







基于密度的离群点处理
对象的局部密度定义为:
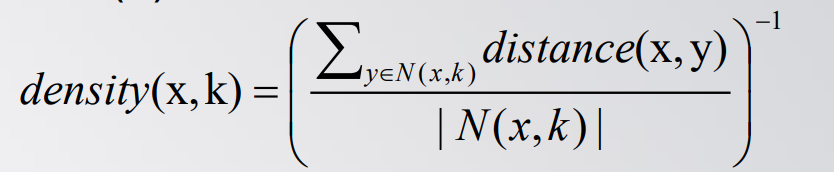
首先对爬取的信息进行提取,得到出现的全部关键词和其出现的次数,同时得到关键词网络的邻接矩阵,对应矩阵的值为该关键词与对应关键词共同的出现次数
def count_keyword(path):
path =path['keyword']
for keywords in path:
if type(keywords) == float:
continue
gaps = ['B/S','C/S']
if gaps[0] in keywords:
keywords=keywords.replace(gaps[0],'B/S')
if gaps[1] in keywords:
keywords=keywords.replace(gaps[1],'C/S')
list = keywords.split('/')
for keyword in list:
if keyword not in keyword_list['key'].values:
count = 1
keyword_list.loc[len(keyword_list)]=[keyword,count]
else:
index = keyword_list[keyword_list.key == keyword].index.tolist()[0]
keyword_list.loc[index]['count']+=1
keyword_list.to_csv('keys1.csv', index=False)
def Adjacency_matrix(keyword):
all_key = [] # 与关键词同时出现的关键词
all_count = []
all_key.append(keyword)
all_count.append(0)
for keywords in data1['keyword']:
if type(keywords) == float:
continue
if type(keywords) == float:
continue
gaps = ['B/S', 'C/S']
lists = keywords.split('/')
if keyword in lists:
for i in lists:
if i not in all_key:
all_key.append(i)
all_count.append(1)
else:
all_count[all_key.index(i)] += 1
count_self = all_count[0]
for i in range(1,len(all_count)):
index = key_count[key_count.key == all_key[i]].index.tolist()[0]
count = key_count.loc[index]['count']
all_count[i] = all_count[i] / min(count, count_self)
zipped = zip(all_key, all_count)
sort_zipped = sorted(zipped, key=lambda x: (x[1]), reverse=True)
result = zip(*sort_zipped)
all_key, all_count = [list(x) for x in result]
# print(all_key)
# print(all_count)
return all_key,all_count
通过开始提到的局部密度计算公式进行计算,得到每个关键词的密度,(值越小代表该词的权重越高)
通过查看密度较高的关键词,来判断是否是质量较差的关键词(爬取中的错误,或是作者自己设置的无意义关键词),如果是,则将其删除
def density(all_key, all_count):
density = 0
lens = len(all_key)
keycount = all_count[0]
pagecount = len(key_count)
idf = keycount / 5
sum = 0
if lens >= 10:
for i in range(1,10):
sum += all_count[i]
density = (9 / sum) * -math.log10(idf)
else:
for i in range(1,lens):
sum += all_count[i]
density = ((lens-1)/ sum) * -math.log10(idf)
return density
for j in range(len(distance)):#遍历所有节点
relation = 0
len_key = len(allword[j])
if len_key >= 10:
for m in range(10):
for word in allword[j] :#遍历邻接矩阵
for k in range(len(distance)):#遍历距离矩阵找到计算邻居的距离和
if word == distance[k][0]:
relation += distance[k][1]
break
relation /=10
else:
for m in range(len_key):
for word in allword[j]: # 遍历邻接矩阵
for k in range(len(distance)): # 遍历距离矩阵找到计算邻居的距离和
if word == distance[k][0]:
relation += distance[k][1]
break
relation /= len_key
print(distance[j][1])
if i == 5:
break
i += 1















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









