







1.Abstract
作者认为之前的工作集中在寻找图片中的重点区域,但是也应该寻找问题中的重要的单词,所以提出了共同注意力(co-attention),目的是共同的推理图片和问题的注意力。
2.Introduction
作者提出的共同注意力具有以下两种特征:
- Co-Attention 与之前的工作不同,作者的提出的模型是对称的,通过图片表示可以引导产生问题的注意力,问题表示可以引导产生图片的注意力。
- Question Hierarchy 构建了一个层次结构,它在三个级别上共同参与图像和问题:(a)单词级别,(b)短语级别和(c)问题级别。 在单词级别,通过嵌入矩阵将单词嵌入向量空间。 在短语级别,使用一维卷积神经网络捕获单字组,二元组和三字组中包含的信息。具体地说,将单词表示与各种支持的时间过滤器进行卷积,然后将各种n-gram响应组合成一个短语级表示。在问题层,我们使用递归神经网络对整个问题进行编码。对于该层次结构中问题表示的每一层,我们构造联合问题和图像共同注意映射,然后递归地组合这些映射,最终预测答案的分布。
3.Method
3.1 Notation
问题有T个单词,表示为,其中
代表第t个单词的特征向量,
分别为t位置的单词表示,短语表示和问题表示。图片表示为
,其中
表示在空间位置n的特征向量。每一层的图像和问题的共同注意力表示为
和
,其中
。不同单元的权重表示为
,带不用的下标,省略偏置b。
3.2 Question Hierarchy
对于问题中的单词,首先映射到向量
,为了计算短语特征,在单词嵌入向量上应用一维卷积。具体地说,在每个词的位置,我们用三个窗口大小的过滤器计算词向量的内积:一元图、二元图和三元图。对于第t个字,窗口大小为s的卷积输出由下式给出:
![]()
其中是权重参数,单词级特征
在进入二元和三元卷积之前被适当地填充0,以保持卷积后序列的长度。得到卷积结果之后,然后在每个单词位置对不同的n-grams应用最大池来获得短语级特征
![]()
作者的池化方法不同于在以前的方法,在每个时间步适应性地选择不同的元特征,同时保持原始序列长度和顺序。 最大池化之后使用LSTM对进行编码。 相应的问题级特征
是时间t的LSTM隐藏向量。如下图左侧所示

3.3 Co-Attention
作者提出了两种在图像和问题注意图生成顺序上不同的共同注意机制。第一种机制,称之为平行共同注意,同时产生图像和问题注意。第二种机制,称之为交替的共同注意,在生成图像和问题注意之间依次交替。这些共同注意机制在问题层级的所有三个级别上都执行。

Parallel Co-Attention
并行的共同关注同时关注图像和问题。通过计算所有图像位置和问题位置对的图像和问题特征之间的相似性来连接图像和问题。具体来说,给定一个图像特征图,问题表示
,关联矩阵
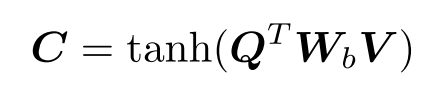
其中是权重,在计算了这个相似性矩阵之后,计算图像(或问题)注意力的一种可能方式是简单地最大化其他模态的位置上的相似性,比如
,
,作者没有选择最大激活,而是发现,如果将这种相似性矩阵视为一种特征,并通过以下方式学习预测图像和问题注意图,性能会得到提高

其中,
是权重参数,
是每个区域
的注意力概率,相似性矩阵C将问题注意空间转换为图像注意空间(反之亦然)。基于上述注意权重,图像和问题注意向量被计算为图像特征和问题特征的加权和
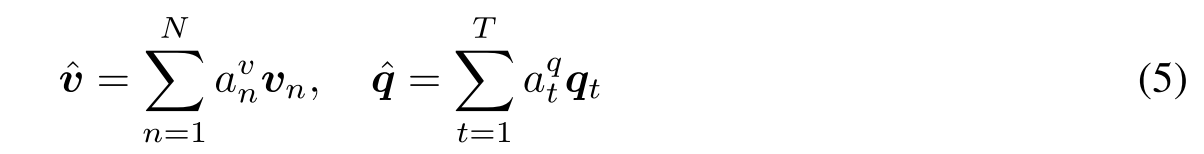
Alternating Co-Attention
在这种注意机制中,依次交替产生图像和问题注意。简而言之,这包括三个步骤:1)将问题总结成一个向量q;2)基于问题q得到图像的注意力;3)基于关注的图像特征得到问题的注意力。
定义一个注意力操作,将图像特征(问题特征)
和从问题(图像)表示中提取的引导注意力
作为输入,得到想要的图像(问题)向量。

其中1是一个所有元素都是1的向量, ,
是参数,
是特征X的注意力权重,在交替注意的第一步,
,第二步时,
,这时的引导注意力
是第一步
的中间参与问题特征,最后,使用了图像特征
为导向来得到问题。
。
3.4 Encoding for Predicting Answers
我们把VQA当作一项分类任务。我们根据共同参与的图像和问题特征从所有三个层面预测答案。我们使用多层感知器(MLP)递归编码注意特征。

4 Experiment



在COCO-QA数据集上可视化图像和问题共同关注图。从左到右:原始图像和问题对、单词级共同注意图、短语级共同注意图和问题级共同注意图。对于可视化,图像和问题关注都是按比例的(从红色:高到蓝色:低)。
















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









