







明确爬取图片步骤
1. 确定网站的user-agent
进入网站右键点击 检查,可看到如下界面:
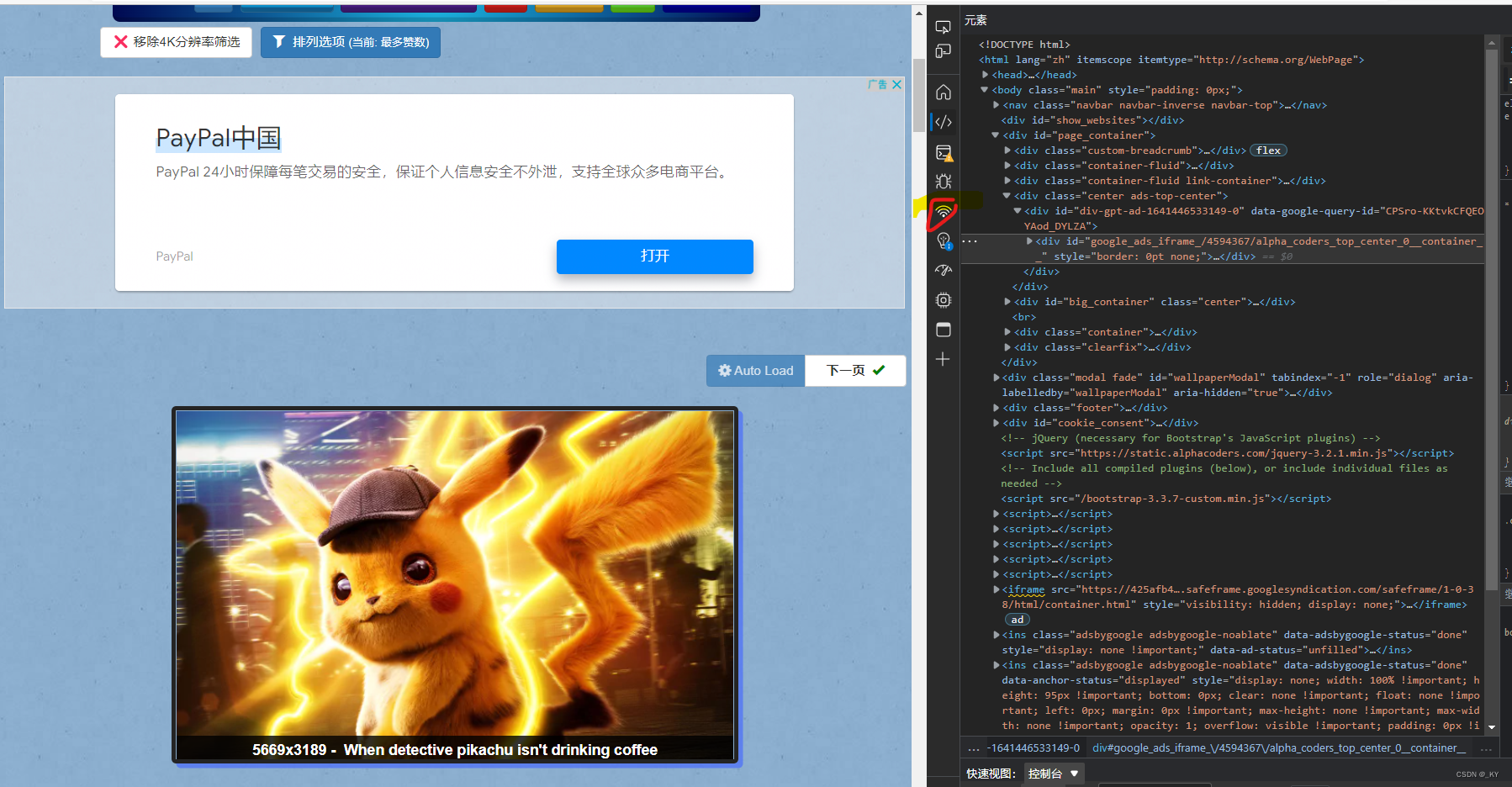
点击小wifi图标,最下面的user-agent即设为headers
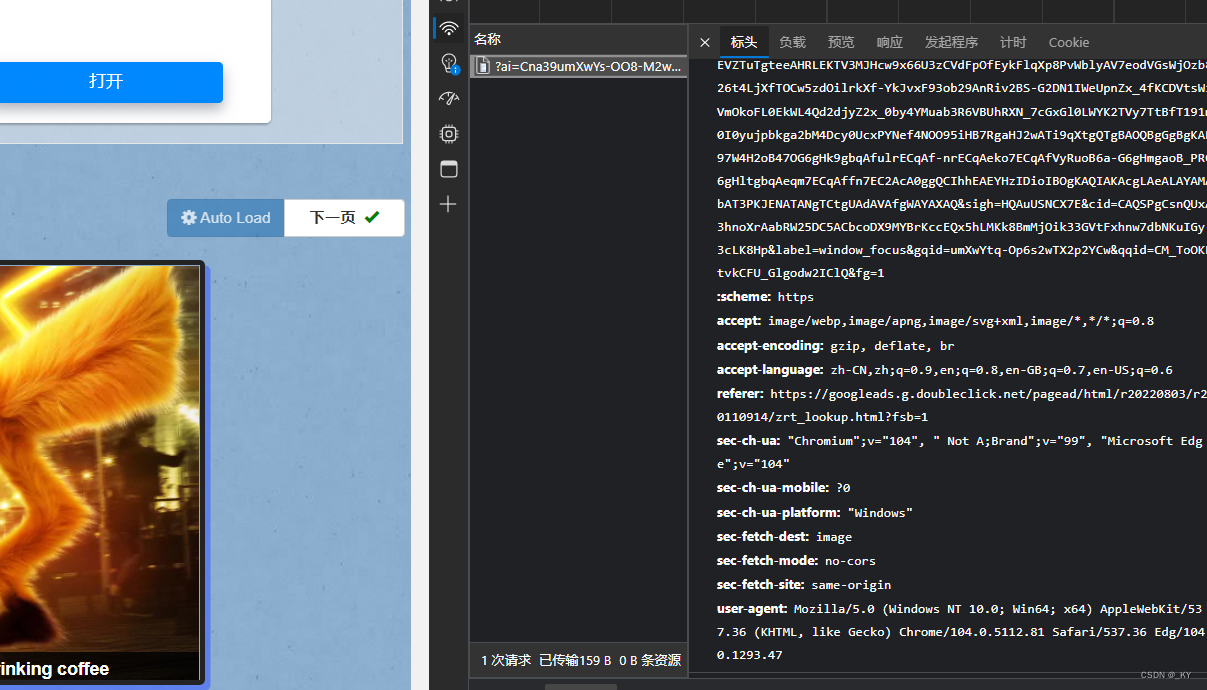 2. 查看网站源码
2. 查看网站源码
找出图片所对应的代码块
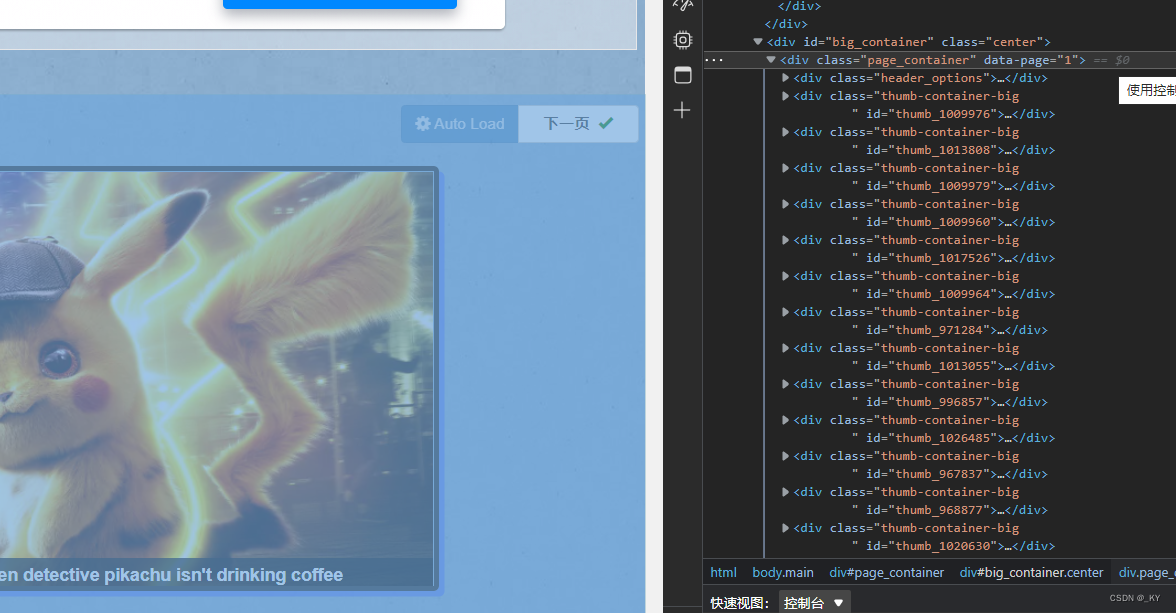
即对应一个div列表,此时发现高清图地址位于a标签的href属性值中,所以需获取高清图地址
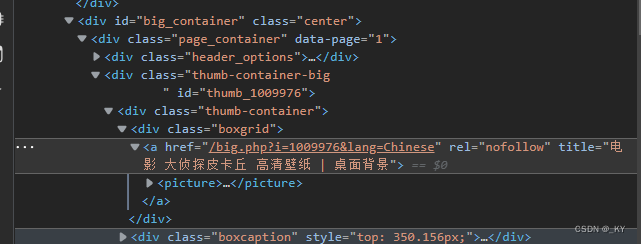
继而在高清图页面进行源码分析
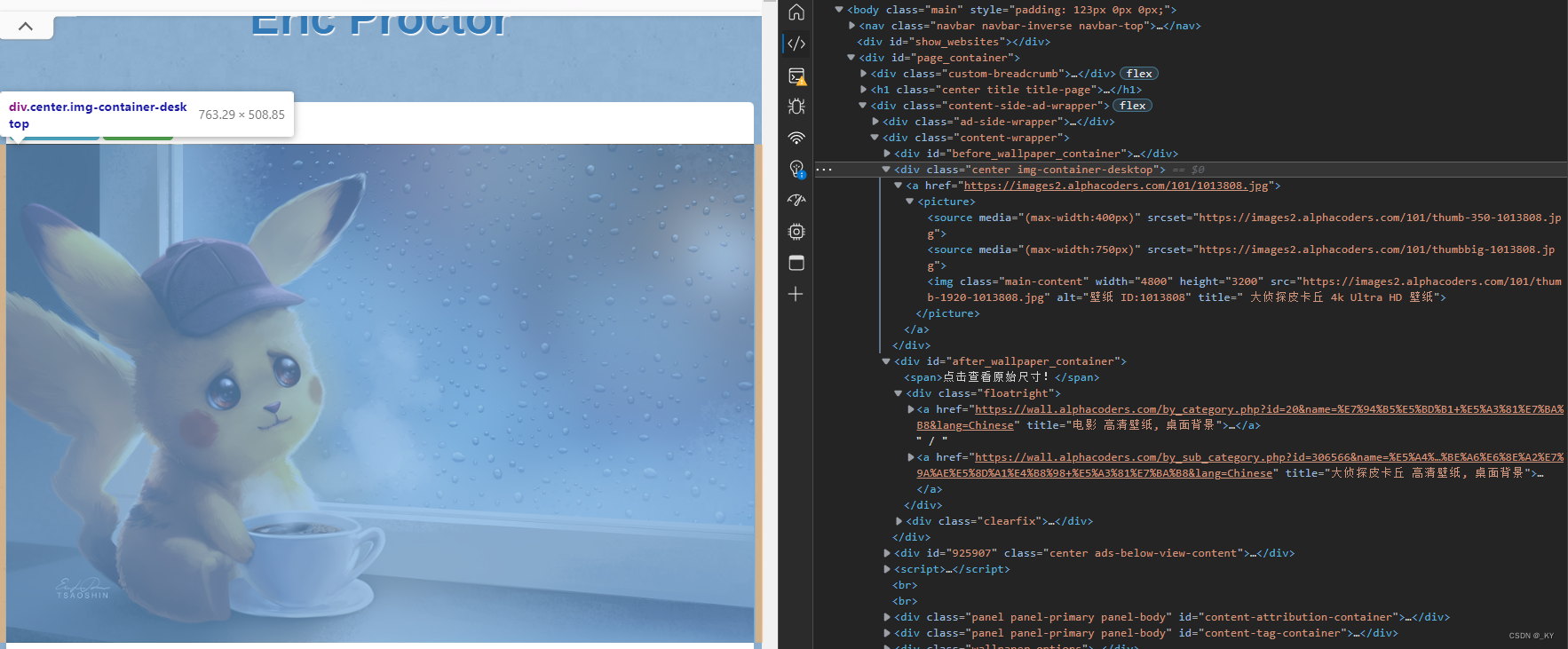 发现地址位于a标签的href的属性中,所以我们利用xpath提取出高清图地址后在该页面进行xpath操作获取下载地址即可保存图片。
发现地址位于a标签的href的属性中,所以我们利用xpath提取出高清图地址后在该页面进行xpath操作获取下载地址即可保存图片。
源码如下:
import requests
import os
from lxml import etree
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'}
def di_zhi():
list_suo = []
for i in range(1, 11):
if i > 1:
url = f'https://wall.alphacoders.com/by_sub_category.php?id=306566&name=%E5%A4%A7%E4%BE%A6%E6%8E%A2%E7%9A%AE%E5%8D%A1%E4%B8%98+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese/index_{i}.html'
else:
url = 'https://wall.alphacoders.com/by_sub_category.php?id=306566&name=%E5%A4%A7%E4%BE%A6%E6%8E%A2%E7%9A%AE%E5%8D%A1%E4%B8%98+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese/index.html'
response_text = requests.get(url, headers=headers, timeout=30).text
tree = etree.HTML(response_text)
# 提取出高清图所在页面地址
r = tree.xpath('//div[@class="page_container"]/div/div/div/a/@href')
for j in r:
list_suo.append(j)
# print(list_suo)
return list_suo
def gao_qing(kang):
img_name = 0
if not os.path.exists('./pikapi'):
os.mkdir('./pikapi')
for i in kang:
url = "https://wall.alphacoders.com" + i
response = requests.get(url=url, headers=headers, timeout=15)
response.encoding = 'gbk'
response_text = response.text
tree = etree.HTML(response_text)
img_src = tree.xpath('//div[@class="center img-container-desktop"]/a/@href')[0]
#print(img_src)
#print(img_name)
# 获取图片二进制数据
img_content = requests.get(img_src, headers=headers, timeout=30).content
img_path = './pikapi/' + str(img_name) + '.jpg'
with open(img_path, 'wb') as f:
f.write(img_content)
print(img_src + str(img_name) + '.jpg下载完毕')
#print(img_name)
img_name = img_name + 1
print("pikapi全部下载完毕!")
def main():
k = di_zhi()
gao_qing(k)
if __name__ == '__main__':
main()
之前爬取的时候出现了由于爬取过快而被禁掉IP的问题,所以在这把 timeout调大一点
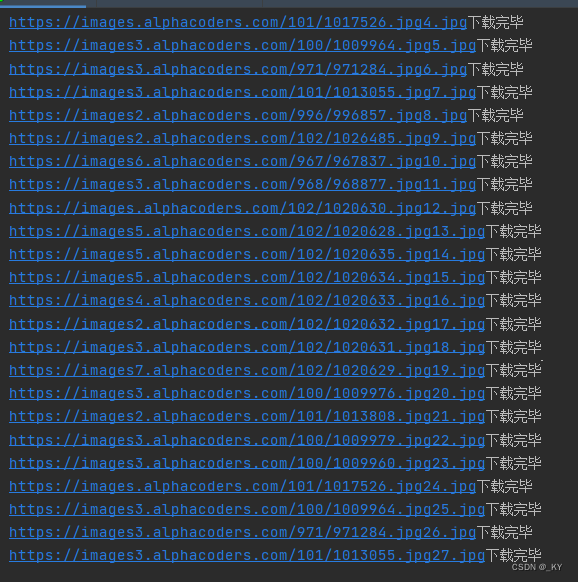
可见图片已经保存在指定的目录下咯
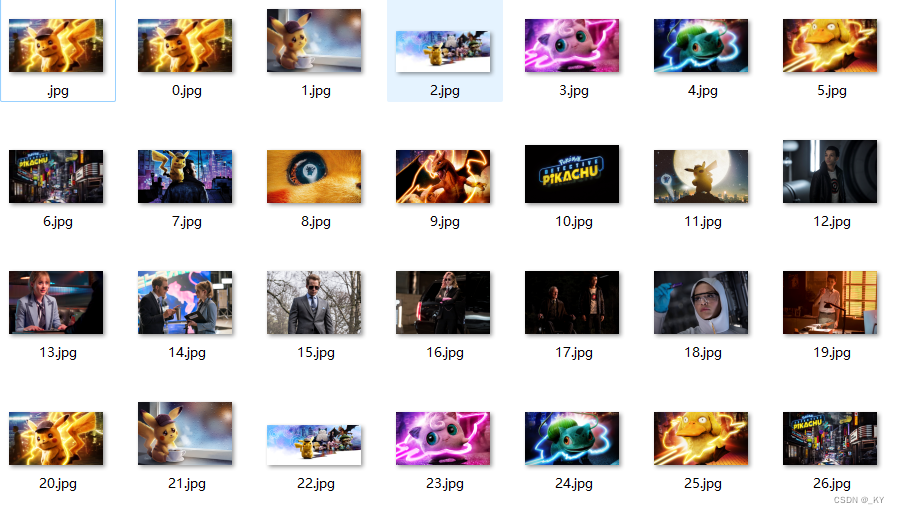
我发现之前爬的网站页面照片只有二十张(这样会有重复),所以换个页面爬取(方法和之前一样):
import requests
import os
from lxml import etree
headers = {'User-Agent': 'https://wall.alphacoders.com/by_collection.php?id=81&lang=Chinese'}
def di_zhi():
list_suo = []
for i in range(1, 11):
if i > 1:
url = f'https://wall.alphacoders.com/by_collection.php?id=81&lang=Chinese/index_{i}.html'
else:
url = 'https://wall.alphacoders.com/by_collection.php?id=81&lang=Chinese/index.html'
response_text = requests.get(url, headers=headers, timeout=30).text
tree = etree.HTML(response_text)
# 提取出高清图所在页面地址
r = tree.xpath('//div[@class="page_container"]/div/div/div/a/@href')
for j in r:
list_suo.append(j)
# print(list_suo)
return list_suo
def gao_qing(kang):
img_name = 0
if not os.path.exists('./pikapi2'):
os.mkdir('./pikapi2')
for i in kang:
url = "https://wall.alphacoders.com" + i
response = requests.get(url=url, headers=headers, timeout=15)
response.encoding = 'gbk'
response_text = response.text
tree = etree.HTML(response_text)
img_src = tree.xpath('//div[@class="center img-container-desktop"]/a/@href')[0]
#print(img_src)
#print(img_name)
# 获取图片二进制数据
img_content = requests.get(img_src, headers=headers, timeout=30).content
img_path = './pikapi2/' + str(img_name) + '.jpg'
with open(img_path, 'wb') as f:
f.write(img_content)
print(img_src + str(img_name) + '.jpg下载完毕')
#print(img_name)
img_name = img_name + 1
print("pikapi全部下载完毕!")
def main():
k = di_zhi()
gao_qing(k)
if __name__ == '__main__':
main()
不得不说,皮神是真的可爱
















 8556
8556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









