







5-1:Recap and preview
概括和预习
Lecture4中我们得到了一个推论,如果|H|=M是有限的,并且数据N足够大,那么由公式(1):
p[BAD D]≤2Mexp(−2ξ2N)
(1)
可知,假设空间的所有假设都遵从PAC准则,能够确保
Ein(h)≈Eout(h)
,因此可以通过一个算法来找到使
Ein(g)≈0
的g来替代f,由PAC保证,也会使得
Eout(g)≈0
。
回顾一下前4章的内容:
1、目标函数f是未知的,第一章介绍了机器学习是通过算法寻找到一个和目标函数f接近的hypothesis,令g就等于该h,用第4章的话来说就是使得在测试数据上的错误率接近为0,即
Eout(g)≈0
。
2、第二章讲述了PLA和pocket算法,目的是使得h在训练数据集上的错误尽量接近为0,也就是
Ein(h)≈0
。
3、第三章讲述了几种机器学习核心的方法,其中之一是利用批量的数据和监督学习 来进行二元分类。
4、第四章中,论述了如果|H|=M是有限的,并且数据N足够大的时候,机器学习是有可能的。即
Ein(g)≈Eout(g)
。
以上的内容将机器学习拆分成立2个内容:
1、我们能否保证
Ein(g)≈Eout(g)
?
2、我们能否使得
Ein(g)
足够小?
针对第四章提出的假设情况总数M,我们分两种情况的讨论结果如下表:
| Small M | Large M |
|---|---|
| 1、是的,由公式(1)可以看出M很小的时候p接近0,两者接近的几率很大 | 1、不是的,由公式(1),M很大的时候, Ein(g) 和 Eout(g) 不接近的几率变得很大 |
| 2、不是的,M很小的时候,选择太少了,那么不能确保选到比较小的 Ein(g) | 2、是的,M很大的时候,有很多选择,能保证选到比较小的 Ein(g) |
由上述表格,我们可以看出,要适当的选择M,如果M趋于无穷呢?算法的表现会特别糟糕,怎么办呢?后面进行解答。
5-2:Effective Number Of Lines
从公式
p[BAD D]≤2Mexp(−2ξ2N)
可以看出,我们得到了选到错误假设g的上限概率,即union bound,但是我们仔细观察发现,这个上限过于宽松了,因为如果M趋于无穷的话,那么概率p也趋向无穷,显然这是不对的,因为一个事件发生的概率不会超过1。那么为什么会导致这种情况发生呢?
当存在两个相似的假设时,那么他们之间重合的数据就非常多,如下图所示:
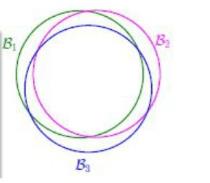
从图中可以看出,B1,B2,B3三个是相似的假设,他们之间重叠的区域特别大,当然,坏数据也是基本重叠的,那么我们应该考虑有效的假设也即有效的线的数量。
我们先从简单的一个输入
x1
看起,你能划分出来多少种线呢(假设在线的方向的一端的记为+1,用符号O表示,反方向记为-1,用符号X表示)?

很显然,
x1
有两种情况,O和X,那么对应的有效的线的数量也就是2。继续考虑输入
(x1,x2)
呢。
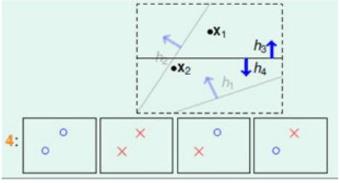
从图中可以看出,我们可以画出4种不同的情形。继续观察3种输入
(x1,x2,x3)
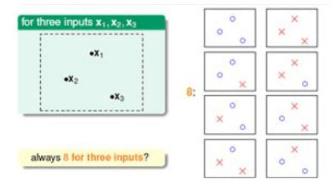
从图中可以看出,确实可以分成8种情况,但是不是一直都满足可以分解成8种情况呢?例如考虑下面的输入情形:
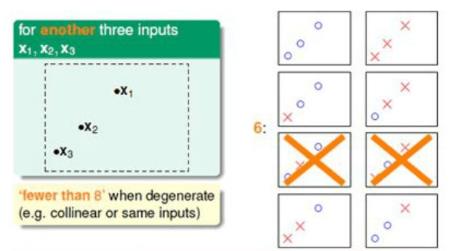
当三个输入被排成一条线的时候,是不可以分成8种情况的,存在2种情况,无论哪一条线都不可能分成图中的两种情况。继续考虑4种输入:

由于是对称的,只给出了对称的一半情形,我们可以发现,对于4个输入,无论怎么排列,都存在2种情形无法被分割出来。依次类推。
我们用一张表格来总结一下上面的结果:
| 输入数N | 有效的分割结果( effective(N) ) |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 8(存在可以被分成8种的排列) |
| 4 | 14< 2N |
于是,我们修改公式为:
p[|Ein(g)−Eout(g)|>ξ]≤2⋅effective(N)⋅exp(−2ξ2N)
只要满足,当
N→∞
时,
effective(N)<<2N
就可以使得概率p很小,事实上这个是成立的。
5-3:Effective Number Of Hypothesis
有效的假设空间数量
上一节介绍了如何将无限多条直线转换为有限的直线数量。用训练样本的分类情况(即X和O的组合)来确定一类假设叫做Dictonomy(二分法),记为H(
x1,x2⋯xn
),即假设空间在
(x1,x2,⋯,xn)
上被分为几种情况。将假设空间和二分之后的空间进行对比,如下表所示:
| 假设空间 | 二分空间 |
|---|---|
| 在空间中的所有线 | [OOOO,OOOX,⋯] |
| 大小:存在无穷条线 | 大小:上限为 2N |
从表中可以看出,二分空间的大小是存在上限的,现在的思想就是用H来代替假设空间即无限大的M,那么如何取代呢?我们仔细观察发现例如输入
(x1,x2,x3)
时,当其分布不同时,会出现不同的分割结果,也就是H依赖于X的分布,为了取消这种影响,我们定义函数:
MH(N)=maxX1…XN∈X|H(X1,…,XN)|
则
MH(N)
是一个比M小的函数,称为成长函数。因为上述表达式是抽象的,接下来的任务便是具体化成长函数。
首先我们从一维PLA即positive rays(正射线)说起,如下图所示:

该图中
h(x)=sign(x−a)
,其中a称为阈值,表明只有在a的右边才存在正样本点,(举个例子:OXXXXXO这种情形就是不允许的)。很容易能得出该分布的成长函数表达式如下:
MH(N)=N+1
,即N个点经过直线切割后最多有N+1种情况。很显然,当
N→∞
时,
N+1<<2N
。
当然,如果这里不考虑方向的问题,那么只需要考虑对称性,即正负情况颠倒
即可,但这样子多加了2中情况,即全正,全负,所以:
MH(N)=2∗(N+1)−2=2N
再考虑一种情况,即positive interval(正的间隔,即中间部分为正),如下图所示:

其成长函数计算为:
MH(N)=C2N+1+1=N22+N2+1
,思想是从上例中N+1条线中,选出2条线作为分割线,但是这样子少考虑了一种情况,即全为X的情况,所以加1。很显然,当
N→∞
时,
N22+N2+1<<2N
。
接着考虑一个二维平面的例子,以凸多边形为例,其内部为正,外部为负,其边界作为假设函数的划分线,如下图所示:

左边蓝色部分表示一种凸的图形,右边蓝色部分表示非凸的图形。如何求取成长函数呢?考虑一种极端的情况,即所有样本点分布在一个圆上,那么我们的目标是寻找一个最大值的分布,由于每个样本点可正可负,即每个点可以取两种情况,当有N个点在圆上时,由排列组合知:
MH(N)=2N
.
5-4:break point
对上一节所说的各种分类情况进行汇总如下表:
| 分布情况 | 成长函数 MH(N) |
|---|---|
| positive rays | MH(N)=N+1 |
| positive rays(无方向) | MH(N)=2N |
| positive interval | MH(N)=N22+N2+1 |
| convex(凸集合) | MH(N)=2N |
事实上,我们更偏爱多项式类的成长函数而不是指数形式的成长函数,因为多项式的成长函数的上限下降的更多。于是我们提出一个新的概念,断点(break point),例如对于二维空间3个点,如下图所示:
我们可以将它分成8个部分,虽然有些分布不能分割这么多种,但是成长函数是取最大值的,但是当4个点的时候,无论什么分布都不可能分成16种,所以2D的break point是4,所以我们称不能满足完全分类的样本数量为断点(break point)。类推,可以得到断点的分布情形如下表:
| 分类 | 断点 |
|---|---|
| 2D感知器 | 4 |
| 正射线 | 2 ( MH(2)=3<22 ) |
| 正的间隔 | 3 ( MH(3)=7<23) |
| convex set | 无断点 |
由此可以得到下面的推论:
1、没有断点的时候,
MH(N)=2N
2、存在断点为k的时候,其成长函数
MH(N)=O(Nk−1)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









