






文章汉化系列目录
文章目录
摘要
我们提出了DenseAV,这是一种新颖的双编码器定位架构,能够仅通过观看视频来学习高分辨率、语义丰富并且音视频对齐的特征。我们展示了DenseAV可以在没有明确定位监督的情况下,发现单词的“含义”和声音的“位置”。此外,它能够在没有监督的情况下自动发现并区分这两类关联。我们证明了DenseAV的定位能力源自一种新的多头特征聚合操作符,该操作符直接比较密集的图像和音频表示,用于对比学习。相比之下,许多其他系统学习的是“全局”音频和视频表示,无法定位单词和声音。最后,我们贡献了两个新的数据集,用于通过语音和声音提示的语义分割来改进AV表示的评估。在这些数据集和其他数据集上,我们展示了DenseAV在语音和声音提示的语义分割任务中大幅超越了现有技术水平。DenseAV在跨模态检索任务中也超越了当前的最先进模型ImageBind,并且参数量少于一半。项目页面:https://aka.ms/denseav
1.引言
将音频与视频关联是人类感知的基本方面之一。随着婴儿的成长,声音的同步和对应关系使得多模态关联成为可能——例如,将声音与面孔对应,或者将“哞声”与牛对应【50】。之后,随着他们语言能力的发展,他们会将口语与其代表的物体关联起来【10, 45】。令人惊讶的是,这些关联能力(包括语音识别、声音事件识别和视觉对象识别)几乎是在没有直接监督的情况下发展起来的。本研究的目标是通过学习高分辨率、语义丰富的音视频(AV)对齐表示来构建一个具备这种能力的模型。具备这些特性的特征可以用于在没有定位监督或语言文本表示知识的情况下,发现模态之间的细粒度对应关系。
举个例子,考虑图1所示图像的语音描述和伴随的声音。我们希望以高分辨率“定位”语音和声音。例如,如果视觉信号中存在狗的图像,那么音频信号中的“狗”这个词和狗叫声都应该与视觉信号中狗的像素关联起来。我们追求高质量的局部特征表示,其中特征之间的简单内积能够展示这种行为,而有趣的是,现有文献中的流行方法并没有表现出这一点。
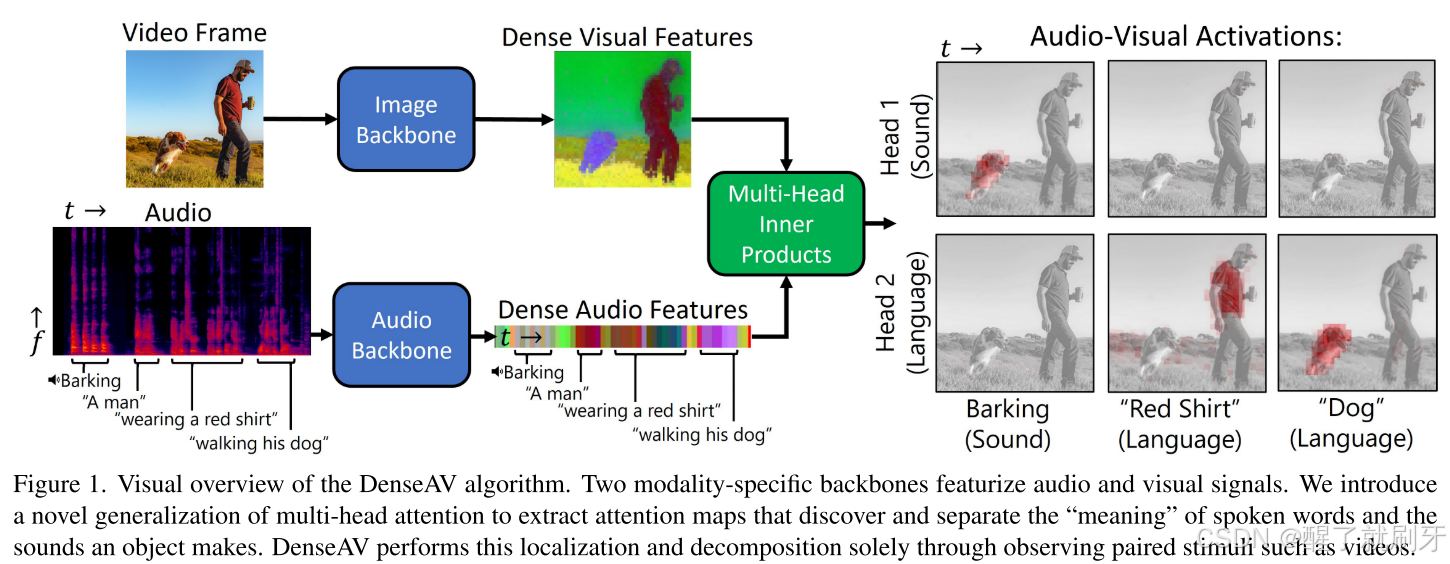
图1. DenseAV算法的视觉概览。两个模态特定的主干网络对音频和视觉信号进行特征提取。我们引入了一种多头注意力机制的广义化版本,以提取注意力图,从而发现并分离口语单词的“含义”和物体发出的声音。DenseAV仅通过观察诸如视频等成对的刺激来实现这种定位和分解。
为实现这一目标,我们做了三项创新。首先,我们引入了DenseAV,这是一种双编码器架构,它在音频和视觉特征上计算出一个稠密的相似度体积,然后将该体积聚合为一个相似度分数。如果我们观察当某个单词被说出时这个相似度体积的某一切片,如图1所示,我们可以可视化单词或声音与图像像素之间的音视频(AV)激活强度。我们引入的新颖之处在于使用多头机制对这种稠密相似度进行广义化,类似于多头注意力机制。这种广义化允许每个头部专注于视觉和音频模态之间的特定类型的耦合。有趣的是,我们发现当给DenseAV两个头并在包含语言和声音的数据集上进行训练时,这些头能够在仅使用跨模态监督的情况下,自然地学习区分语言和更一般的声音。例如,如图1所示,头1专注于哪个物体发出声音,比如狗的叫声,而头2则只专注于单词的含义。
其次,我们展示了在对比学习中,使用“聚合函数”来创建音频片段与视频帧之间的相似度分数的重要性。传统的选择,例如使用全局表示(如类别标记【5, 13, 49】)或池化特征【18, 58】之间的内积,无法促进稠密局部特征的音视频对齐。因此,许多在跨模态检索中表现优异的流行音视频主干网络,无法通过其局部特征直接关联对象和声音。这限制了它们在下游任务(如语义分割、声音定位或无监督的语言学习与发现)中的应用能力。
第三,我们引入了两个语义分割数据集,用于评估通过音视频(AV)表示进行的语音和(非语音)声音的视觉定位。这些数据集基于ADE20K数据集【59】提供的高质量分割掩码构建,并在二元掩码预测任务中测量平均精度(mAP)和平均交并比(mIoU)。相比之前用于测量视觉定位的评估方法(如概念计数指标【23】和“指点游戏”【2, 14, 38】),这些方法仅检查热图的峰值是否位于目标框或段内,我们的评估更简单且更加全面。此外,我们的评估避免了使用不稳定的WordNet本体【34】、聚类、Wu和Palmer距离【55】、阈值选择及其他复杂因素。
总结起来,我们的主要贡献如下:
- 我们提出了DenseAV,这是一种新颖的自监督架构,能够学习高分辨率的音视频(AV)对应关系。
- 我们引入了一种基于局部特征的图像相似度函数,与常见策略(如平均池化或CLS标记)相比,这显著提升了网络的零样本定位能力。
- 我们引入了新的数据集,用于评估由语音和声音提示的语义分割任务。实验表明,DenseAV在这些任务以及跨模态检索中明显优于当前的最先进方法。
- 我们发现,多头架构自然地将音视频对应关系解耦为声音和语言成分,并且仅通过对比监督实现了这一点。
2.相关工作
音视频(AV)、文本视觉以及更广泛的多模态模型最近迅速流行起来【60】。从广义上讲,DenseAV是一种音视频对比学习架构,这类方法通过对齐配对信号并推开负信号来学习AV表示【11, 27】。在这一类模型中,有些在声音定位【2, 7, 42】或捕捉语言语义【23, 43】方面表现突出。许多这类模型通过全局表示(如池化的深度特征或类别标记)之间的内积来比较AV信号【18, 35, 53】,或使用类别标记【17, 32, 42, 43, 49】。尤其是,ImageBind因其在各种任务和数据集上表现优异,以及统一的类别标记对比架构而受到关注。在这项工作中,我们展示了许多此类架构虽然在“全局”跨模态检索上表现出色,但在其局部特征中并没有表现出强大的定位能力。这限制了它们在处理新领域的声音、没有文本表示的声音以及低资源语言中的适用性。我们不同于这些方法的是,直接监督局部特征标记。特别是,我们基于之前的工作【2, 23】,这些工作显示最大池化可以改善定位能力,并引入了一种新的多头聚合操作符,该操作符使用类似于自注意力【52】的机制来推广之前的损失函数。
另一类方法通过单模态和多模态聚类来发现信号中的结构。早期的音频聚类工作【41】在无监督的情况下发现了有意义的语音片段。类似的视觉分析方法也发现了视觉对象【4, 8, 20, 28】。最近的一些工作将这些思想应用于音视频(AV)领域【1, 21】,但它们并不关注提取高分辨率的AV表示。最后,一些研究探讨了生成式音视频学习。The Sound of Pixels【57】通过源分离损失生成特定对象的声音。更近的方法则使用生成对抗网络(GAN)【30, 31】和扩散模型【9, 17, 33】生成视频中的音频,或反向生成音频中的视频。本文的重点是改进对比学习模型的局部表示,因为这些方法相对具有较好的扩展性、简单性,并且能够学习高质量的表示。
3.方法
从总体上看,DenseAV试图通过稠密的音视频(AV)表示来判断给定的音频和视觉信号何时属于同一个场景。为了稳健地完成这一任务,DenseAV必须学习如何从视觉信号预测音频内容,反之亦然。这使得DenseAV能够学习到模态特定的稠密特征,捕捉不同模态之间共享的互信息【51】。一旦学会了这些特征,我们可以直接查询这些信息丰富的特征来执行如图1所示的语音和声音提示的语义分割任务。
更具体地说,DenseAV由两个模态特定的深度特征提取器构建。这些主干网络在一个音频片段上生成时间变化的音频特征,并在单个随机选取的帧上生成空间变化的视频特征。我们的损失函数基于这样一个直观假设:如果两个信号之间有多种强耦合或共享对象,则它们是相似的。更正式地说,我们通过小心地聚合稠密特征之间的成对内积,来为一对音频和视频信号形成一个标量相似度。我们使用了InfoNCE【36】对比损失函数,鼓励“正”信号对之间的相似性,并减少通过批内随机打乱形成的“负”信号对之间的相似性。图3以图形方式描述了这个损失函数,随后的章节详细介绍了我们架构的每个组成部分。
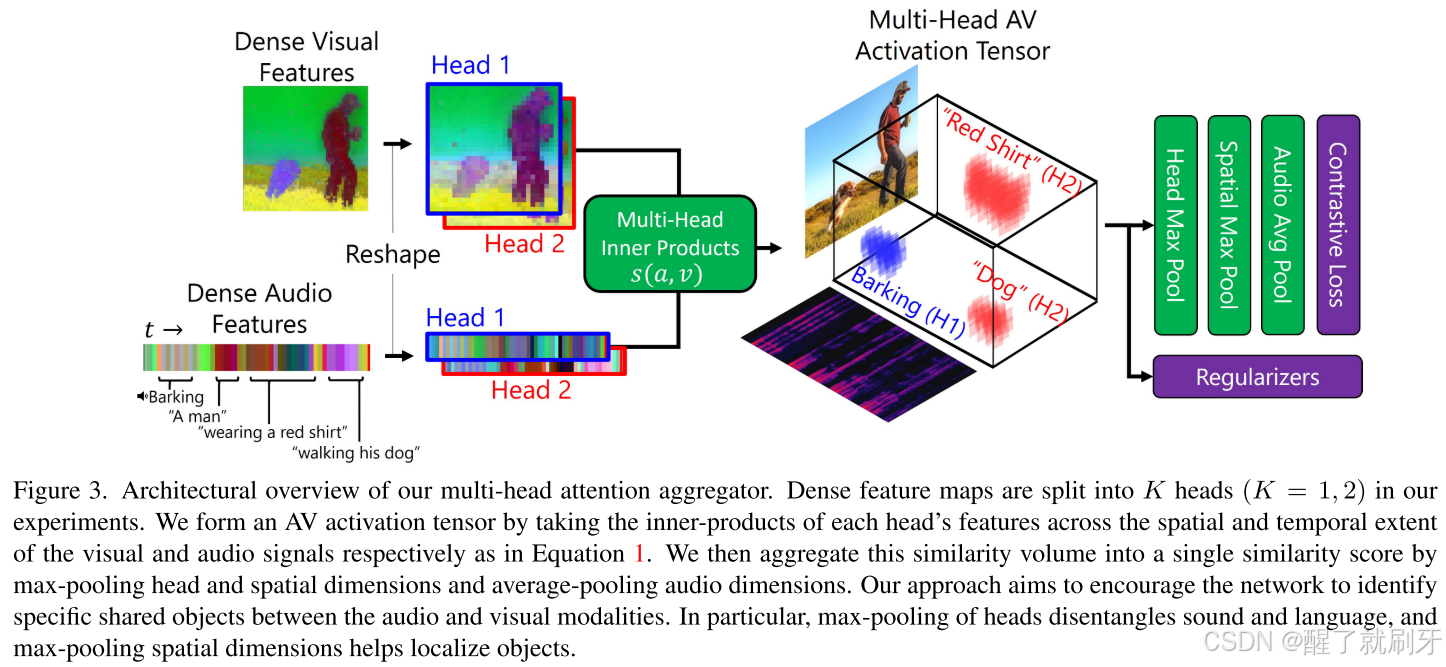
图3. 多头注意力聚合器的架构概览。在我们的实验中,稠密特征图被分成K个头(K = 1, 2)。我们通过对每个头的特征在视觉和音频信号的空间和时间范围内进行内积来形成一个音视频(AV)激活张量,如公式1所示。然后,我们通过对头部和空间维度进行最大池化、对音频维度进行平均池化,将这个相似度体积聚合成一个相似度分数。我们的目标是鼓励网络识别音频和视觉模态之间的特定共享对象。特别地,对头部的最大池化能够将声音和语言进行解耦,而对空间维度的最大池化有助于定位对象。
3.1. 多头相似度聚合
DenseAV的关键架构区别在于其损失函数,该损失函数直接监督视觉和音频特征提取器的“局部”标记。这与其他工作【5, 17, 19, 39, 46, 49】有显著不同,后者在对比损失之前,将模态特定的信息池化成“全局”表示。与这些先前的工作不同,我们的损失函数聚合了局部标记之间的全部成对相似度,形成音频和视觉信号对的总体相似度度量。图2显示,这种架构选择使DenseAV的局部特征能够跨模态对齐,而其他方法如平均池化、类别标记和SimPool【44】则无法实现这种对齐。
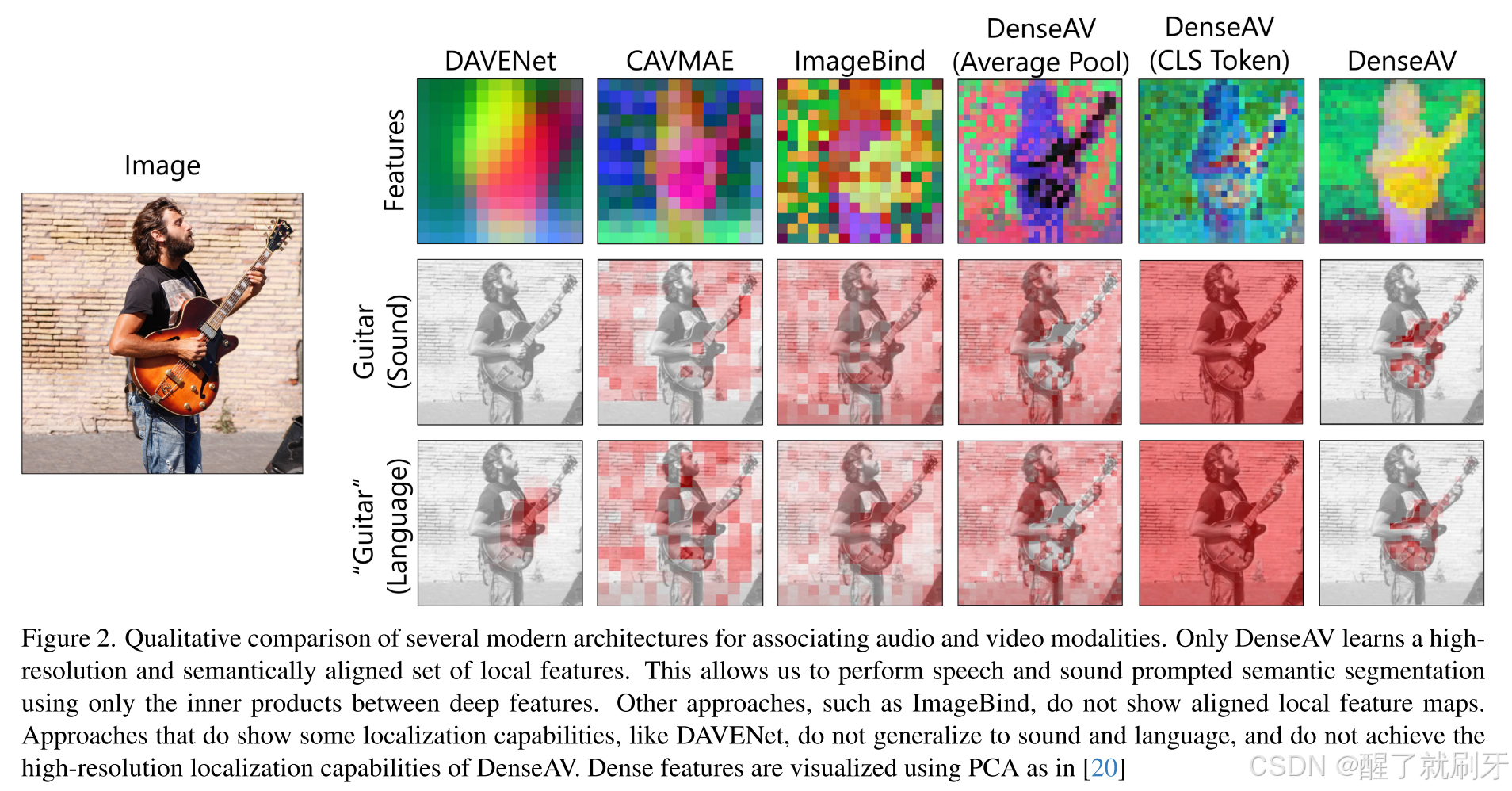
图2. 现代架构中关联音频和视频模态的定性比较。只有DenseAV能够学习到高分辨率且语义对齐的局部特征集。这使我们可以仅通过深度特征之间的内积来执行语音和声音提示的语义分割。其他方法,例如ImageBind,没有显示对齐的局部特征图。而一些展示出一定定位能力的方法,如DAVENet,无法泛化到声音和语言,也无法达到DenseAV的高分辨率定位能力。局部特征使用PCA进行可视化,参考【20】。
我们首先非正式地描述我们的损失函数,随后在下一段中更精确地定义它。我们的损失函数通过计算每对视觉和音频特征的(未归一化的)内积,生成一个“内积体积”。这个体积表示音频信号的每个部分与视觉信号的每个部分之间的耦合强度。我们的目标是找到许多在正对音频和视觉信号之间的大耦合点,理想情况下,这些耦合应该将视觉对象与其在音频信号中的参照关联起来。相反,我们不希望在负对信号之间找到耦合点。为了计算一对信号的整体耦合强度,我们将这个成对相似度体积聚合成一个单一的数值。聚合这个体积的方法有很多种,范围从“柔和”的平均池化到“硬”的最大池化不等。平均池化会生成稠密梯度,有助于提升收敛速度和稳定性;然而,最大池化允许网络专注于最佳的耦合点,而不考虑物体的大小或声音的持续时间。我们的聚合函数结合了平均池化和最大池化的优点,通过在视觉维度上进行最大池化,并在音频维度上进行平均池化【23】。直观地讲,这种方法在音频信号上平均了最强的图像耦合,这既允许小的视觉对象产生大的影响,又为信号的多个区域提供强有力的训练梯度。最后,我们从多头自注意力机制【52】中获得灵感,将这一操作推广到多个“头”,并在对视觉和音频维度进行池化之前对每个头进行最大池化。这允许DenseAV发现跨模态关联对象的多种“方式”。
更为正式地定义,相似度
S
(
a
,
v
)
∈
R
S(a, v) \in \mathbb{R}
S(a,v)∈R 表示音频特征张量
a
∈
R
C
×
K
×
F
×
T
a \in \mathbb{R}^{C \times K \times F \times T}
a∈RC×K×F×T(维度为通道数
C
×
K
×
F
×
T
C \times K \times F \times T
C×K×F×T)与视觉特征张量
v
∈
R
C
×
K
×
H
×
W
v \in \mathbb{R}^{C \times K \times H \times W}
v∈RC×K×H×W(维度为
C
×
K
×
H
×
W
C \times K \times H \times W
C×K×H×W)之间的相似度。为了定义这个标量相似度分数,首先我们创建一个局部相似度体积
s
(
a
,
v
)
∈
R
K
×
F
×
T
×
H
×
W
s(a, v) \in \mathbb{R}^{K \times F \times T \times H \times W}
s(a,v)∈RK×F×T×H×W。为了简化,我们考虑单个图像和音频片段之间的聚合相似度,但也可以很容易地将其推广到对视频帧进行最大池化。我们定义的全成对相似度体积为:
s ( a , v ) ∈ R K × F × T × H × W = ∑ c = 1 C a [ c , k , f , t ] ⋅ v [ c , k , h , w ] s(a,v) \in \mathbb{R}^{K \times F \times T \times H \times W} = \sum_{c=1}^{C} a[c,k,f,t] \cdot v[c,k,h,w] s(a,v)∈RK×F×T×H×W=c=1∑Ca[c,k,f,t]⋅v[c,k,h,w]
其中, a [ c , k , f , t ] a[c, k, f, t] a[c,k,f,t] 表示在位置 [ c , k , f , t ] [c, k, f, t] [c,k,f,t] 处的音频特征值, ⋅ \cdot ⋅ 表示标量乘法。
然后,我们将这个相似度体积聚合成一个单一分数 S ( a , v ) ∈ R S(a, v) \in \mathbb{R} S(a,v)∈R:
S ( a , v ) = 1 F ⋅ T ∑ f = 1 F ∑ t = 1 T max k , h , w ( s ( a , v ) [ k , f , t , h , w ] ) \mathcal{S}(a, v) = \frac{1}{F \cdot T} \sum_{f=1}^{F} \sum_{t=1}^{T} \max_{k,h,w} \left ( s(a,v)[k,f,t,h,w] \right ) S(a,v)=F⋅T1f=1∑Ft=1∑Tk,h,wmax(s(a,v)[k,f,t,h,w])
我们注意到,这个操作可以看作是对 MISA 损失【23】的多头广义化,同时也是对 MIL 损失【2】在多头和多时间维度上的广义化。
3.2 损失
我们可以使用公式 2 中定义的音频和视觉信号之间的相似度来构建一个对比损失。我们遵循最近的研究【15, 17, 54】,使用温度加权的 InfoNCE【36】来鼓励正对信号之间的相似性,并减少负对信号之间的相似性。在 DenseAV 中,我们通过将训练数据批次中的音频和视觉组件分割开,形成 B B B 个正对。通过将一个信号与批次中的所有其他信号进行比较,形成 B 2 − B B^2 - B B2−B 个负对。
更正式地,令 ( a b , v b ) 1 B (a_b, v_b)^B_1 (ab,vb)1B 表示 B B B 对音频和视觉信号。我们 InfoNCE 损失的视觉检索项如下:
L A → V = 1 2 B ∑ i = 1 B ( log exp ( γ S ( a b , v b ) ) ∑ b ′ = 1 B exp ( γ S ( a b , v b ′ ) ) ) ( 3 ) \mathcal{L}_{A \to V} = \frac{1}{2B} \sum_{i=1}^{B} \left( \log \frac{\exp{\left( \gamma \mathcal{S}(a_b, v_b) \right)}}{\sum_{b'=1}^{B} \exp{\left( \gamma \mathcal{S}(a_b, v_{b'}) \right)}} \right) \quad (3) LA→V=2B1i=1∑B(log∑b′=1Bexp(γS(ab,vb′))exp(γS(ab,vb)))(3)
其中, γ ∈ R + \gamma \in \mathbb{R}^{+} γ∈R+ 是一个可训练的逆温度参数。我们通过添加类似的音频检索项 L V → A L_{V \to A} LV→A 来对该损失函数进行对称化,音频检索项在分母中遍历负音频信号。
3.3 音频和视觉特征提取器
DenseAV 的核心是两个模态特定的主干网络。我们使用了 DINO 视觉 Transformer【5】,并加载了经过 ImageNet 预训练的权重(无标签),来提供一个强大但完全无监督的视觉主干。与使用 CLIP【46】作为主干的其他方法不同,DINO 不需要配对的文本说明,仅从无标签的图像中学习。实际上,我们发现 DINO 的表现优于 CLIP,因为其局部标记处理得更好【12】。这一效果在附录中有进一步探讨。我们在 DINO 上附加了一个跨通道的层归一化操作【3】以及一个 1 × 1 1 \times 1 1×1 的卷积层。层归一化和 1 × 1 1 \times 1 1×1 卷积确保架构不会从饱和的损失函数开始训练。
我们使用 HuBERT 音频 Transformer【25】作为 DenseAV 的音频主干网络。HuBERT 处理波形,并在 LibriSpeech【40】数据集上使用自监督进行训练。HuBERT 为每个频率输出一个特征,所对应的频率在第 3 节中定义为 F = 1 F = 1 F=1。尽管 HuBERT 只在语音数据上进行了训练,其音频特征也可以微调用于处理更广泛的声音,就像视觉主干可以为新数据集进行微调一样【56】。
在视觉分支中,我们在音频分支上也添加了一个按通道的 LayerNorm 块和两个 3 × 3 3 \times 3 3×3 的卷积层。这些层有助于网络避免饱和并加速收敛。此外,这两个卷积层有助于模型聚合信息,从而降低了我们损失函数中成对特征比较的成本。在后续部分中,我们将这些添加的层称为“对齐器”(aligners)。
3.4 正则化器
解耦正则项 L D i s L_{Dis} LDis: 我们添加了一个小的正则项,以鼓励公式 (1) 中的每个头部专注于学习独立类型的音视频关联。有趣的是,我们发现双头模型可以自然地学会用一个头区分单词的含义,另一个头捕捉物体发出的声音。为了进一步鼓励这种无监督的概念发现,当多个注意力头同时激活时,我们对网络进行惩罚。更具体地说,令 ( a b , v b ) 1 B (a_b, v_b)^B_1 (ab,vb)1B 是 B B B 对配对的音频和视觉信号。我们的双头解耦损失函数为:
L D i s = Mean ( ∣ s ( a b , v b ) [ 1 ] ∘ s ( a b , v b ) [ 2 ] ∣ ) ( 4 ) \mathcal{L}_{Dis} = \text{Mean}( |s(a_b, v_b)[1] \circ s(a_b, v_b)[2]| ) \quad (4) LDis=Mean(∣s(ab,vb)[1]∘s(ab,vb)[2]∣)(4)
其中, ∘ \circ ∘ 表示逐元素乘法, ∣ ⋅ ∣ | \cdot | ∣⋅∣ 是逐元素绝对值函数。 [ k ] [k] [k] 模仿了 PyTorch 的切片符号,表示选择仅与第 k k k 个注意力头相关的激活。直观上,这个损失鼓励一个头在另一个头激活时保持沉默,这是 L 2 L_2 L2 正则项【24】的一种“交叉项”广义化,旨在鼓励激活收缩。当 K > 2 K > 2 K>2 时,我们对每个头组合的贡献进行平均。我们在表 3 中消融了这一点以及我们最大池化头部的决策。
稳定性正则项 L S t a b i l i t y L_{Stability} LStability: 最后,我们还添加了其他几个小的正则项,以鼓励稳定的收敛。在附录中,我们详细介绍了这些正则项的具体作用。简要地说,这些正则项包括诸如时间上的总变化【48】平滑性以及非负压力等标准正则化项,目的是鼓励网络专注于相似性而非不相似性。此外,我们还添加了一个正则项,防止校准温度 γ \gamma γ 漂移得太快,以及一个在静默和噪声期间抑制激活的正则项。在附录中,我们展示了每个正则项单独作用时对最终指标的影响不大,但结合使用时可以防止训练中的崩溃。
将这些损失项组合成一个单一的损失函数如下:
L = L A → V + L V → A + λ D i s L D i s + L S t a b i l i t y ( 5 ) \mathcal{L} = \mathcal{L}_{A \to V} + \mathcal{L}_{V \to A} + \lambda_{Dis}\mathcal{L}_{Dis} + \mathcal{L}_{Stability} \quad (5) L=LA→V+LV→A+λDisLDis+LStability(5)
在我们的实验中,我们使用了 λ D i s = 0.05 \lambda_{Dis} = 0.05 λDis=0.05,并在附录中提供了详细说明关于稳定性正则项 L S t a b i l i t y L_{Stability} LStability 的内容。
3.5. 训练
在我们的实验中,我们在AudioSet【16】数据集上训练DenseAV和相关的基线模型,以进行声音提示的语义分割和AudioSet检索。对于语音提示的语义分割、PlacesAudio检索以及表4中的消融研究,我们在PlacesAudio【22】数据集上进行训练。在表3中的解耦实验和图1与图2的特征可视化中,我们在AudioSet和PlacesAudio上同时进行训练,以便DenseAV能够既熟悉PlacesAudio中的主要音频信号——语言,又熟悉AudioSet中的更广泛的声音。在这些实验中,我们从这两个语料库中随机采样训练数据,以确保每个批次的数据在AudioSet和PlacesAudio之间均匀分配。

表4. 不同特征聚合策略的定量消融研究。虽然平均池化和使用学习到的CLS标记来聚合特征的常见做法对检索性能几乎没有影响,但它们大幅降低了在语音提示的语义分割任务中的表现。
Aligner的预热:我们发现,首先在保持预训练的DINO和HuBERT主干不变的情况下训练额外的aligner(卷积和层归一化)3000步,可以显著提高训练的稳定性。这使得aligner能够在修改主干的敏感权重之前先适应这些强大的主干模型。
数据增强:我们使用了随机尺寸裁剪、颜色抖动、随机翻转和随机灰度处理作为图像增强方法。我们从视频中随机抽取一个帧输入视觉分支。音频片段被转换为单通道格式,并通过修剪或填充静音以生成统一的10秒片段。音频片段根据使用的主干模型的要求进行重新采样。对于HuBERT,我们将音频重新采样为16kHz。我们在8个V100 GPU上训练,有效批量大小为80,并在计算损失之前在所有GPU上聚合负样本,以确保高效的并行化。我们在补充材料中提供了更多的训练信息和超参数。
完整训练:在aligner预热之后,我们使用相同的损失函数、批量大小和训练逻辑,再训练完整模型800,000步。我们训练所有aligner的权重,并微调所有HuBERT音频主干的权重。我们使用低秩适应(LoRA)【26】来微调DINO视觉主干注意力块中的“Q”、“K”和“V”层。这使我们能够有效地适应DINO,并稳定训练过程,因为很容易破坏经过精细训练的DINO权重。我们使用LoRA的秩为8。
4.实验
为了评估音视频(AV)表示的质量,我们进行了多种分析,包括比较激活可视化、语音和声音提示的语义分割的定量测量,以及跨模态检索。此外,我们还对DenseAV能够在没有监督的情况下区分单词的含义(语言)和物体的声音(声音)这一现象进行了量化评估。
为了充分衡量表示的音视频(AV)对齐质量,我们发现有必要引入两个评估数据集,用于测量语音和声音提示的语义分割性能。我们的两个数据集引入了与配对图像和从ADE20K派生的分割掩码相匹配的语音和声音提示对。我们创建这些数据集是因为之前的研究【23】并未公开其数据集或评估代码。然而,对于跨模态检索实验,我们采用了文献中的实验设置。
我们与多种现有技术进行了比较,包括流行的最先进的多模态检索网络ImageBind【17】。我们还与CAVMAE【18】进行比较,CAVMAE是专门为AudioSet检索训练的领先多模态主干网络,及DAVENet【23】,该网络旨在定位单词的含义。此外,我们还包含了另外两个基线模型【21, 22】,它们在PlacesAudio上报告了跨模态检索指标。最后,我们将我们的多头聚合策略与常见的“全局”检索方法进行比较,比如类别标记之间的内积、平均池化标记和SimPooled【44】标记。值得注意的是,SimPool在与其他14种池化方法的比较中实现了最先进的定位结果。然而,我们的多头对齐策略在定位结果上优于任何这些“全局”方法。
4.1. 特征图的定性比较
在图2中的第一个实验展示了DenseAV的特征与文献中其他方法之间的显著质量差异。DenseAV是唯一能够生成语义丰富且展示跨模态对齐(语音和声音)的局部标记的主干网络。虽然CAVMAE和ImageBind都表现出高质量的检索性能,但它们的局部标记未能显示出高质量的对齐。因此,DenseAV在关联和定位声音与语言方面显著优于其他主干网络。DAVENet虽然显示了语言与视觉对象之间的粗略对应关系,但无法将声音与视觉对象关联,也无法达到DenseAV的高分辨率特征图效果。
此外,图1的右半部分展示了DenseAV无需标签监督就能够自然地发现并区分单词语义与物体发出的声音。在补充材料中,我们提供了所有主干网络在大量单词和声音上的额外可视化结果。
4.2. 语音提示的图像分割
数据集:我们引入了一个基于ADE20K数据集的语音提示分割数据集,该数据集以其全面的本体论和像素级精确的标注而著称【59】。从该数据集中,我们通过为每个ADE20K中的对象类别最多采样10张图像(排除所选类别小于5%像素的图像)来挑选评估子集。我们仅考虑至少有2张符合小物体标准的类别和图像。对于每个类别和图像,我们通过选择该类别的语义分割掩码生成了二元目标掩码。最终结果为3030对图像-对象对,涵盖了ADE20K的478个类别。
我们通过语音生成与每个类别对应的语音信号,语音内容为“A picture of a(n) [object]”,其中[object]是ADE20K类别的名称。我们使用微软的神经文本转语音服务【47】生成清晰、受控且一致的音频提示。该服务还提供了准确的“[object]”发音时间,并确保每个类别的测量是均衡的。我们手动核对了语音的语法,以确保类名的单复数以及a/an的使用正确。为了保证可重复性,我们发布了图像、掩码和音频提示。
评估指标:我们根据模型的语音提示激活与视觉对象类别的真实掩码对齐的程度进行评估。我们使用二元平均精度(AP)和交并比(IoU)指标来量化模型激活与ADE20K数据集中的二元标签掩码的匹配程度。为了计算所有考虑对象类别的总体得分,我们通过对所有对象类别的AP得分取平均,计算出平均平均精度(mAP)和平均交并比(mIoU)。
mAP非常适合用于评估特征相似性,因为它不受相似性分数的单调变换影响。这消除了对任意阈值设定和校准的需求。这个特性尤为重要,因为许多网络的内积并不以零为中心,最优的阈值策略可能并不简单,且取决于网络和对象类别。平均精度(mAP)避免了这些混杂因素,确保了各方法之间的公平比较。
不幸的是,与mAP不同,mIoU度量则需要选择一个阈值。为了确保我们的mIoU测量对单调变换同样不变,我们在每个模型的最小激活值和最大激活值之间评估20个均匀分布的阈值。对于每个基线模型,我们报告最佳阈值的结果,以确保在所有网络之间进行公平的比较。
实现:我们通过对数据集中的图像-音频对评估每个模态特定网络,计算图像热图。我们从每个网络的最终层提取稠密特征,并根据公式1形成它们的相似度体积。对于DenseAV,我们对头部维度进行最大池化,以便与单头模型进行适当比较。我们利用真实音频片段中的单词时间信息,在“[object]”发音的时间范围内对激活进行平均。这在图像特征上生成了一个热图,可以通过双线性插值调整到原始图像的尺寸。然后,我们将这些逐像素的激活分数与数据集中真实的对象掩码进行比较。
结果:在表1的语音mAP和mIoU列中,我们展示了DenseAV在语音提示的语义分割任务中相比之前的方法实现了51%(+16.5 mAP)的相对提升。使用基于全局标记的对比策略的方法(如CAVMAE和ImageBind)在这个任务中表现尤为不佳,这一观察结果与图2中的定性结果一致。

表1. 语音和声音提示的语义分割。我们通过两个提示语义分割任务分析局部特征的质量。我们提示网络使用形式为“a picture of a(n) [Object]”的语音,来判断局部特征内积是否可以通过名称分割ADE20K数据集中的对象。我们通过从ADE20K本体到VGGSound本体的精心映射,为给定的ADE20K类创建声音提示。DenseAV的局部特征表现明显优于所有基线方法。我们将“第一名”结果加粗,并将“第二名”结果下划线标记。
4.3. 声音提示的图像分割
数据集:为了评估深度特征定位声音的能力,我们基于第4.2节创建了一个与ADE20K类别对齐的声音提示数据集。我们首先选择相同的(较大)ADE20K中的图像-对象对。接着,我们在ADE20K和VGGSound【6】本体之间创建映射。为了计算一个可靠的映射,我们首先使用GPT Ada 2文本嵌入模型【37】嵌入ADE20K类名和VGGSound类名。对于每个ADE20K类,我们从VGGSound本体中创建一个余弦相似度(> 0.85)的最多三个候选列表。然后,我们手动审核这些候选项,选择每个ADE20K类的最佳VGGSound类,并移除任何错误或不相关的匹配。这产生了95个ADE20K类,这些类在VGGSound本体中有较强的匹配。对于我们最初的3030个图像-对象对中的每一个,我们根据映射的本体选择一个随机的VGGSound验证片段,其中类名匹配。最终生成了106对图像-对象对,涵盖20个ADE20K类别。
评估指标:我们使用与第4.2节相同的mAP和mIoU评估指标,但取平均值的对象类别为20个ADE20K类别。
实现:我们计算声音提示的图像激活,方法与第4.2节相同,但有一个关键的变化:我们对整个片段的激活进行平均,因为我们没有声音的真实时间信息。
结果:表1中的“Sound mAP和mIoU”列显示,DenseAV在声音提示的分割任务中相较于现有技术取得了25%(+6.4 mAP)的相对提升。最值得注意的是,尽管ImageBind的特征通过数百万小时的声音学习表现出了很高的跨模态检索性能,但它的特征无法定位声音。
4.4 跨模态检索
我们表明,DenseAV的表示不仅更好的本地化,但显着优于其他方法的跨模态检索。我们采用[23]的评估设置,并在千路检索任务中测量1,5和10的跨模态检索准确率。特别是,我们使用了来自[23]验证集的相同的一千张图像,并对AudioSet验证数据中的一千个随机片段进行了重复分析。表2显示了Places Audio和AudioSet数据集上的1000路检索任务的结果。我们在10处显示了跨模态精度,但在补充中也显示了更大的表格,以反映使用精度为1和5的结果。DenseAV在所有指标上都显著优于所有基线。有趣的是,DenseAV在可训练参数不到一半的情况下优于ImageBind,并且不依赖于文本。

表2. 使用PlacesAudio和AudioSet验证数据集中的1000个评估视频进行跨模态检索。DenseAV在所有测试的指标上都显著超越了所有方法。最值得注意的是,最先进的图像检索基础模型ImageBind无法识别语音。我们注意到,ImageBind的作者并未发布重新训练的代码,因此我们评估了其最大的预训练模型。带有*号的模型表示其结果已在文献中报道。其他数值通过使用可用的预训练模型或通过作者的官方训练脚本进行训练计算得出。
4.5 测量解耦
我们观察到,DenseAV的多个头部能够自然地学习区分捕捉单词含义(语言)和捕捉物体声音(声音)的音视频耦合。此外,这种效果能够推广到新的片段,包括同时包含声音和语言的片段,如图1所示。我们通过两种方式量化这一观察结果:第一种方法测量某个头部的平均激活强度是否能够预测片段主要包含“语言”或“声音”;第二种方法量化当“语言”头部应该激活时“声音”头部错误激活的频率,反之亦然。
我们利用了AudioSet数据集中大多数片段主要包含环境声音,很少包含语言的事实。与此相反,Places Audio完全基于语言,不包含外部环境声音。需要注意的是,这些分析是专门针对我们拥有两个头部(
K
=
2
K = 2
K=2)且在AudioSet和PlacesAudio数据上共同训练的架构。
对于解耦的两个指标,我们首先计算每个头部的聚合相似度。特别是,我们去除了公式2中的头部最大池化操作,以创建单头相似度
S
(
a
,
v
)
k
S(a, v)_k
S(a,v)k。接着,我们对每个头部的分数在两个数据集上进行极小-极大归一化,使其落在
[
0
,
1
]
[0, 1]
[0,1] 区间内,称之为
S
^
(
a
,
v
)
k
\hat{S}(a, v)_k
S^(a,v)k。使用这些归一化分数,我们可以创建度量标准,以衡量给定头部在特定数据集上响应的效果如何。
我们的第一个指标衡量某个头部的分数预测片段是否来自“声音”或“语言”数据集的效果。令 ( a b , v b ) 1 B (a_b, v_b)^B_1 (ab,vb)1B 表示成对的音频和视觉信号元组,令 l [ k ′ ] b l[k']_b l[k′]b 是一个指示变量,用于表示信号 ( a b , v b ) (a_b, v_b) (ab,vb) 来自声音数据集 AudioSet ( k ′ = 1 k' = 1 k′=1),还是来自语言数据集 Places Audio ( k ′ = 2 k' = 2 k′=2)。公式如下:
δ p r e d ( k , k ′ ) = AP ( ( S ^ ( a b , v b ) k ) 1 B , ( l [ k ′ ] b ) 1 B ) ( 6 ) \delta_{pred}(k, k') = \text{AP}\left( (\hat{\mathcal{S}}(a_b, v_b)_k)_1^B, (l[k']_b)_1^B \right) \quad (6) δpred(k,k′)=AP((S^(ab,vb)k)1B,(l[k′]b)1B)(6)
其中,AP(·, ·) 是二元平均精度,分别使用预测值和标签作为参数。直观上,这衡量了头部 k k k 的分数是否可以直接预测数据是否来自数据集 k ′ k' k′。我们可以找到头部和数据集之间的最佳匹配,使每个头部对给定数据集的预测能力最大化:
PredDis = 1 2 max ( δ p r e d ( 0 , 0 ) + δ p r e d ( 1 , 1 ) , δ p r e d ( 1 , 0 ) + δ p r e d ( 0 , 1 ) ) ( 7 ) \text{PredDis} = \frac{1}{2} \max\left( \delta_{pred}(0, 0) + \delta_{pred}(1, 1), \delta_{pred}(1, 0) + \delta_{pred}(0, 1) \right) \quad (7) PredDis=21max(δpred(0,0)+δpred(1,1),δpred(1,0)+δpred(0,1))(7)
预测解耦得分 PredDis 是一个百分比,范围从 50%(完全混合的信号)到 100%(如果可以通过任意头部的分数完美分类信号)。两个可能的分配取最大值使这个度量对头部的排列顺序不敏感。我们注意到,这个度量是一个匈牙利匹配分配【29】,常用于评估无监督分类性能【20, 28】。
我们的第二个度量量化了非主要头部中的“伪激活”。一个真正解耦的系统应该有一个头部只响应声音,另一个头部只响应语言。我们通过将公式7中的 δ p r e d \delta_{pred} δpred 替换为以下公式来创建另一个解耦度量 ActDis:
δ a c t ( k , k ′ ) = 1 − 1 ∑ b ′ l [ k ′ ] b ′ ∑ b = 1 B S ^ ( a b , v b ) k ⋅ l [ k ′ ] b ( 8 ) \delta_{act}(k, k') = 1 - \frac{1}{\sum_{b'} l[k']_{b'}} \sum_{b=1}^{B} \hat{\mathcal{S}}(a_b, v_b)_k \cdot l[k']_b \quad (8) δact(k,k′)=1−∑b′l[k′]b′1b=1∑BS^(ab,vb)k⋅l[k′]b(8)
直观上,这衡量了头部
k
k
k 在数据集
k
′
k'
k′ 上的“不活跃”程度。如果头部
k
k
k 在数据集
k
′
k'
k′ 上完全静止,则
δ
a
c
t
(
k
,
k
′
)
=
1
\delta_{act}(k, k') = 1
δact(k,k′)=1。与 PredDis 一样,ActDis 是一个百分比,范围从 50% 到 100%,100% 代表完美的解耦,即声音头在语言片段期间完全静止,反之亦然。
表3显示,DenseAV在预测(99%)和激活(91%)解耦方面接近完美。它还显示,我们的解耦正则化器和头部最大池化提高了DenseAV在没有监督的情况下自然区分声音和语言的能力。

表3. 最大池化注意力头和添加我们的解耦损失 L D i s L_{Dis} LDis 的影响的定量消融研究。直观上,最大池化注意力头使每个头部能够专注于其自身特定的一组触发器。我们的解耦损失进一步鼓励头部独立且正交地运行。
5.结论
致谢
本材料基于国家科学基金会研究生研究奖学金资助的工作,资助号为2021323067。本材料中表达的任何观点、发现、结论或建议均为作者的观点,不一定反映国家科学基金会的观点。这项工作得到了美国国家科学基金会的支持,合作协议PHY-2019786(NSF人工智能和基础交互研究所,http://iaifi.org/)。这项工作由皇家学会研究教授RSRP\R\241003和EPSRC计划资助VisualAI EP/T028572/1资助。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









