







python爬虫实例-爬取壁纸网站
很多人认为爬虫是一个很高大上的东西,实际上他并没有想象中那么神秘,今天我带大家写一个简单的爬虫–爬取一个壁纸网站,需要了解一些html和BeautifulSoup的知识。
代码仅供学习测试之用。
主要分为以下两步
1. 访问需要爬取的网站,分析需要爬取的资源
2. 代码的实现及测试
话不多说我们就开始动手吧!
一.分析需要爬取的资源
需要爬取的网站是一个壁纸分享网站:桌酷壁纸—http://www.zhuoku.com
打开这个网站,再随便打开一个图片,发现图片非常高清但是广告非常烦人有木有!这就是我们选择这个网站来爬取的原因,以后妈妈再也不用担心我下载壁纸遇到这么多烦人的广告了。
接下来我们来分析一下如何获得这些图片
我们在左侧的桌酷最新壁纸下面点击下一页


然后我们发现网址变成了http://www.zhuoku.com/new/index.html
再点击下一页,网址变成了http://www.zhuoku.com/new/index_2.html
这里一共有220页,可是211页之后的页面打开就回到了首页http://www.zhuoku.com
然后我们看一下第一页,右键点击“检查”或者“审查元素”,我们看到,每一个系列的名字和图片页可以在这里得到。
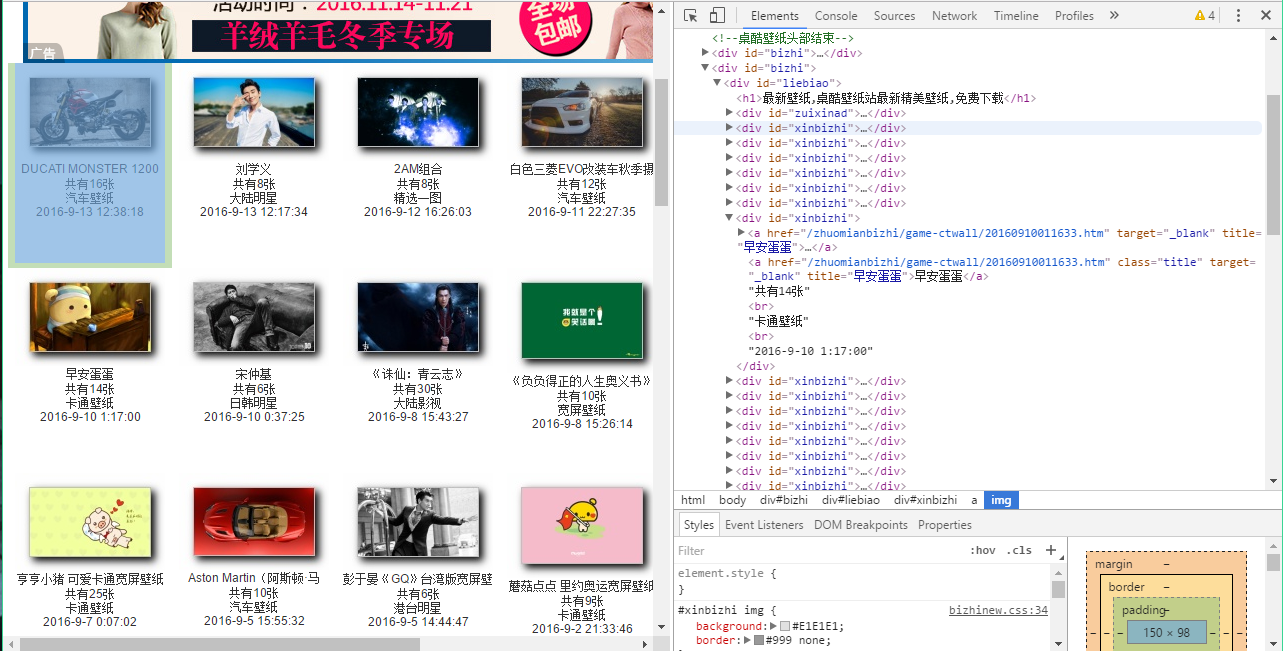
每一个套图的一个id为xinbizhi的div里,网址是http://www.zhuoku.com加上div下的a的 href,名字在 a下的title里。

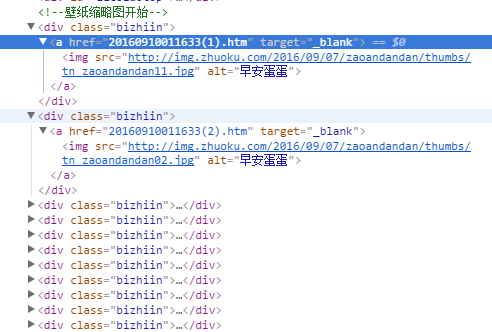
接着我们进入网址,再次审查元素,发现每一张图片的网址就是在上面的网址后面加(n),n是指第n张图片,不要被下面的src骗了,那个是缩略图的网址:)。那么这个n去哪里找呢,没错,看上一个审查元素的div中用<br>分开之后的第一个字符串中的数字就是我们要的n。
二.四个函数的书写
博主没有拿写过的爬虫来写教程,而是一边写博客一边写代码,让大家能明白写爬虫的思路。
1.首先我们先把执行的主函数写好,将实现功能的函数定义好,接着再补充代码,记得导入能够用到的模块。
import urllib.request as u
import os
from bs4 import BeautifulSoup
def save_pic(pics):
#保存图片
pass
def url_open(url):
#得到并返回网页
pass
def main():
#先只下载第一页的壁纸
url = 'http://www.zhuoku.com/new/index.html'
html = url_open(url)
#for 每个div id = xinbizhi
#使用BeautifulSoup来得到需要的信息
#title =
#num =
pics = []
for i in rang(num):
pic_url = urls.split('.')[0] + '(%d)'%i + urls.split( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2924
2924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









