意他穿的是外卖服,而且是在送餐时间。” 侦探们吸取教训,下次就会调整判断标准。不断练习,他们就成了抓小偷专家。推荐系统也是这样,通过大量数据不断学习和调整,变得越来越准。
-
深度学习的好处:
- 看得更深: 能从数据中挖出更隐藏、更复杂的规律。
- 更灵活: 可以根据不同的场景(比如视频推荐、商品推荐)调整“大脑”的结构。
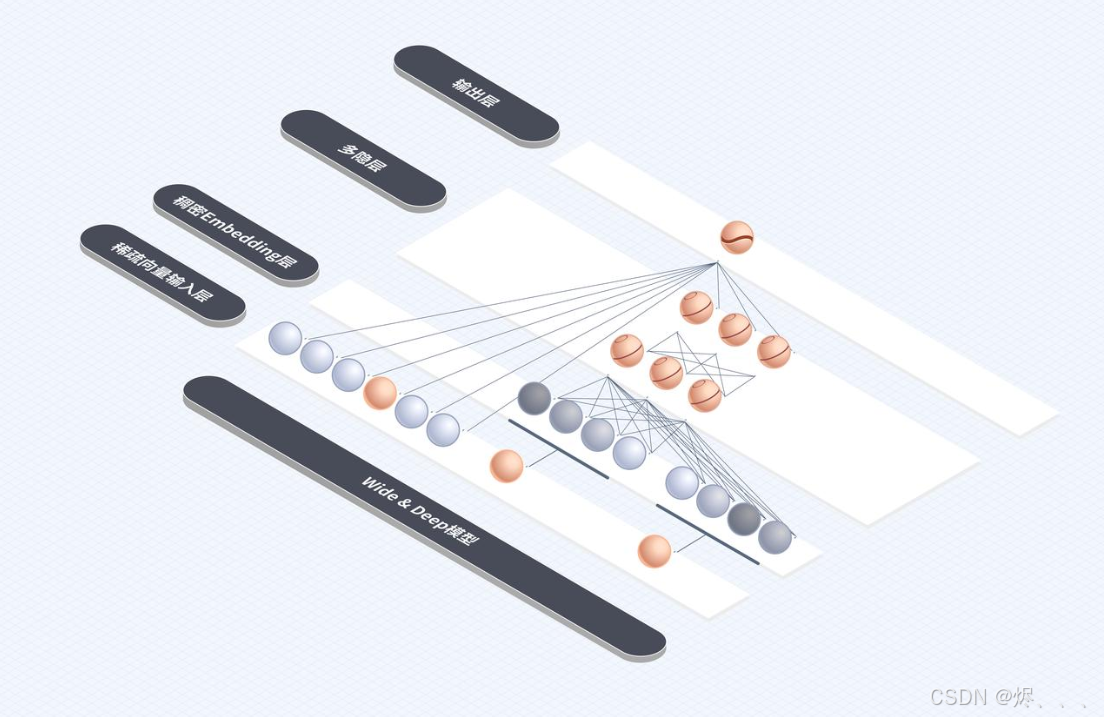
抖音在用的两种“新武器”的模型
1. Wide & Deep 模型(既能记住老经验,又能发现新大陆)
Wide部分(记忆力强)
负责记住那些简单直接的规律。比如“你以前喜欢看猫咪视频,那这个新的猫咪视频你可能也喜欢。” 它擅长处理那些出现频率高、关联明显的特征。
Deep部分(泛化能力强,能举一反三)
负责挖掘更深层次、更想不到的联系。比如,它发现你喜欢“节奏感强的音乐”和“舞蹈视频”,那么即使你没看过某个特定类型的舞蹈,只要配乐节奏感强,它也可能推荐给你。它能发现一些稀有的、甚至以前没出现过的特征组合。
结合起来
就像一个经验丰富的老侦探(Wide)和一个思维活跃的新侦探(Deep)合作办案,效果更好。
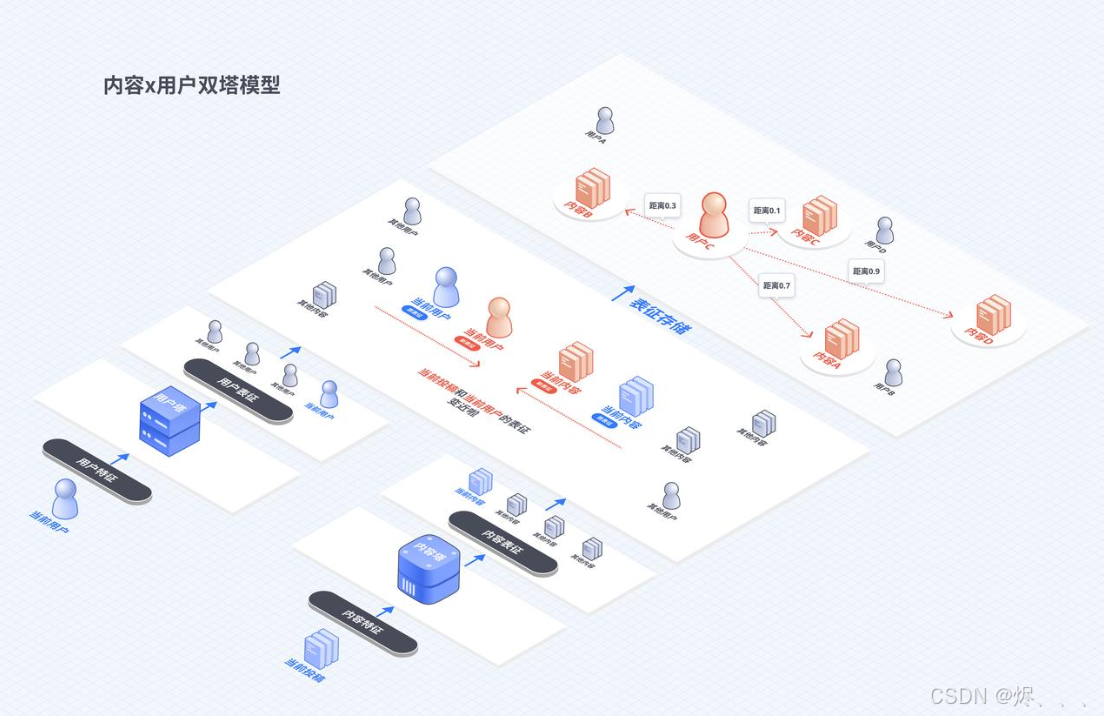
2. 双塔召回模型(高效海选的匹配大师)
“召回”是啥意思?视频库里的视频太多了(几亿、几十亿条),不可能都拿来仔细分析。所以第一步是“召回”,就是先快速地、粗略地从海量视频里捞出一批(比如几千条)你“可能”感兴趣的。然后再对这几千条做更精细的排序。
双塔”怎么工作?
-
给用户和视频打上“数字标签”(向量化):
用户塔: 把你的所有特征(你看过什么、喜欢什么、年龄、性别等等)转换成一串特殊的数字代码(就像你的“数字指纹”)。
内容塔: 把每个视频的特征(是关于猫的还是狗的、是长的还是短的、是搞笑的还是知识类的等等)也转换成一串特殊的数字代码(视频的“数字指纹”)。 -
比较“数字指纹”:
系统把你的“数字指纹”和所有视频的“数字指纹”放到一个想象中的“空间”里去比较。如果你的指纹和某个视频的指纹在这个空间里“靠得很近”,系统就认为你俩“匹配度高”,就会把这个视频捞出来给你。特点:算法不需要“理解”视频内容是啥意思,它只处理这些“数字指纹”之间的数学关系。
总结
推荐算法的厉害之处在于,它把我们人类复杂的喜好、行为(点赞、观看、购买等)都变成了数学问题。它不是真的“懂”你为什么开心,或者为什么喜欢某个明星,而是通过计算大量的用户行为数据,找出数字模式和规律,来预测你下一步可能会喜欢什么。
它就像一个超级厉害的数学家,通过“算”来“猜”你的心思,而且因为有海量数据喂给它学习,它猜得越来越准!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









