







11-1:Linear Models for Binary classification
线性模型在二元分类中的应用
回顾一下我们 前面所学的三种经典模型:Linear classification(线性分类)、Linear Regression(线性回归)、Logistic Regression(也称软线性分类),我们将这三个模型进行对比,结果如下图所示:
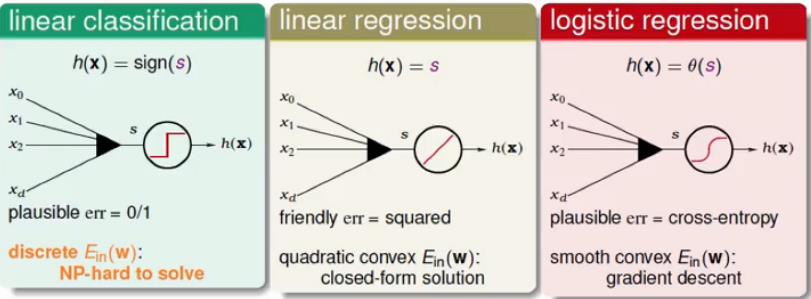
其中s是得分函数,其表达式为
s=wTx
1. 在线性分类中,它采用的误差衡量方式为
err=0/1
,即
Ein(h)=1N∑Nn=1[yn≠h(xn)]
,对于
Ein(w)
的求解,我们会发现这是一个NP-hard问题,很难求解。
2. 在线性回归中,它采用的误差衡量方式平方误差,即
Ein(h)=1N∑Nn=1[yn−h(xn)]2
,我们在Lecture9中介绍过了,这是一个凸函数并且可微,我们可以直接用解析解求出
Ein(w)
的最小值。
3. 对于Logistic回归,上节中讲述了求解
Ein
最小值的方式为迭代的方法,即采用梯度下降的方法。
后面两种情况都能很好的求出
Ein(w)
的最小值,那么我们能不能用这两种方法来求Linear classification的
Ein(w)
呢?
我们先将上面的err衡量方式改变一下:
1. 线性分类中,
err0/1(s,y)=[sign(s)≠y]
,我们将
sign(s)和y
同时乘以y是不影响结果的,等价为:
err0/1(s,y)=[ysign(s)≠+1]
,由于
y∈
{-1,1},可以把y移入sign函数里面,得到最终的表达式为:
err0/1(s,y)=[sign(ys)≠+1]
2. 线性回归作同样的操作,得到下面的转换过程:
errsqr(s,y)=(s−y)2=(ys−1)2
3. Logistic回归可以得到:
errCE(s,y)=ln(1+exp(−ys))
上面作出的改变就是相当于都变成了拥有
ys
项,ys的意义是什么呢?它表示分类的正确率得分,即ys越大,得分越高(个人理解为对于线性分类和Logistic回归是适用的)。

那么我们接下来就以ys为横轴,err为纵轴,来对这三种错误进行图形化描述:

从图中我们可以直观的得出下面的结论:
1.
err0/1
表示:当ys<0的时候,那么对应的错误就为0,即y和s是不相等的,一个为+1,一个为-1,当然ys>0,那么err=0。
2.
errsqr
表示:能够发现当ys=1的时候,err=0,即此时误差为0,但是当ys<<1或者ys>>1的时候,对应的误差都很大,因为
errsqr
是
err0/1
的上限,我们可以得到:小的
errsqr
=>小的
err0/1
3.
errCE
和
err0/1
很接近,相差不大,同样能够得出小的
errCE
=>小的
err0/1
,但是
errCE
不是
err0/1
的上限,因为某些地方
errCE
反而小于
err0/1
,我们对
errCE
进行放缩。
放缩
errCE
得到
errSCE
即:
errSCE=log2(1+exp(−ys))
,然后修改
errCE
的图像对比如下图:

修改完以后,发现
errSCE
就是
err0/1
的上限了。并且在(0,1)点刚好相交。下面我们来对这些误差衡量方式做一些比较:
对于任何的
ys
且
s=wTx
:
err0/1(s,y)≤errSCE(s,y)=1ln2errCE(s,y)
=>
E0/1in(w)≤ESCEin(w)=1ln2ECEin(w)
=>
E0/1out(w)≤ESCEout(w)=1ln2ECEout(w)
由VC限制err 0/1理论,我们可以得到:
E0/1out(w)≤E0/1in(w)+Ω0/1
≤1ln2ECEin(w)+Ω0/1
同样,VC对于CE在
Eout
上的限制:
E0/1out(w)≤1ln2ECEout(w)
≤1ln2ECEin(w)+1ln2ΩCE
通过上面的推导,我们就能得到下面的结论:
小的ECEin(w)=>小的E0/1out(w)
所以上面得到就是说
1ln2ECEin(w)和errSQR
都是
err0/1
的上界,也就是说明了线性回归和Logistic回归是可以用来做线性分类的。下面给出三种模型的优缺点对比:

实际中经常用Linear Regression来做分类问题,更多的是先用Linear Regression来得到一个初始解 w0 ,将这个 w0 应用在Logistic/PLA/pocket上面使得算法收敛速度更快,而Logistic回归通常取代pocket算法。
11-2:Stochastic Gradient Descent
随机梯度下降算法
回归一下PLA算法,我们进行更新时只需要找出一个错误的点就行纠正就可以了,时间复杂度为O(1),而在上一节介绍的Logistic Regression中的梯度算法,其计算微分的表达式如下:
∇Ein(w)=1N∑Nn=1θ(−ynwTxn)(−ynxn)
从求和符号就能看出来,计算的复杂度为O(N),那么问题来了,我们能不能和PLA一样,每轮计算复杂度只需要O(1)呢?
从
∇Ein(w)
的表达式我们可以看出,它是对N个点进行运算再取平均,那么我们是不是可以去掉求和符号,即随机取一个点进行运算,将这一个点的运算结果作为
∇Ein(w)
的结果,那么这种方法就是随机梯度下降算法。
对比一下梯度下降和随机梯度下降:
梯度下降:
wt+1←wt−η⋅1N∑Nn=1θ(−ynwTxn)(−ynxn)
随机梯度下降:
wt+1←wt−η⋅θ(−ynwTxn)(−ynxn)=wt+η⋅θ(−ynwTxn)(ynxn)
- 随机梯度的思想就是用随机梯度代替真正的梯度下降:
- 随机梯度下降从单次迭代结果来看确实会存在对真实的梯度方向有影响,但是经过足够的迭代次数之后,
平均的真实梯度≈随机梯度
,即随机梯度一样能够到达山谷,找到最小值。随机梯度的特点如下:
- 简单计算(只需要一个点),尤其适用于大数据或者在线学习
- 相比原来的梯度下降,随机梯度下降不稳定
将随机梯度和我们刚开始讨论的PLA做一下对比:

我们发现,PLA和SGD之间的关系还是很明显的:
1. SGD被称为软的PLA,因为PLA只有在找到错误点的时候才会进行修正,而SGD每轮迭代都会进行或多或少的修正。
2. 当
η=1
且
wTxn
足够大的时候,SGD也就相当于PLA了。
最后,我们要考虑两件事情:
- SGD什么时候停止?理论上是当迭代次数t足够大的时候停止。
- η 取值?实际应用中取 η=0.1
11-3:Multiclass via logistic regression
利用logistic回归进行多分类
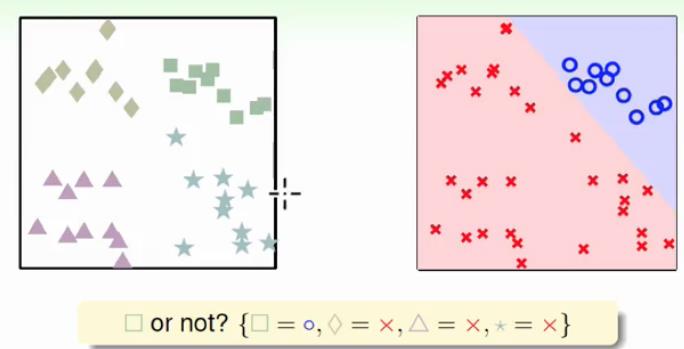
例如我们有一个四分类问题,如图存在四类分别为正方形、菱形、三角形、五角星:

我们如何将其分类正确?一种思想是一次只分类一种情况,将四分类问题看做为二分类问题,即 :
我们将正方形看做O,其他的全部标记为X,那么我们得到上图的结果,依次选取4类分别作为O,得到最终的分类结果如下:
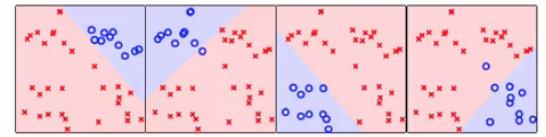
貌似我们已经完美的做好了四分类问题,其实没有,比如我们取一个点,它处于分类结果的交集中,比如它又在正方形类里,又在菱形类里,我们怎么将它分类呢,按照上面的分类方法好像分不出来,如下图所示:

对于这种情况,我们如何把这个点归类呢?于是我们应该想到了之前的Logistic进行软分类,也就是说不是判断一个点属于哪一类,而是判断这个点属于这个类的概率是多少,也就是目标分布
p(y|x)
,举个例子来说,还是以上面的点为例子,它处于两个分类的交集中,但是处于正方形类得到的p=0.7,处于菱形的概率为0.3,毫无疑问我们肯定会认定这个点属于正方形类。用软分类作出的分类边界如下:

从上图我们就能得出,给定任何一个点我们都能进行分类,也就是完美的完成了四分类的任务。
这种方法被称为OVA分解(One-Versus-All Decompostion),通俗的说就是一个人打其他所有人。其算法流程图如下:

对流程图作详细解释(用上面四分类例子):
对于四分类,那么y就是集合{1,2,3,4},即四类,我们遍历所有数据集,每次取其中一类做标记,例如取k=1类,那么k=1的所有数据都会被标记为+1,其他类都会被标记为-1,这也就是
y′n=2[yn=k]−1
结果,标记好数据之后,用Logistic regression进行软分类,得到每一类的权重w,得到所有的w后,得到新数据点的时候,计算这个点属于各个类别的概率,然后取最大值就可以了。
OVA的优缺点:
1. 优点:有效率,可以使用Logistic回归来解决分类
2. 缺点:当分类数目k太大的时候,数据不平衡就会特别明显,分类的效果就会很差
但是总体上,OVA是一个你值得拥有的算法。
11-4:Multiclass via Binary classification
用二元分类实现多元分类
针对上节OVA算法的缺点,即K太大的时候,分类效果不好,通俗的说,是因为打架的时候,一个人肯定干不过其他所有人啊,那么换个角度,在这群人中只选出2个人进行打架,一个为O,一个为X,其他人观战,那打架的情况就不一定啦。
还是举上面的那个例子,分类实例如下:
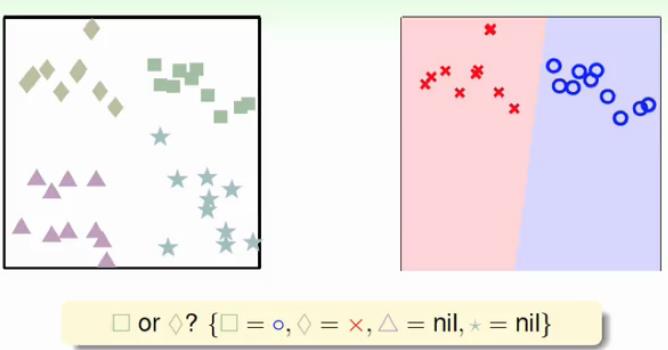
上图中我们只选择了正方形和菱形进行二分类,另外的三角形和五角星属于观战状态,那么我们可以得到一种分类情形如上面右图所示。这样子要分多少次呢?相当于4个人中,每次选2个人出来打架,由组合知识,
C24=6
嘛,按照这种分类,得到所有的分类情形如下:

得到所有的分类结果以后,也就是各个权重,那么给你一个新的数据点,我们如何判定它属于哪一类?计数一下这个点属于各个类的情况,比如得到计数结果为属于{1,2,3,4}类分别为{3,2,1,0},那冠军就是k=1类了,所有这个点属于k=1。
以上就是另外一种多元分类算法OVO分解(One-Versus-One Decompotision),即一对一,其算法流程图如下:

具体的流程和OVA相似,就不细介绍了。这种方法的优缺点如下:
1. 优点:有效率(因为每次只用对比二元分类)、稳定、可以用二元分类来解决
2. 缺点:空间复杂度提高了,时间复杂度变为
C2k
,即
O(K2)
,预测的速度也变慢了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









