



 本文详细介绍Flume的安装配置及应用案例,包括监控端口数据、实时监控单个及多个文件,深入解析FlumeAgent架构与事务处理,适合初学者快速上手。
本文详细介绍Flume的安装配置及应用案例,包括监控端口数据、实时监控单个及多个文件,深入解析FlumeAgent架构与事务处理,适合初学者快速上手。
20.1.28 Flume日志收集 学习
第 1 章 Flume 概述
1.1 Flume 定义

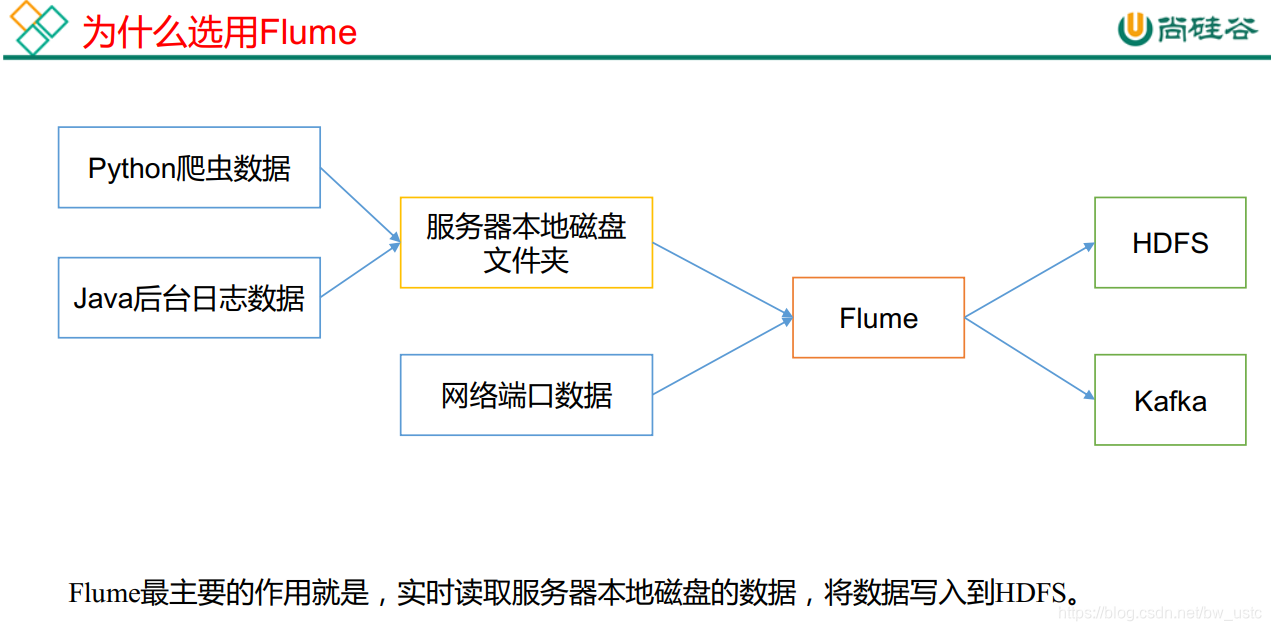
每一个节点都可以配置一个flume 这样就是分布式的了
爬虫数据和后台日志数据都是在本地文件系统内的
1.2 Flume 基础架构
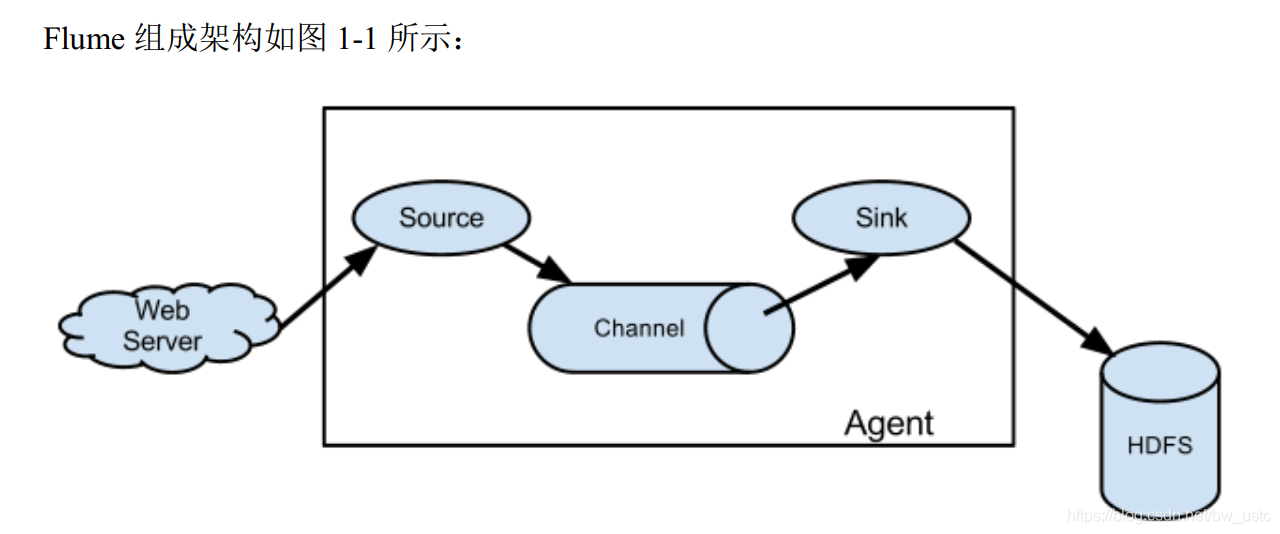





第 2 章 Flume 快速入门
2.1 Flume 安装部署
1)将 apache-flume-1.7.0-bin.tar.gz 上传到 linux 的/opt/software 目录下

2)解压 apache-flume-1.7.0-bin.tar.gz 到102的/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3) 修改 apache-flume-1.7.0-bin 的名称为 flume
[BW@hadoop102 module]$ mv apache-flume-1.7.0-bin/ flume
4) 将 flume/conf 下的 flume-env.sh.template 文件修改为 flume-env.sh,并配置 flumeenv.sh 文件
[atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh
[atguigu@hadoop102 conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
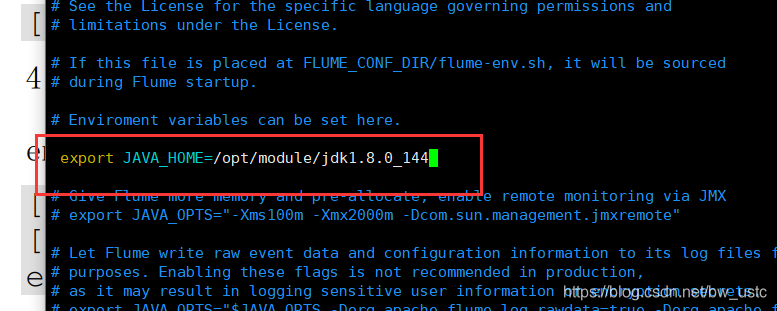
至此Flume安装完成
注意 没有分发Flume到103 104 上。
2.2 Flume 入门案例
2.2.1 监控端口数据官方案例


3)实现步骤:
1.在102 103 104安装 netcat 工具
[atguigu@hadoop102 software]$ sudo yum install -y nc

安装了就可以使用netcat工具了 它可以开启一个客户端,也可以开启一个服务端
在102开启服务端:
[BW@hadoop102 flume]$ nc -lk 4444
发现会阻塞:
在103开启客户端:
[BW@hadoop103 module]$ nc hadoop102 4444
相互发消息 都可以收到 所以是利用端口做通信用的
利用 ^C 关闭102服务端,会发现103客户端也被关闭
2.判断 44444 端口是否被占用
[atguigu@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
3.创建 Flume Agent 配置文件 flume-netcat-logger.conf
在 flume 目录下创建 job 文件夹并进入 job 文件夹:
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
在 job 文件夹下创建 Flume Agent 配置文件 flume-netcat-logger.conf
[atguigu@hadoop102 job]$ vim flume-netcat-logger.conf
在 flume-netcat-logger.conf 文件中添加如下内容。
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
解释:
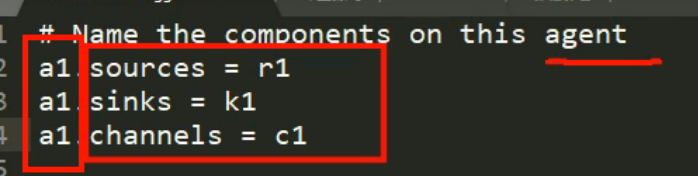
a1 表示当前agent的名字
sources sinks channels 都是负数 说明可能配置多个组件
r1 k1 c1 分别是命名。




一个sinks只能绑定一个channels(只能有一个channels连接一个sink) 但是一个channels 可以指向连接多个sinks

4. 先开启 flume 监听端口
第一种写法:
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
第二种写法:
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console

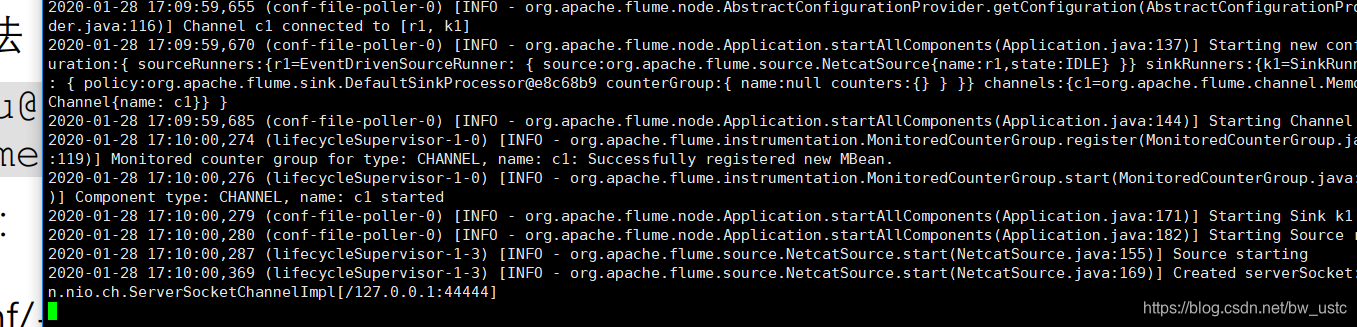
相当于开启了一个服务端
5.使用 netcat 工具向本机的 44444 端口发送内容
[atguigu@hadoop102 ~]$ nc localhost 44444
hello
atguigu
在102 上开启客户端:发现阻塞了
然后打印hello
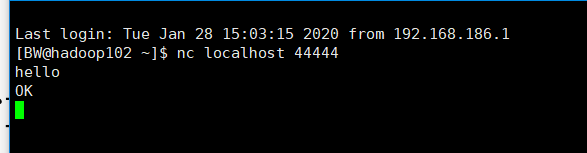
发现日志接收成功:

2.2.2 实时监控单个追加文件

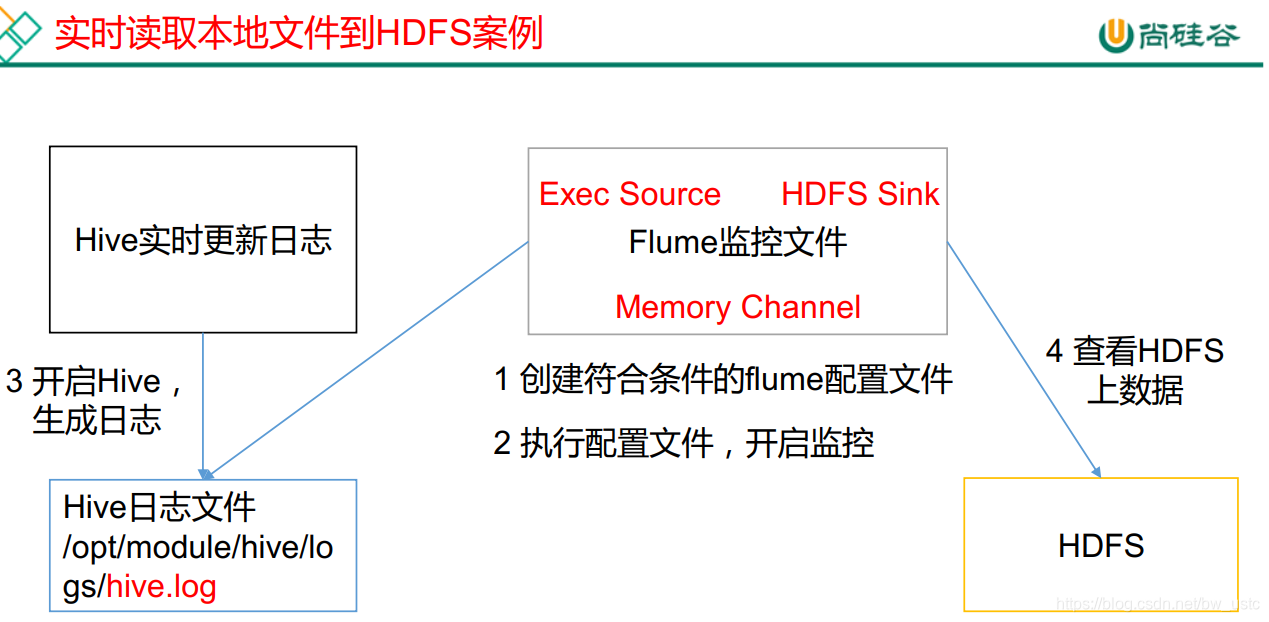
第一步先输出到控制台上:

黑体的是必选项,必须要配置,不然会报错
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /opt/module/hive/logs/hive.log
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
tail -f 监控后面路径的本地文件 读取后10行内容。
然后启动Hadoop集群:
[BW@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[BW@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
开启flume
[BW@hadoop102 flume]$ bin/flume-ng agent -c -conf/ -f job/file-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
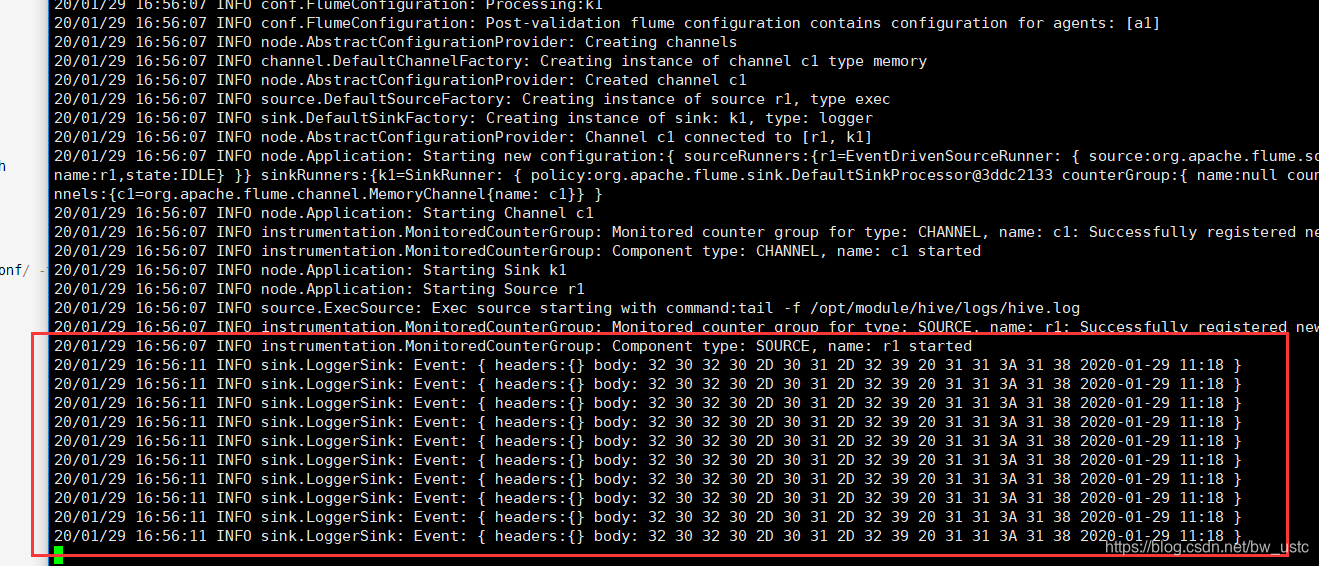
一开始默认读10行
然后开启hive

查看:
hive (default)> select * from aa;
然后发现flume有变化 说明flume是实时监测日志的!
以上是输出到控制台 接下来是输出到HDFS上:
3)实现步骤:
1.Flume 要想将数据输出到 HDFS,须持有 Hadoop 相关 jar 包
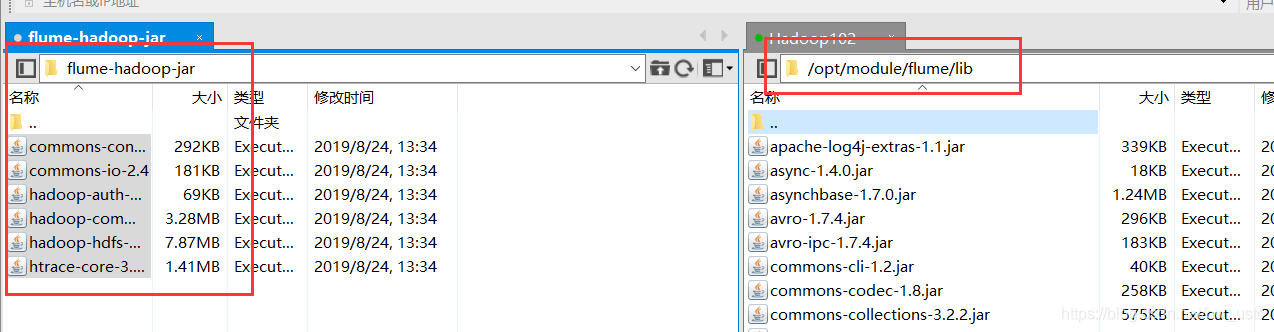
拷贝到/opt/module/flume/lib 文件夹下。
2.创建 flume-file-hdfs.conf 文件
创建文件
[atguigu@hadoop102 job]$ vim flume-file-hdfs.conf
注: 要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。 由于 Hive 日志
在 Linux 系统中所以读取文件的类型选择: exec 即 execute 执行的意思。 表示执行 Linux
命令来读取文件。
添加如下内容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
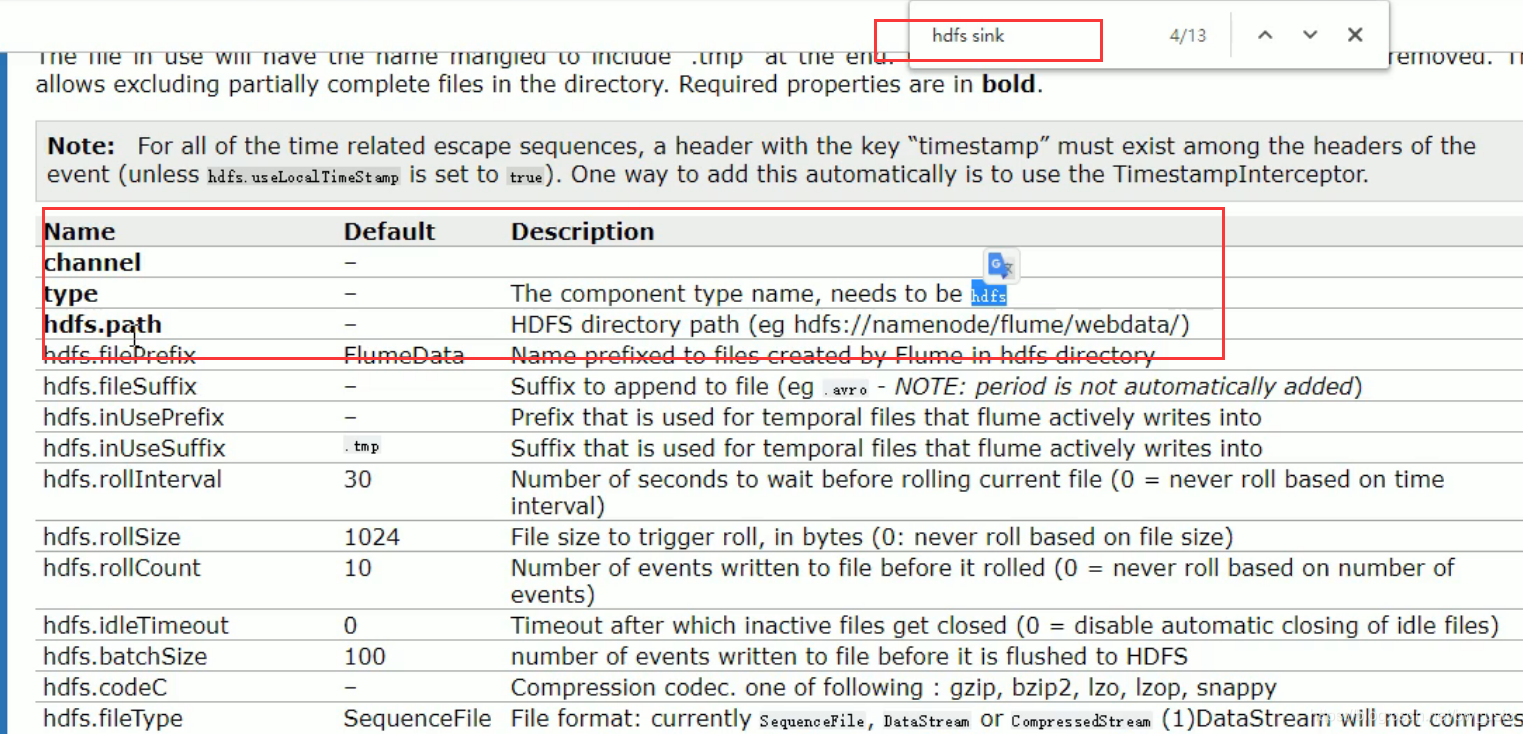
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2


这里滚动的是文件

这三个条件满足其一,都会生成一个新的文件。
经常将 hdfs.rollSize 配成块大小128M
一般将 hdfs.rollCount 关闭
一般设置 hdfs.rollIntervel 防止消息来的太慢 两天了还不到128M ,也不能设置过小 防止产生过多小文件。
这里滚动的是文件夹

如果hdfs.round 设置为false,下面两个参数不需要配置,如果设置为true 下面两个参数需要配置 一个是滚动值,一个是滚动单元
3.运行 Flume
启动:

[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a2 -f job/flume-file-hdfs.conf
启动成功:
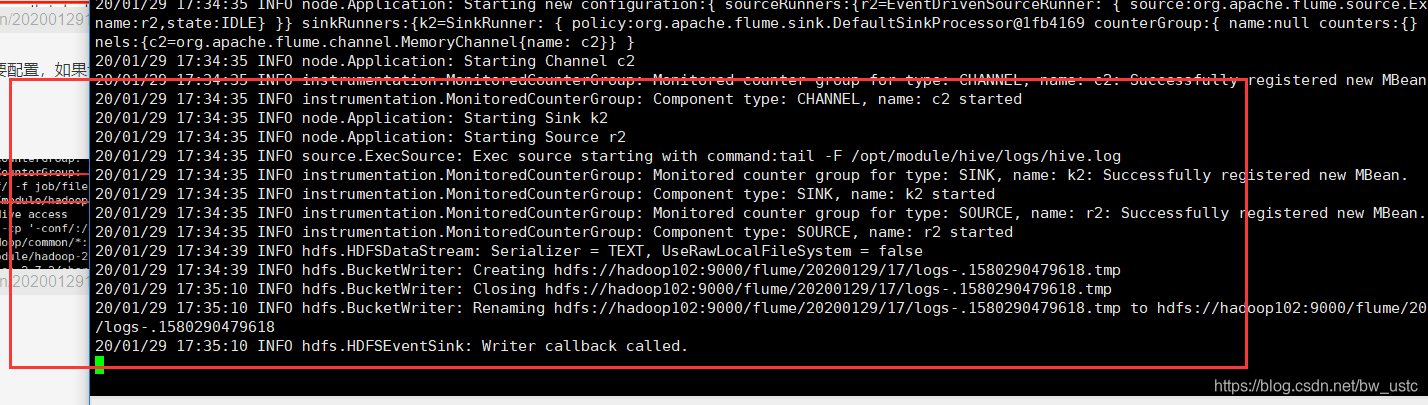
4.开启 Hadoop 和 Hive 并操作 Hive 产生日志
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
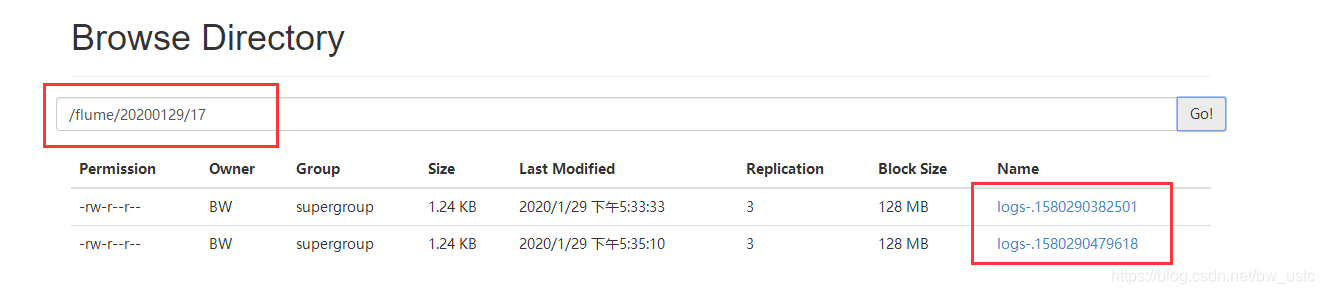
5.在 HDFS 上查看文件。
去102的50070查看日志是否传输成功:
在hive操作下。看日志是否变化:
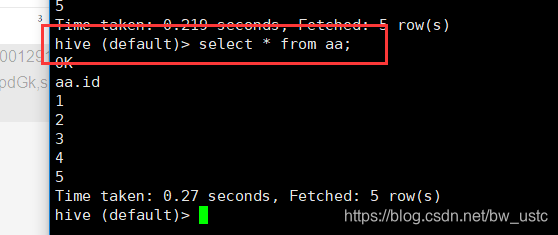
发生变化

50070也多了日志文件:tmp是临时文件,30秒后
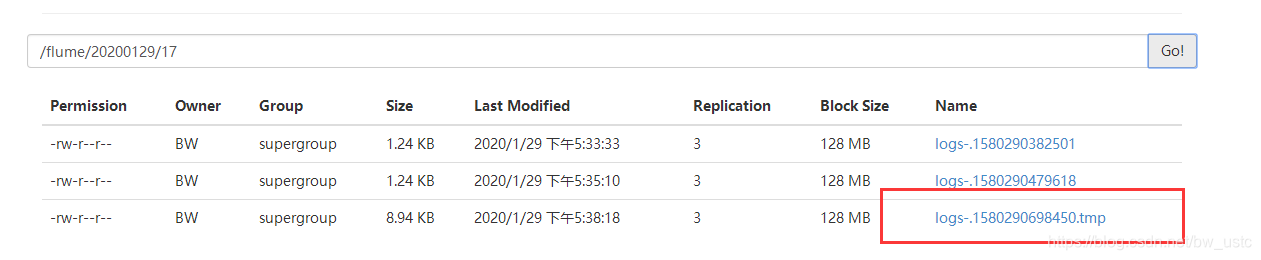
所以完成了将本地的日志采集到hdfs上 然后下载到hive表里进行分析。
2.2.3 实时监控目录下多个新文件
监控整个文件夹:

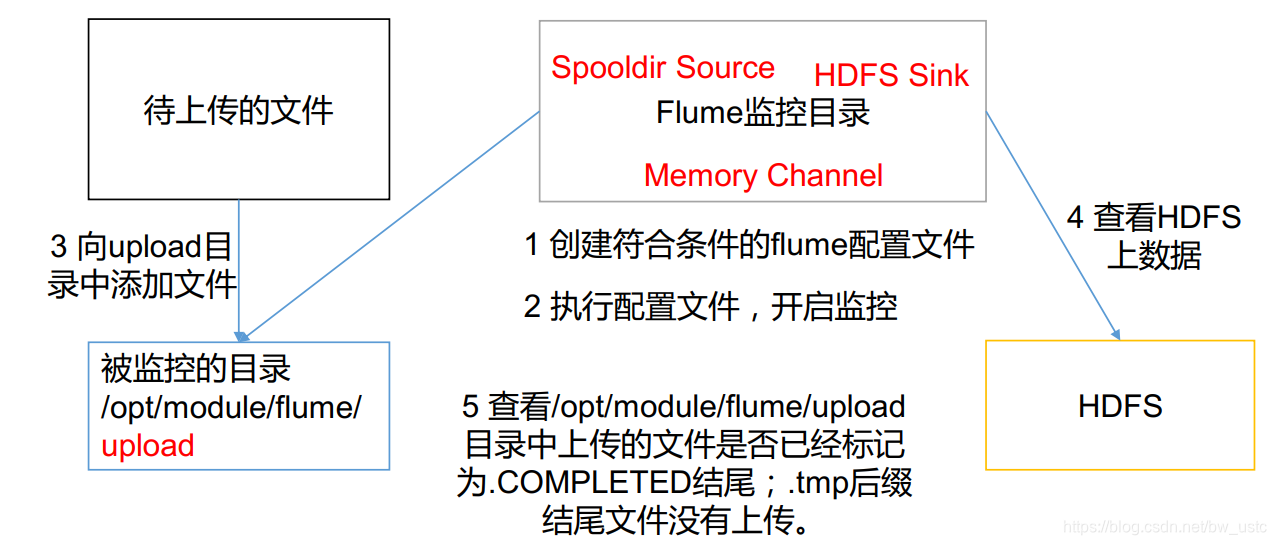
作用:文件夹有新文件传入,那么就会被上传到hdfs上。
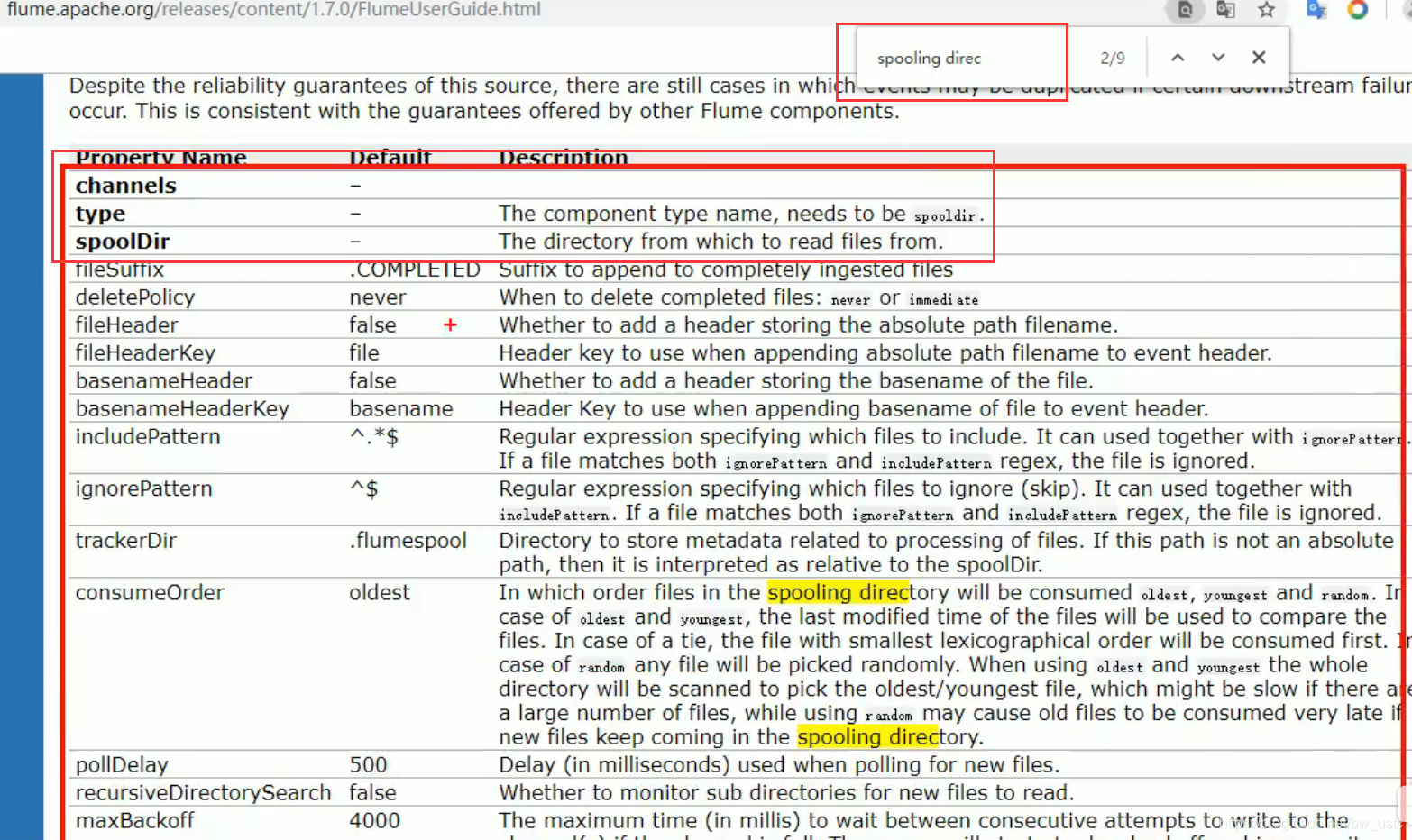
文件后缀


实现步骤:
1.创建配置文件 flume-dir-hdfs.conf
创建一个文件
[atguigu@hadoop102 job]$ vim flume-dir-hdfs.conf
添加如下内容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = spooldir
a2.sources.r2.spoolDir = /opt/module/flume/upload
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2

2.启动监控文件夹命令
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a3 -f job/flume-dir-hdfs.conf

3. 向 upload 文件夹中添加文件

4. 查看 HDFS 上的数据
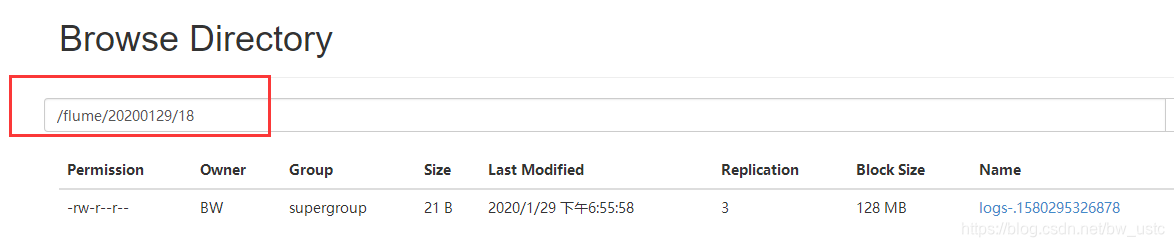
将该文件下载后查看:
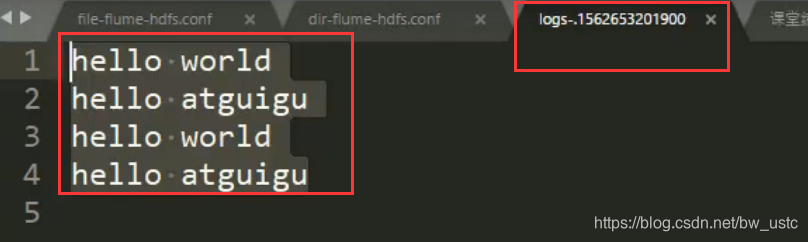
5. 等待 1s,再次查询 upload 文件夹
[atguigu@hadoop102 upload]$ ll
总用量 0
-rw-rw-r--. 1 atguigu atguigu 0 5 月 20 22:31 atguigu.log.COMPLETED
-rw-rw-r--. 1 atguigu atguigu 0 5 月 20 22:31 atguigu.tmp
-rw-rw-r--. 1 atguigu atguigu 0 5 月 20 22:31 atguigu.txt.COMPLETED
特殊情况:
如果修改3.txt, 之后并不会被上传到hdfs,因为不能监控动态变化的数据。
如果将4.txt.COMPLIETED 复制到upload文件夹 也不会上传,后面也不会再加上COMPLIETED这个后缀,只要后缀是COMPLIETED,那么就不会被扫描上传了。

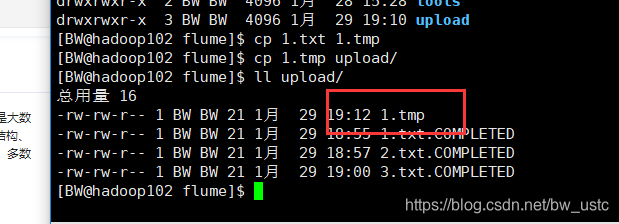
不会被上传,因为配置文件忽略了以tmp结尾的文件。
2.2.4 实时监控目录下的多个追加文件


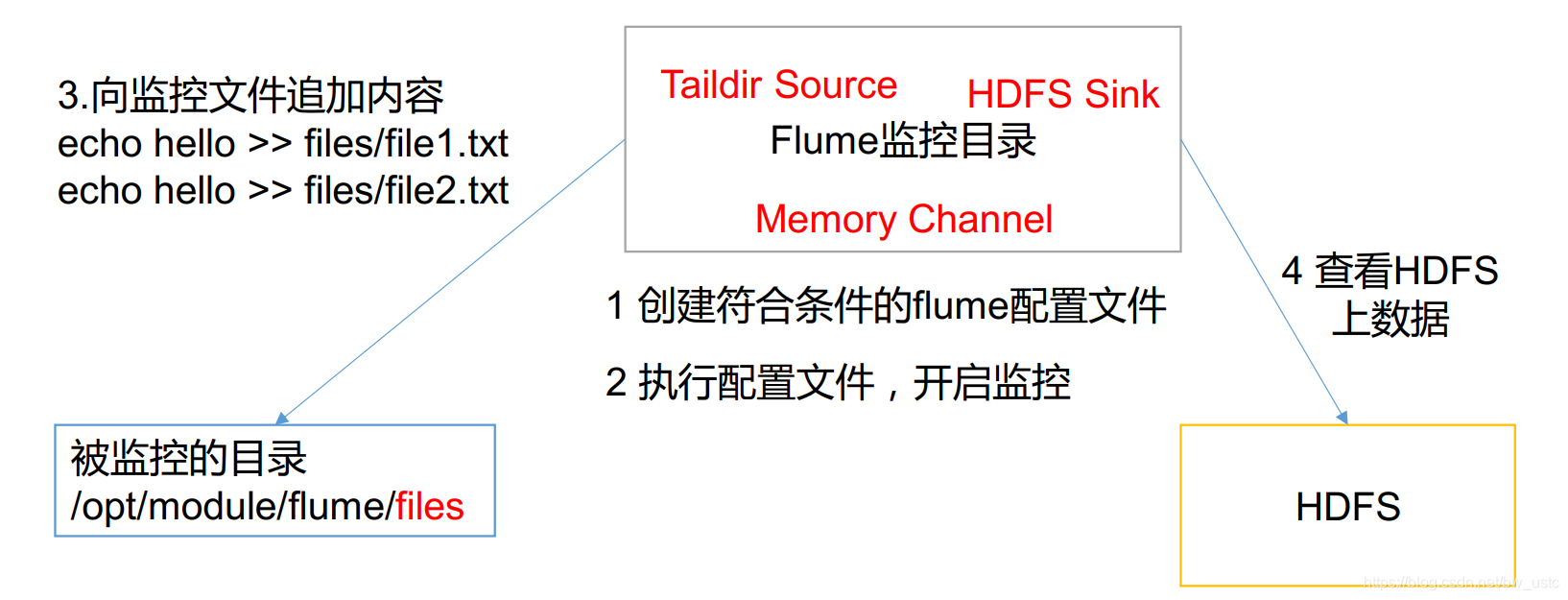
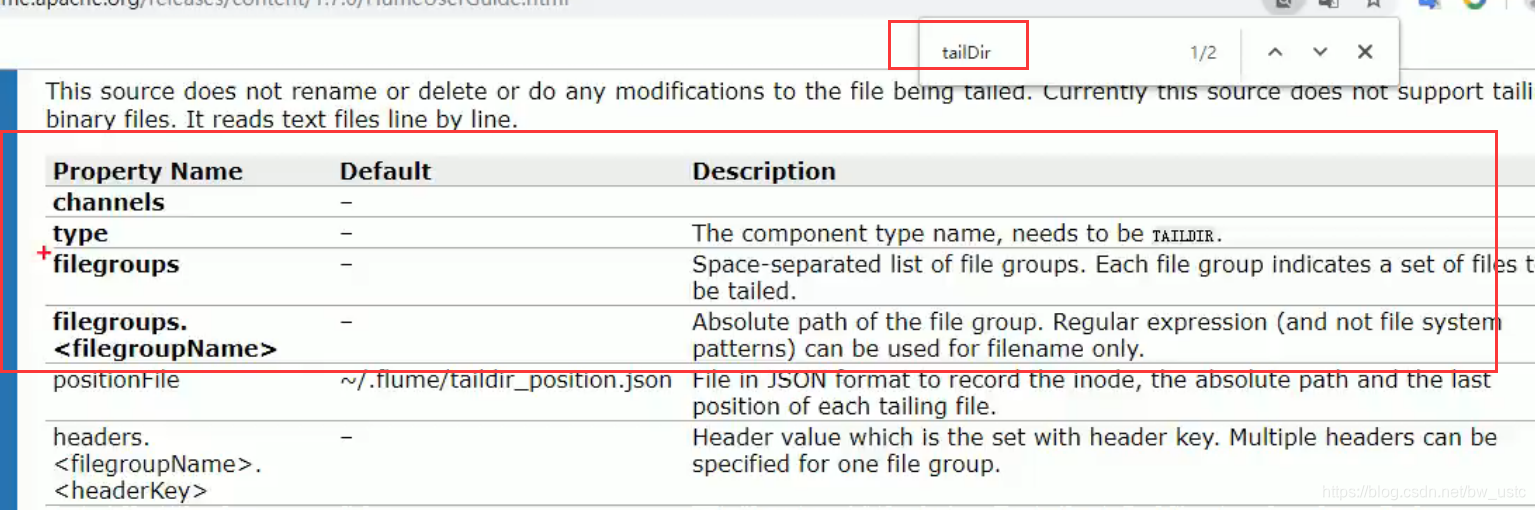


inode
可以监控来自不同文件夹的文件
实现步骤:
1.创建配置文件 flume-taildir-hdfs.conf
创建一个文件
[atguigu@hadoop102 job]$ vim flume-taildir-hdfs.conf
写配置文件:

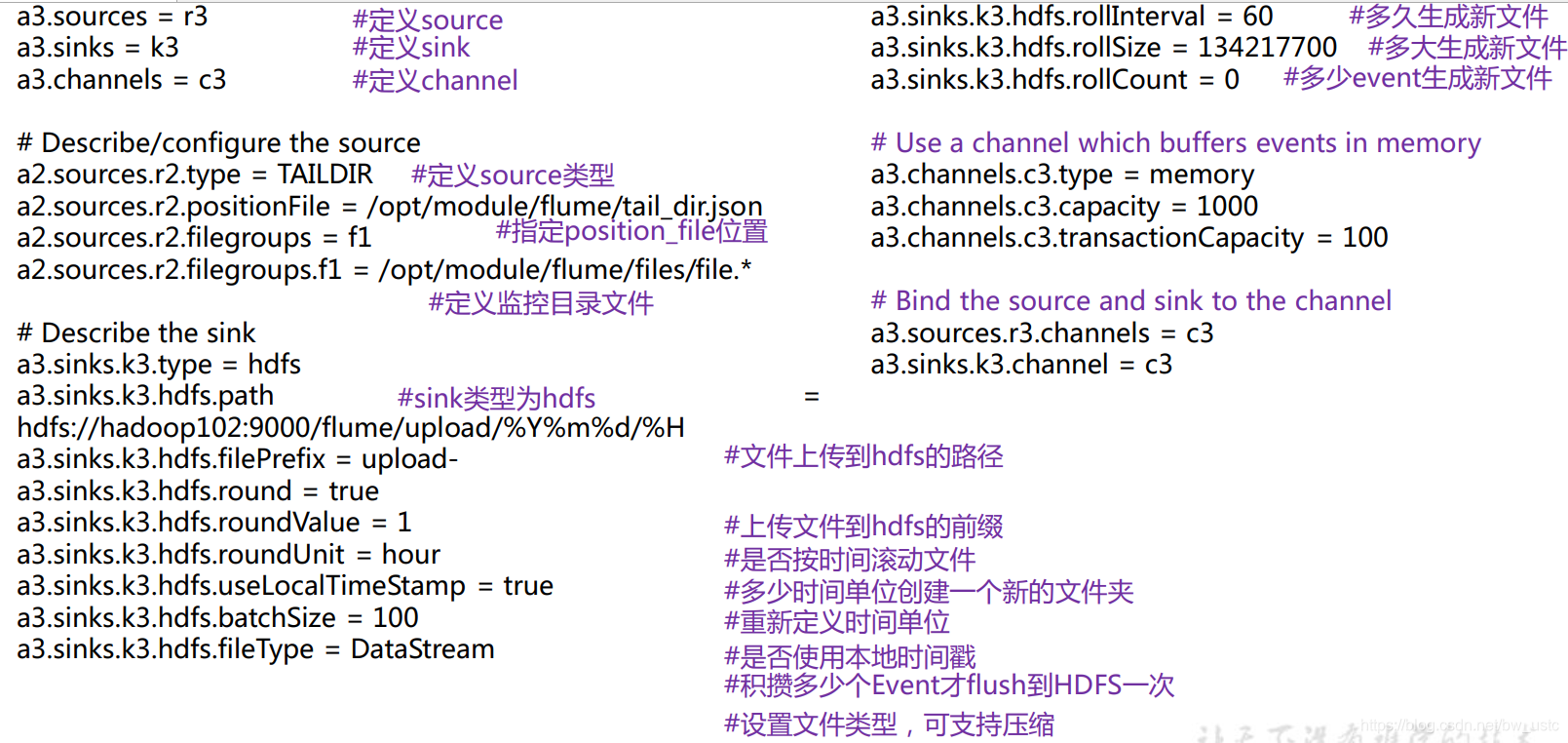
添加如下内容
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/module/flume/files/file1.txt
a1.sources.r1.filegroups.f2 = /opt/module/flume/files/file2.txt
a1.sources.r1.positionFile = /opt/module/flume/position/position.json
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动监控文件夹命令
bin/flume-ng agent -c conf/ -f job/files-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
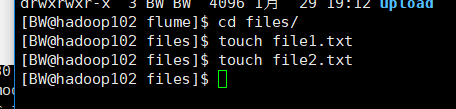
3. 向 files 文件夹中追加内容
在/opt/module/flume 目录下创建 files 文件夹
[atguigu@hadoop102 flume]$ mkdir files
向 upload 文件夹中添加文件
[atguigu@hadoop102 files]$ echo hello >> file1.txt
[atguigu@hadoop102 files]$ echo atguigu >> file2.txt
创建一个文件夹,向里面写两个文件:

随后在file1 file2 追加内容

监控成功:


识别文件
看json文件:

两个文件的inode 唯一标识
下面模拟断点续传
ctrl+c 模拟挂掉了flume

然后继续在在file1 file2 追加内容

然后重新开启flume
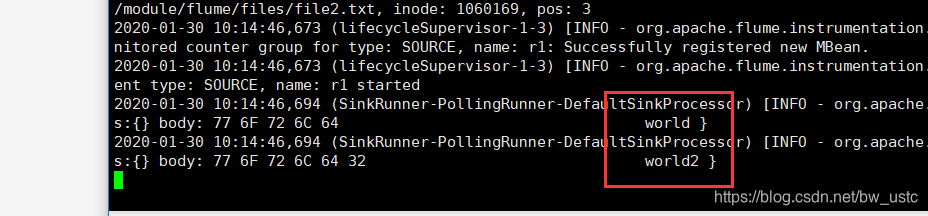
发现成功实现断点续传
如果配置文件改成下面的形式:

测试:

发现 1 没有监控 2监控成功,说明这两个是覆盖关系。

第 3 章 Flume 进阶
3.1 Flume 事务
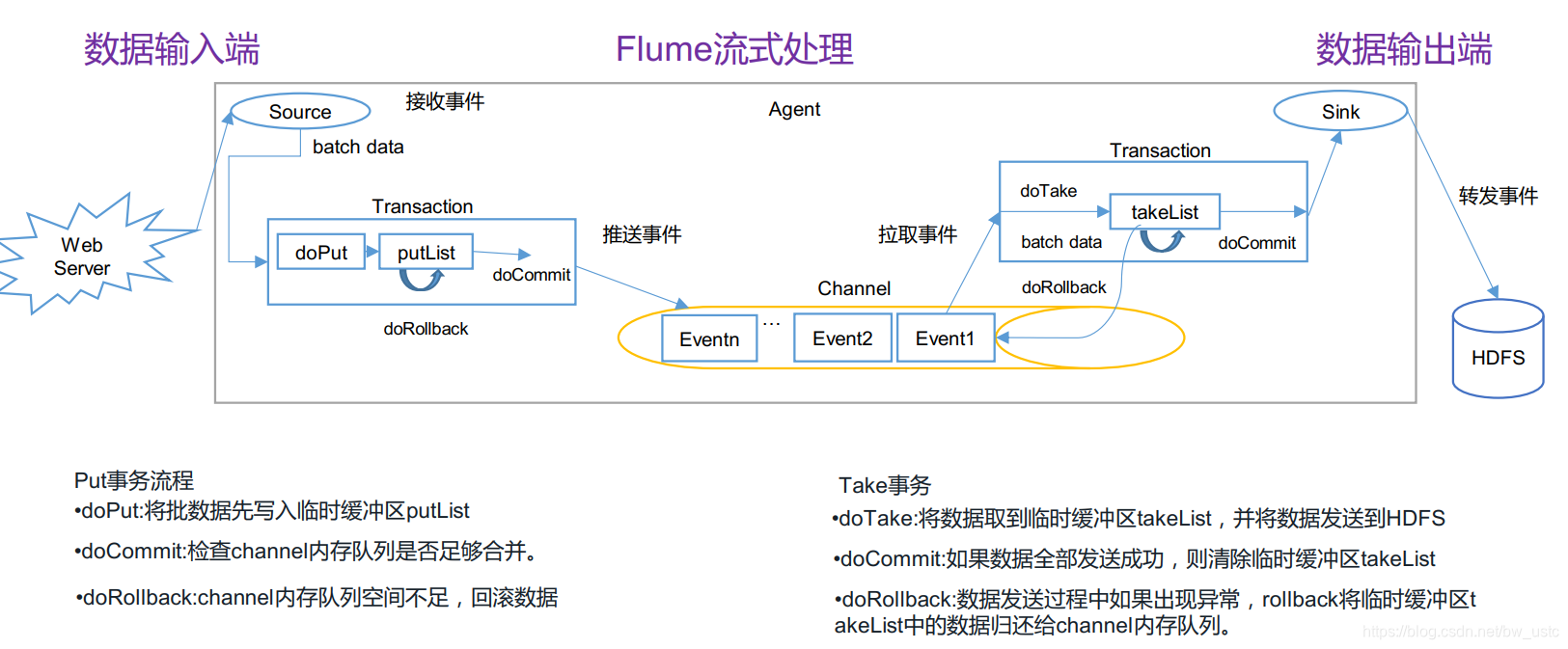
记住画圈的:

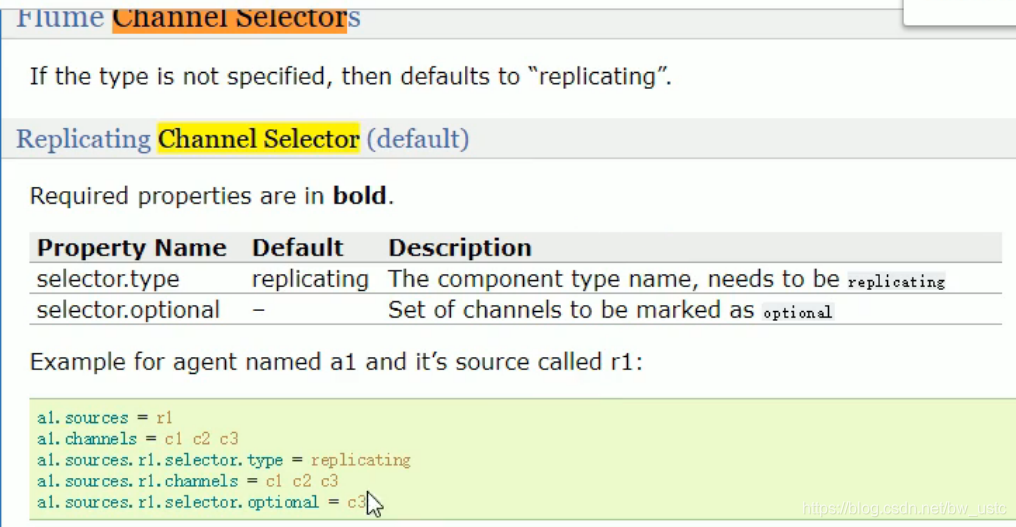
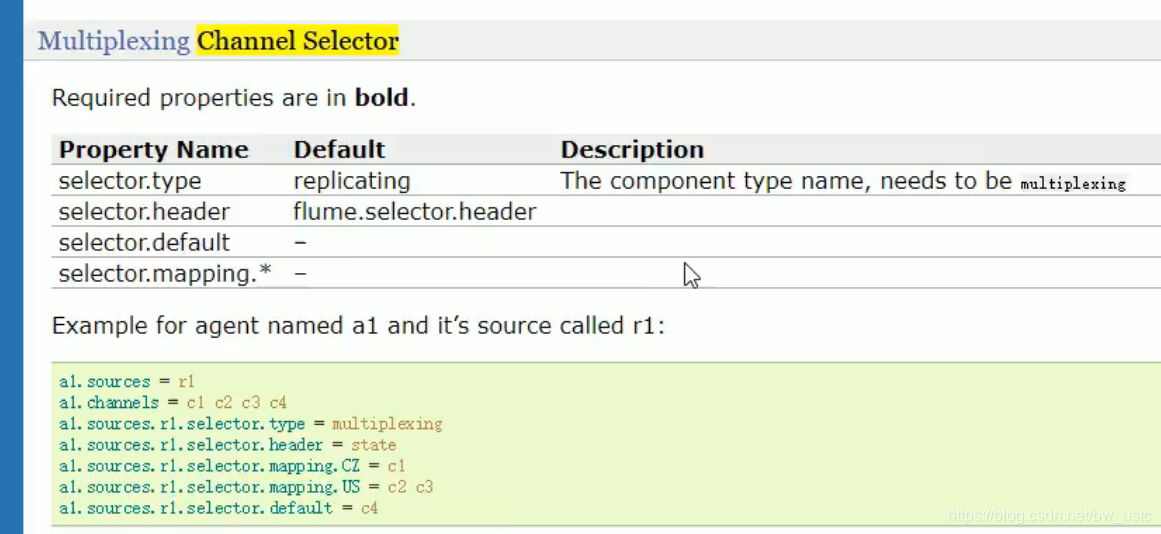
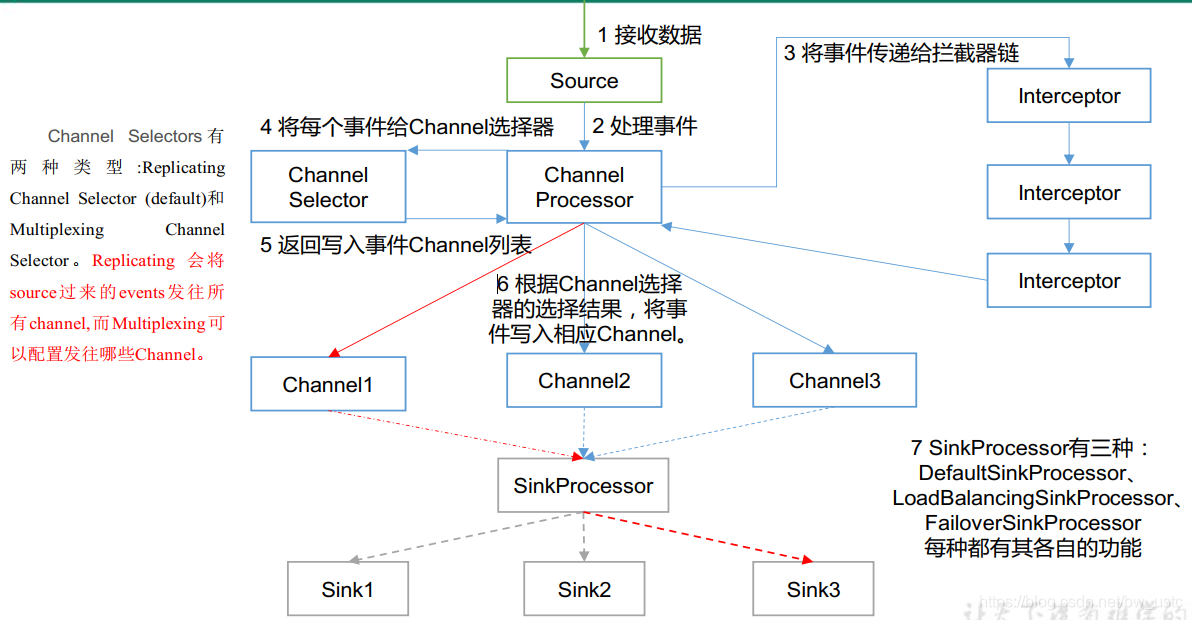
3.2 Flume Agent 内部原理


3.3 Flume 拓扑结构
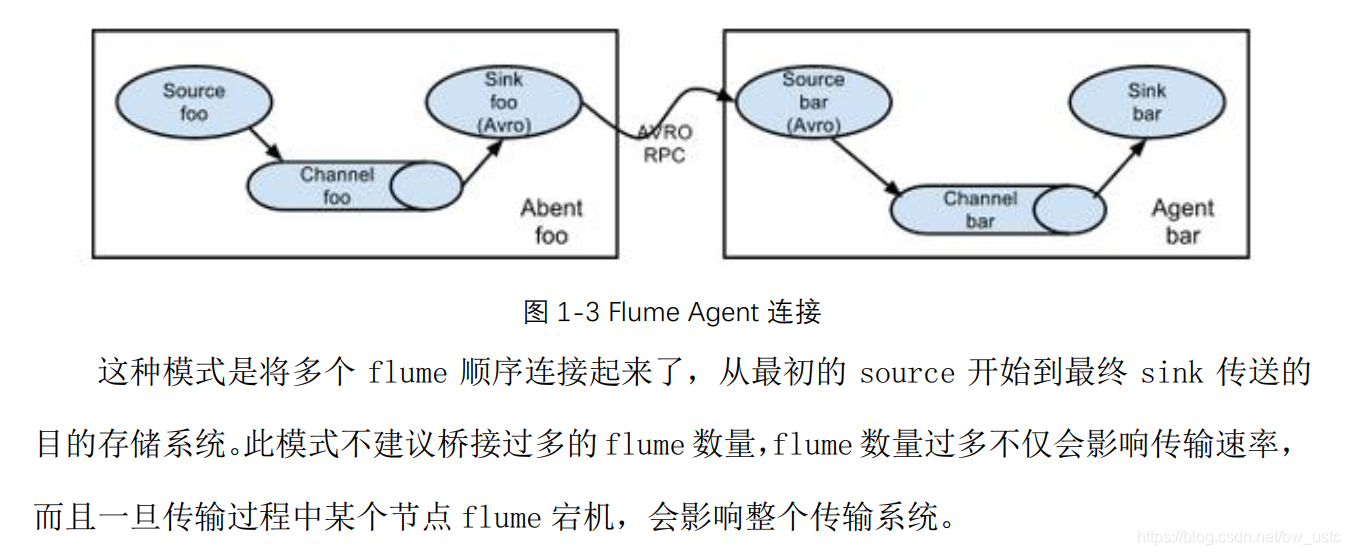
3.3.1 简单串联
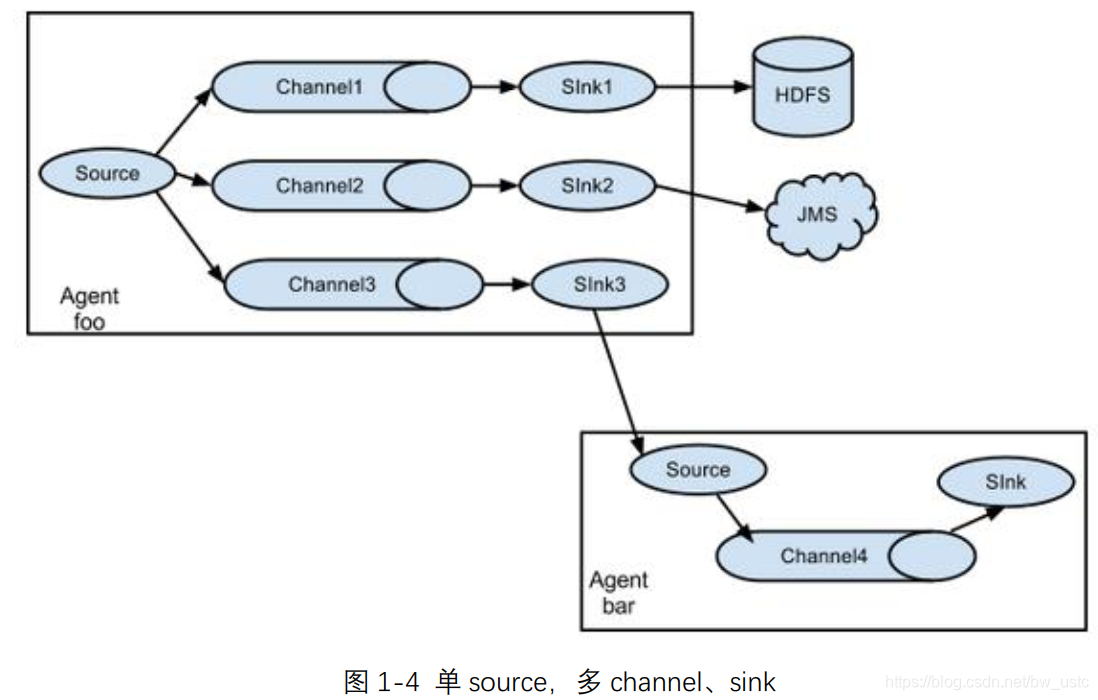
3.3.2 复制和多路复用

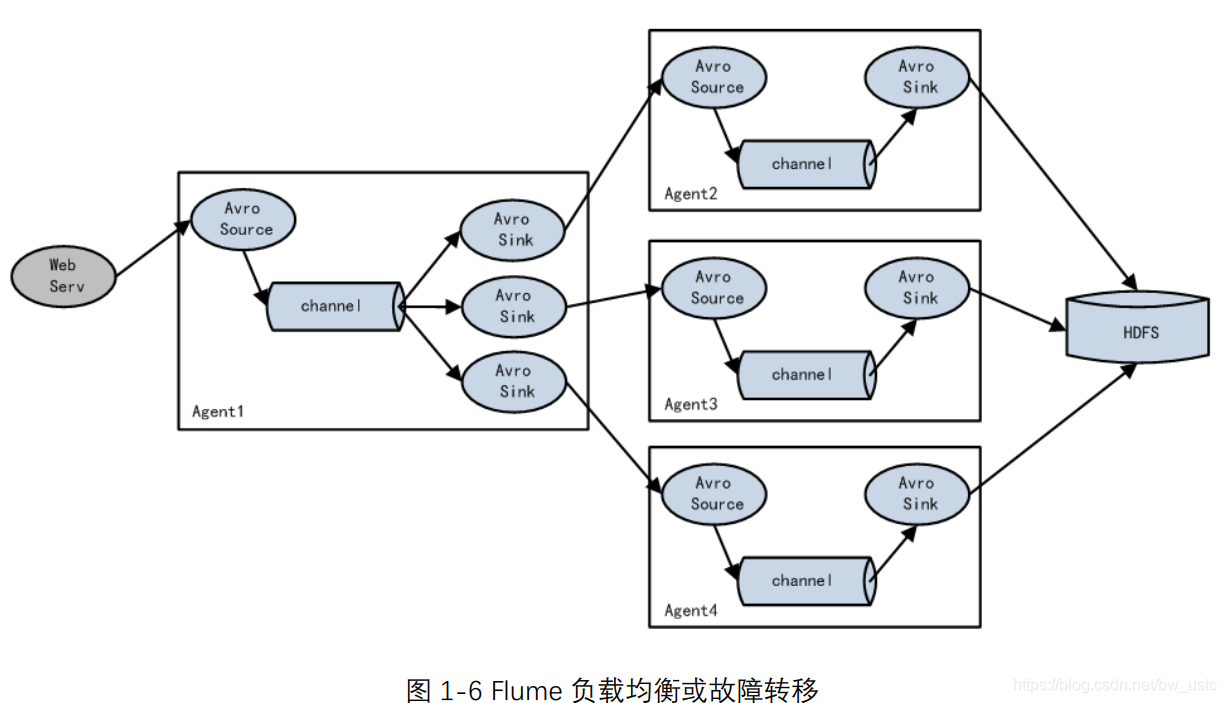
3.3.3 负载均衡和故障转移

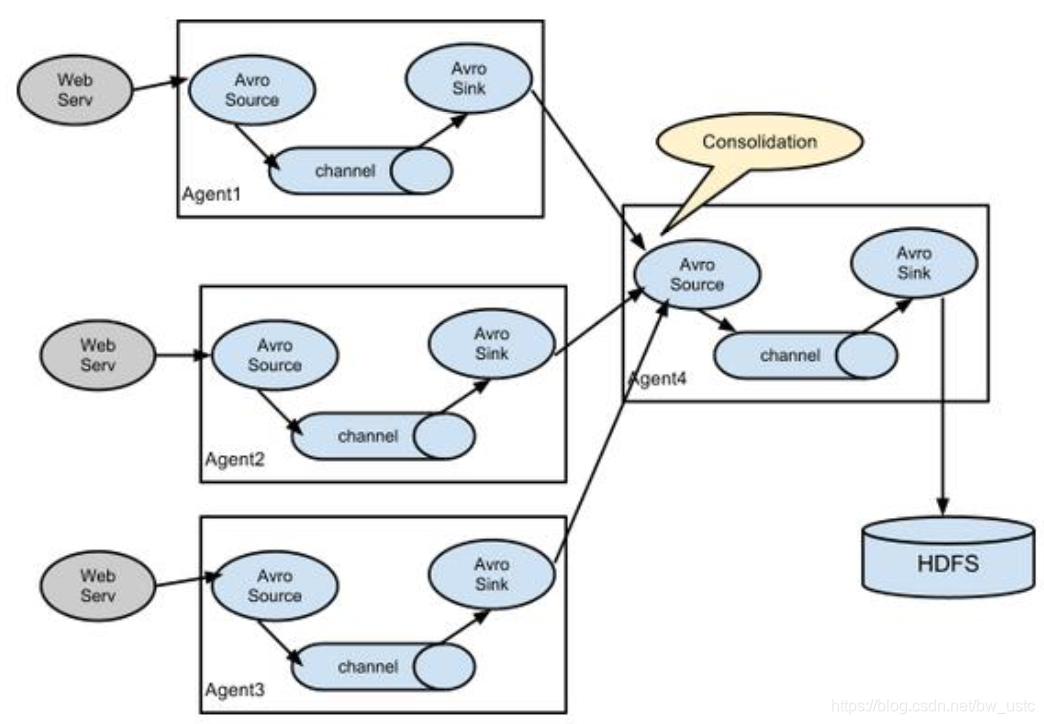
3.3.4 聚合


















 9114
9114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









