






20.2.5 项目实战1 电信客服
按照下图所示建立module:先建立一个maven工程:Bigdata,并删除src文件夹
再其下面再建立一个BW-project-ct的maven工程,删除其src文件夹。
在其下再建立两个maven工程:ct-common 和 ct-producer。

在 ct-producer工程的xml文件中添加依赖,使ct-producer和ct-common相关联:
<dependencies>
<dependency>
<groupId>com.BW</groupId>
<artifactId>ct-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>

工程都准备好了 然后开始写代码:
在common工程添加包:


创建完如下图:
将其复制一下


再新建一个包:constant
三个包新建好后如下图:

创建Val接口:只要跟取值有关系的 都要实现该接口:





创建类
Date数据可能直接用,所以不创建接口,创建类。

接下来在constant新建枚举,Names存放表名等字段

接下来在ct-producer创建包:








第一部分,生产数据代码写完了,简单debug下:

new一个生产者对象。

先new一个LocalFileDataIn对象,然后调用setIn方法,


创建一个流读取对象reader ,这个路径指向需要读取的源文件

然后下一步:

进入方法题:

下一步:

进入方法题:

发现还没写,跳出。
然后下一步:

进入方法题:

新建一个contacts集合,存放读取处理后的内容,这个集合里存放的是contact对象。然后继续进入方法体:

新建一个集合ts 装入处理的数据。继续:

reader对象有个readline的方法,每次可以从源文件读取一行数据。每当可以读取到数据时,进入循环。
每次循环都新建一个t对象。 调用其setValue方法,进入该方法题:

将其转换为string类型的content 然后进行分割,分割的第一部分是电话号,第二部分是姓名,然后进入setName方法体:

设置contact对象的姓名,跳出该方法体。
随后进入setTel方法体:

设置contact对象的电话号。然后跳出setValue方法。继续:

加入ts集合里 继续循环 循环结束后 ts集合里存放着所有的处理好的contact对象,返回ts

继续:

使得contacts 集合等于ts 然后依次打印里面的元素:
运行成功:






第4步如下图所示




然后在Linux执行
[BW@hadoop102 data]$ java -jar /opt/module/data/ct-producer.jar /opt/module/data/contact.log /opt/module/data/call.log
创建flume配置文件:
[BW@hadoop102 data]$ vim flume-2-kafka.conf
成功:

3.2.1 数据采集
思路:
a) 配置kafka,启动zookeeper和kafka集群;
在102 103 104 启动zookeeper
[BW@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
在102 103 104 启动kafka
[BW@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
b) 创建kafka主题;
[BW@hadoop103 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 -create --topic ct --partitions 3 --replication-factor 2

c) 启动kafka控制台消费者(此消费者只用于测试使用);
[BW@hadoop102 kafka]$ /opt/module/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 -topic ct
d) 配置flume,监控日志文件;
# define
a1.sources = r1
a1.sink = k1
a1.channels = c1
#source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/module/data/call.log
a1.sources.r1.shell = /bin/bash -c
#sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = ct
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
e) 启动flume监控任务;
[BW@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f /opt/module/data/flume-2-kafka.conf
g) 观察测试。
成功:

然后创建消费者
然后添加依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>com.BW</groupId>
<artifactId>ct-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>






测试是否可以在IDEA上读取采集的数据:
首先启动jar包生产数据
[BW@hadoop102 data]$ java -jar /opt/module/data/ct-producer.jar /opt/module/data/contact.log /opt/module/data/call.log

然后打开flume采集数据
[BW@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f /opt/module/data/flume-2-kafka.conf

然后点IDEA运行,查看结果

成功读取:

Hbase



添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
</dependencies>

再添加两个文件
新建一个file 名为hbase-site.xml (名字不能变) 然后导入hadoop102 的hbase-site.xml :
[BW@hadoop102 conf]$ cat hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9000/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
再新建一个file 名字叫 log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n



先打开hbase 打开hbase之前一定要开zookeeper和hadoop集群。(之前一直报错 原来是忘了开Hbase了 醉了)
然后重新运行jar
[BW@hadoop102 data]$ java -jar /opt/module/data/ct-producer.jar /opt/module/data/contact.log /opt/module/data/call.log
打开flume监听
[BW@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f /opt/module/data/flume-2-kafka.conf
运行程序:

成功接收:



然后查看数据 是否分区正确:

继续优化代码:





优化后测试:(这次重开的虚拟机,所以安装完整的操作重新记录下:)
开启之前一定要关闭防火墙
1. 在102 103 104开zookeeper:
[BW@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
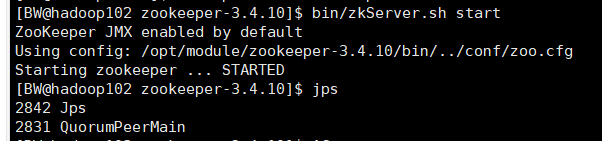
2. 在102开HDFS 在103 开Yarn
[BW@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh

[BW@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh

3. 在102 103 104 开kafka集群
[BW@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
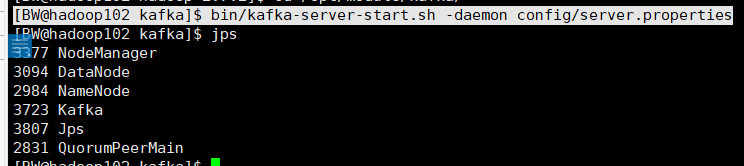
4. 在102 群起Hbase集群
[BW@hadoop102 hbase]$ bin/start-hbase.sh

5. 然后重新运行jar
[BW@hadoop102 data]$ java -jar /opt/module/data/ct-producer.jar /opt/module/data/contact.log /opt/module/data/call.log
6. 打开flume监听
[BW@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f /opt/module/data/flume-2-kafka.conf
运行程序: 成功!!!

增加协处理器

增加依赖



打包:

打包完成后的jar包:两个

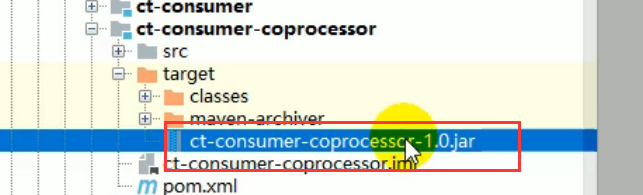
放到hbase/lib/下

然后分发
[BW@hadoop102 hbase]$ xsync lib/
然后退出hbase
[BW@hadoop102 hbase]$ bin/stop-hbase.sh
然后重新打开hbase
[BW@hadoop102 hbase]$ bin/start-hbase.sh
然后重新运行jar包生产数据,重新打开flume进行监听,然后重新运行程序:

成功读取数据:

然后进入hbase进行查看:
[BW@hadoop102 hbase]$ bin/hbase shell
hbase(main):002:0> scan 'ct:calllog'

发现有0有1 说明协处理器起作用了。

在这里也可以看到协处理器信息
开始设计表

id不动
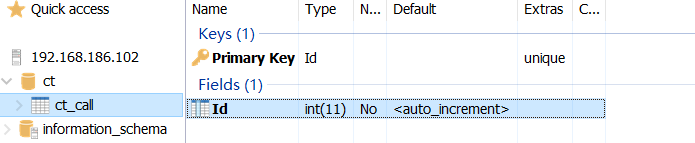

添加字段 telid

添加字段 dateid

添加sumcall字段

添加字段sumduration

这样表就创建完成了

在102拷贝jar包
然后分发103 104
然后打包程序:




完成配置
然后build


打包完成 然后将下面的文件夹上传到 /opt/module/data/ 下


然后放到yarn上去运行
[BW@hadoop102 data]$ /opt/module/hadoop-2.7.2/bin/yarn jar ct_analysis_jar/ct-analysis.jar

运行成功
去看mysql:成功写入mysql:

然后借助redius 将映射表的数据加载到缓存,

然后添加依赖关系:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
</dependencies>
然后建一个包


测试redis
进入hadoop02的 /usr/local/bin 目录,启动Redis的服务端 然后启动客户端
[BW@hadoop102 bin]$ redis-server /myredis/redis.conf
[BW@hadoop102 bin]$ redis-cli
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> keys *
1) "ct_user"
127.0.0.1:6379> HGETALL ct_user
成功:

写好程序后 直接打包:
之前配置过,现在直接打


然后将下面这个jar包上传到下面这个目录下:

覆盖

因为要运行redis,所以要把jar包放到hadoop里去

以后所有的jar包都可以去官网下载
然后把两个jar包分发
[BW@hadoop102 common]$ xsync jedis-2.8.1.jar
fname=jedis-2.8.1.jar
pdir=/opt/module/hadoop-2.7.2/share/hadoop/common
------------------- hadoop103 --------------
sending incremental file list
jedis-2.8.1.jar
sent 538937 bytes received 31 bytes 215587.20 bytes/sec
total size is 538792 speedup is 1.00
------------------- hadoop104 --------------
sending incremental file list
jedis-2.8.1.jar
sent 538937 bytes received 31 bytes 359312.00 bytes/sec
total size is 538792 speedup is 1.00
[BW@hadoop102 common]$ xsync commons-pool2-2.4.2.jar
fname=commons-pool2-2.4.2.jar
pdir=/opt/module/hadoop-2.7.2/share/hadoop/common
------------------- hadoop103 --------------
sending incremental file list
commons-pool2-2.4.2.jar
sent 112070 bytes received 31 bytes 224202.00 bytes/sec
total size is 111969 speedup is 1.00
------------------- hadoop104 --------------
sending incremental file list
commons-pool2-2.4.2.jar
sent 112070 bytes received 31 bytes 224202.00 bytes/sec
total size is 111969 speedup is 1.00
然后将表的数据清空:

然后运行jar包:
[BW@hadoop102 data]$ pwd
/opt/module/data
[BW@hadoop102 data]$ /opt/module/hadoop-2.7.2/bin/yarn jar ct_analysis_jar/ct-analysis.jar
运行成功:

数据又回来了

基本的功能实现以后,要继续改一下KV






再次跑程序:
先将表清空:

然后重新打包:


打包完成后覆盖之前的jar包















 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









