






 本文介绍了如何使用Python、Tkinter库创建GUI,配合Selenium和WebDriver进行网页自动化,获取应届生招聘网的招聘信息,包括cookies管理、爬取关键词搜索结果并保存为CSV文件。
本文介绍了如何使用Python、Tkinter库创建GUI,配合Selenium和WebDriver进行网页自动化,获取应届生招聘网的招聘信息,包括cookies管理、爬取关键词搜索结果并保存为CSV文件。
导航
老师留的作业是爬取应届生招聘网。
应届生求职网_校园招聘_YingJieSheng.COM_中国领先的大学生求职网站
这是一个很好的网站。
以下代码仅用于学习交流,请勿用于其它方面。
为了便于使用,简单的制作了一个粗糙的GUI界面,
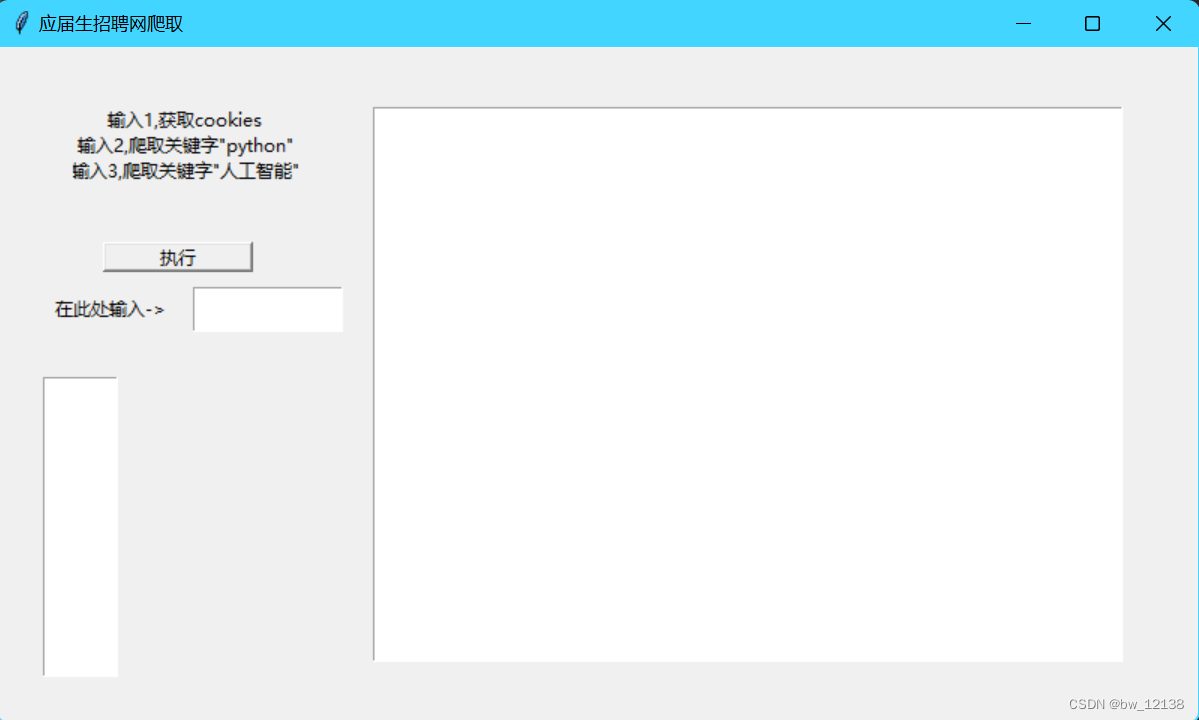
以下开始代码分享:
导入的库
from tkinter import *
import json
import time
import pandas
from selenium import webdriver
import os这引用了几个第三方库便于使用,
from tkinter import * 有了这个库,GUI就能写出来了 import json 对于处理cookies很方便 import time 时间库,用于等一会再执行代码 import pandas 一个非常了不起的库,但是在这个代码中仅仅用于“将数据保存为csv表格文件”从而方便查看 from selenium import webdriver 用于打开网页(类似于自动的手动),非常方便,可以从渲染后的网页中获取数据; import os 文件操作库,可以选择保存的位置以及检测文件是否存在
GUI代码
以下为GUI代码,此部分代码直接扔到
if __name__ == '__main__':
这串代码后面就可以。
root = Tk()
root.geometry('800x450')
root.title('应届生招聘网爬取')
# 文本提示框
lb1 = Label(root, text='输入1,获取cookies\n输入2,爬取关键字"python"\n输入3,爬取关键字"人工智能"')
lb1.place(x=50, y=40, width=150, height=50)
# 操作输入框提示
tips1 = Label(root,text='在此处输入->')
tips1.place(x=30,y=160,width=90,height=30)
# 操作输入框
inp = Entry(root)
inp.place(x=130,y=160,width=100,height=30)
# 文本框
thetxt = Text(root)
thetxt.place(x=30,y=220,width=50,height=200)
# 右侧提示框
lb2 = Text(root)
lb2.place(x=250,y=40,width=500,height=370)
# 确认按钮
btn1 = Button(root, text='执行', command=main)
btn1.place(x=70,y=130,width=100,height=20)
root.mainloop()主函数
def main():
# GUI运行菜单
# root.wm_attributes('-topmost', True) # 设置为置顶
# root.wm_attributes('-topmost', False) # 取消置顶
a = inp.get()
thetxt.insert(END, a+'\n') # 追加显示运算结果
inp.delete(0, END) # 清空输入
if a == '1':
btainPython()
elif a == '2':
Searchpython()
elif a == '3':
btainrengong()
获取cookies并保存
def btainPython():
# 获取cookies
lb2.insert(END, '程序将自动打开浏览器\n'
'请在30秒内手动登录网页\n') # 追加显示运算结果
lb2.delete(0.0, END) # 清空输入
lb2.insert(END, '程序将自动打开浏览器\n'
'请在30秒内手动登录网页\n') # 追加显示运算结果
root.update()
time.sleep(3)
options = webdriver.EdgeOptions()
options.add_experimental_option('detach', True)
obj = webdriver.Edge(options=options)
url = 'https://q.yingjiesheng.com/jobs/search/'
obj.get(url)
obj.maximize_window()
for ti in range(30):
print(ti)
lb2.insert(END, str(ti)+'/30\n') # 追加显示运算结果
root.update()
time.sleep(1)
cookies_json = obj.get_cookies()
cookies_str = json.dumps(cookies_json)
with open('pycookies.txt', 'w') as f:
f.write(cookies_str)
lb2.insert(END, '已将cookies存入[pycookies.txt]\n') # 追加显示运算结果搜索关键字并且输出相关结果
def Searchpython():
lb2.insert(END, '程序将自动打开浏览器\n') # 追加显示运算结果
lb2.delete(0.0, END) # 清空输入
lb2.insert(END, '程序将自动打开浏览器\n') # 追加显示运算结果
root.update()
time.sleep(3)
# 爬取python
option = webdriver.EdgeOptions()
option.add_experimental_option('detach', True)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
obj = webdriver.Edge(options=option)
url = 'https://q.yingjiesheng.com/jobs/search/python'
obj.get(url)
obj.maximize_window()
time.sleep(3)
with open('pycookies.txt', 'r') as f:
cookies_str = f.read()
cookies_json = json.loads(cookies_str)
obj.delete_all_cookies()
for cookie in cookies_json:
obj.add_cookie(cookie)
obj.refresh()
print('cookies')
data = []
lenlist = 0
while lenlist != 25:
time.sleep(2)
ahref = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a')
post = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[1]/div/div')
company = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[3]/div[1]')
education = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[2]/span[3]')
salary = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[2]/div[1]')
city = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[2]/span[1]')
n = len(ahref)
for ic in range(n):
ipost = post[ic].text
icompany = company[ic].text
if len(education) == len(ahref):
ieducation = education[ic].text
isalary = salary[ic].text
icity = city[ic].text
print('\t' + ipost + '\t' + icompany + '\t' + ieducation + '\t' + isalary + '\t' + icity)
d = {
'岗位': ipost,
'公司': icompany,
'学历': ieducation,
'薪资': isalary,
'城市': icity
}
lb2.insert(END, f'{d}\n') # 追加显示运算结果
root.update()
data.append(d)
else:
lenlist = lenlist-1
break
print(lenlist)
lb2.insert(END, f'{lenlist}\n') # 追加显示运算结果
root.update()
next_btn = obj.find_element('xpath','/html/body/div/div/div/div/div[1]/div[2]/div[3]/div[1]/div[1]/div[1]/div[21]/div/button[2]')
next_btn.click()
lenlist = lenlist + 1
df = pandas.DataFrame(data)
if not os.path.exists('python招聘信息.csv'):
df.to_csv('python招聘信息.csv')
else:
os.remove('python招聘信息.csv')
lb2.insert(END, '{python招聘信息.csv}已经存在\n'
'现在已经删除\n') # 追加显示运算结果
root.update()
df.to_csv('python招聘信息.csv')
lb2.insert(END, '已保存\n'
'{python招聘信息.csv}\n') # 追加显示运算结果
root.update()
def btainrengong():
lb2.insert(END, '程序将自动打开浏览器\n') # 追加显示运算结果
lb2.delete(0.0, END) # 清空输入
lb2.insert(END, '程序将自动打开浏览器\n') # 追加显示运算结果
root.update()
time.sleep(3)
# 爬取人工
option = webdriver.EdgeOptions()
option.add_experimental_option('detach', True)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
obj = webdriver.Edge(options=option)
url = 'https://q.yingjiesheng.com/jobs/search/人工智能'
obj.get(url)
obj.maximize_window()
time.sleep(3)
with open('pycookies.txt', 'r') as f:
cookies_str = f.read()
cookies_json = json.loads(cookies_str)
obj.delete_all_cookies()
for cookie in cookies_json:
obj.add_cookie(cookie)
obj.refresh()
print('cookies')
data = []
lenlist = 0
while lenlist != 25:
time.sleep(2)
ahref = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a')
post = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[1]/div/div')
company = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[3]/div[1]')
education = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[2]/span[3]')
salary = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[2]/div[1]')
city = obj.find_elements('xpath', '//*[@id="list"]/div[1]/div/a/div/div[1]/div[2]/span[1]')
n = len(ahref)
for ic in range(n):
ipost = post[ic].text
icompany = company[ic].text
if len(education) == len(ahref):
ieducation = education[ic].text
isalary = salary[ic].text
icity = city[ic].text
print('\t' + ipost + '\t' + icompany + '\t' + ieducation + '\t' + isalary + '\t' + icity)
d = {
'岗位': ipost,
'公司': icompany,
'学历': ieducation,
'薪资': isalary,
'城市': icity
}
data.append(d)
lb2.insert(END, f'{d}\n') # 追加显示运算结果
root.update()
else:
lenlist = lenlist - 1
break
print(lenlist)
lb2.insert(END, f'{lenlist}\n') # 追加显示运算结果
root.update()
next_btn = obj.find_element('xpath',
'/html/body/div/div/div/div/div[1]/div[2]/div[3]/div[1]/div[1]/div[1]/div[21]/div/button[2]')
next_btn.click()
lenlist = lenlist + 1
df = pandas.DataFrame(data)
if not os.path.exists('人工智能招聘信息.csv'):
df.to_csv('人工智能招聘信息.csv')
else:
os.remove('人工智能招聘信息.csv')
lb2.insert(END, '{人工智能招聘信息.csv}已经存在\n'
'现在已经删除\n') # 追加显示运算结果
root.update()
df.to_csv('人工智能招聘信息.csv')
lb2.insert(END, '已保存\n'
'{人工智能招聘信息.csv}\n') # 追加显示运算结果
root.update()
源文件下载


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









