







1.Redis基本数据类型
文章涉及源码均基于6.0.8
1.1 概览
redis基本数据类型有如下5种:
| 类型 | 底层数据结构 |
|---|---|
| String | 简单动态字符串 |
| Hash | 哈希表、压缩列表 |
| List | quicklist(3.2之前双向链表、压缩列表 ) |
| Set | 整数数组、哈希表 |
| Sorted Set | 跳表、压缩列表 |
不同类型时间复杂度:
| 类型 | 时间复杂度 |
|---|---|
| Hash | O(1) |
| 跳表 | O(logN) |
| 双向链表 | O(N) |
| 压缩列表 | O(N) |
| 数组 | O(1) 1 |
1.2 SDS结构
String内部有三种编码方式,本质上是char[]类型,用object encoding [keyName]可以查看具体类型:
- int,存储8字节的长整型(long)
- embstr,小于44个字节的字符串
- raw,大于44字节字符串
【总结】
int升级ebmtr:int如果改成了string,或者int超过了2^64;
embtr升级为raw:分配的大小超过44字节,或者修改embstr(因为embstr是只读的)
升级不可逆,除非重新set
1.3 Hash
存储的是无序键值对,最大存储2^32-1个
下图展示了hash应用层面的结构:
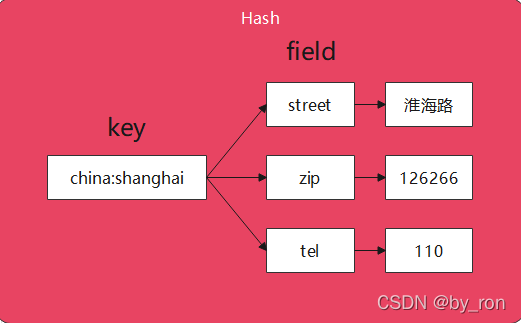
实际上,在redis中Hash代码组织结构如下:
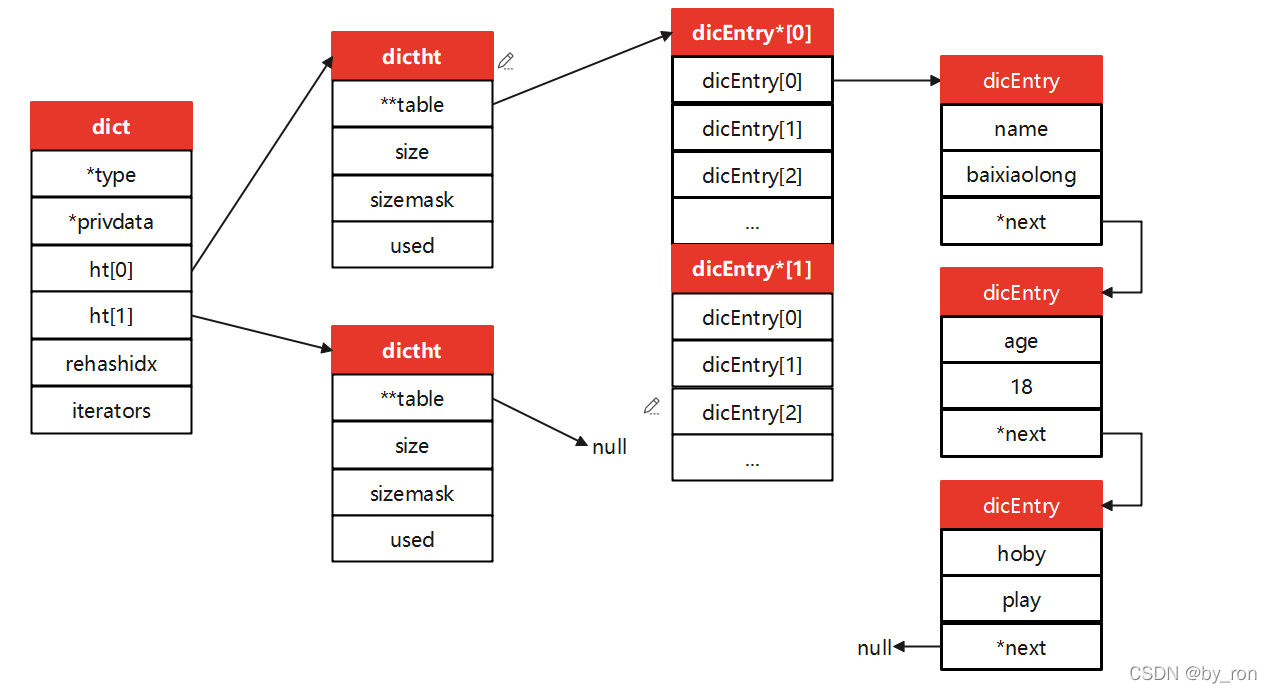
其中,dict字典中保留了两个ht,一个用作扩容;
ht中存了一个table二维数组,也称作hash桶,桶中存放着dicEntry;
最后才是真正存放数据的地方dicEntry,包含field和value,并且通过next指针指向下一个entry.
和string对比
- string是使用key分层来处理同一组数据,相比之下,hash更加节省内存;
- string需要通过mget来获取同一组数据,hash一个key就搞定,效率快;
- hash不能针对单个field设置过期时间,没有string灵活;
- hash既然一个key可以存储多个filed,那么显然容易导致big key
1.4 压缩列表
压缩列表实际上就是一个数组,只是数组的头3个字段分别保存的是zlBytes(列表占用字节数)、zltail(列表尾部偏移量)、zllen(数组entry个数),其余数组中每个item都保存一个entry。所以头尾查找比较高效。
- ziplist结构

- ziplist中entry结构:

通过entry结构可以看出,实际上通过存储pre_entry_length2,间接性保留了指向前一个entry的指针,因为通过当前指针往前偏移这个长度后就回到了前一个entry的头部。
也说明ziplist支持从尾部往前查找。
1.5 quicklist
quicklist是redis3.2版本之后新增的数据结构,实则是双向链表和压缩列表的结合体
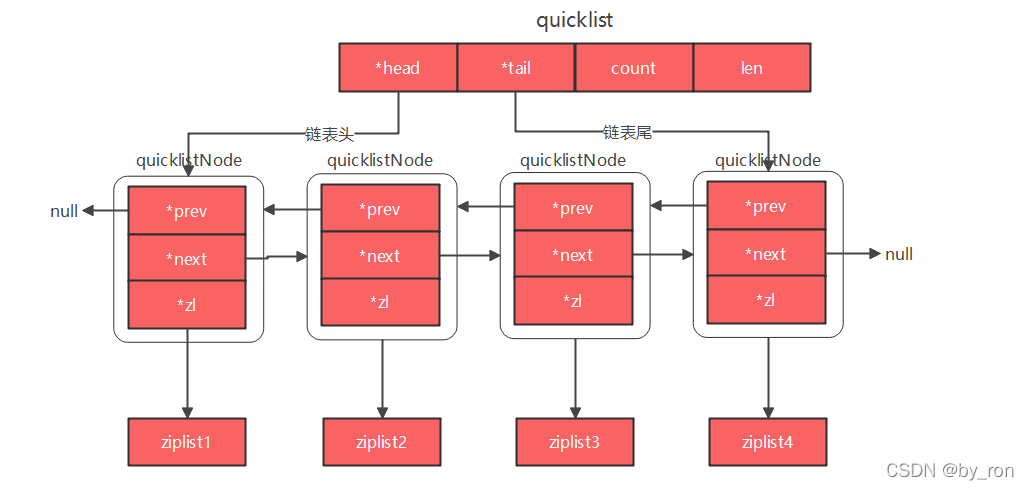
6.0.8源码如下:
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* 所有压缩列表中entry的总数之和 */
unsigned long len; /* quicklistNodes总数 */
int fill : QL_FILL_BITS; /* 装填因子:nodes上限,配置list-max-ziplist-size默认-2,表示8kb */
unsigned int compress : QL_COMP_BITS; /* 压缩深度,默认0,N代表对首尾N个entry不压缩,比如1表示entry1和entryN不压缩,依次类推 */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];/* 可选,重新分配内存时使用 */
} quicklist;
1.6 intset
set中如果存的是数字类型,底层数组用的是intset结构,配置默认512
set-max-intset-entries 512
可知,如果非数字或者数组大小超过设置的512个,就转换为hash结构。
1.7 跳表
1.7.1 结构
跳表就是在链表的基础上,增加了多级索引,通过索引位置跳转实现数据快速定位,时间复杂度O(logN)。注意前提条件是链表有序。
比如获取56只需要3次即可定位到目标数据3:

源码中的定义
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; /* 元素 */
double score; /* 分值 */
struct zskiplistNode *backward; /* 后退指针*/
struct zskiplistLevel {
struct zskiplistNode *forward; /* 前进指针*/
unsigned long span; /* 后退指针*/
} level[]; /* List<zskiplistNode> level */
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict; /* hash结构,value->score */
zskiplist *zsl;
} zset;
1.7.2 深度
redis中跳表的深度是由随机算法生成的,最大不超过32
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned.
实现 随机level
*/
int zslRandomLevel(void) {
//初始level = 1
int level = 1;
//ZSKIPLIST_P=0.25 满足随机数<16383,level+1
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
//最终调整 不能大于 ZSKIPLIST_MAXLEVEL server.h中 默认 32 /* Should be enough for 2^64 elements */
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
1.8 转ziplist时机
- hash退化成为ziplist
– hash中field数量<512
– hash中所有filed和value都<64bytes - skiplist退化成ziplist
–元素数量<128
–所有元素长度<64bytes
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
2.Redis全局Hash
2.1 redis健值的存储结构
redis的k/v使用的是一张全局哈希表,每次根据key来做hash操作,定位到entry对象,注意这里entry中保存的不是value,而是key和value!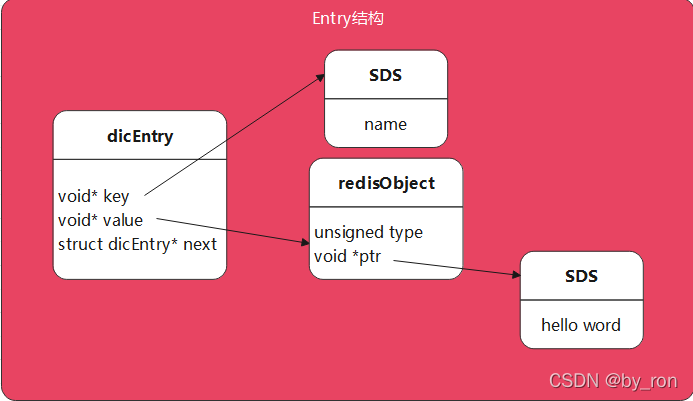
2.2 全局哈希表处理哈希冲突
使用链表处理哈希冲突,但是redis是采用追加的头结点的方式,也是为了速度考虑,因为新插入的数据被访问的频率一般来说比较高。
2.3 rehash的时机
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
(1)服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1 ;
(2)服务器目前正在执行BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5
负载因子 = 节点数 / 桶数
注意节点数是指所有的key的数量,而并非已使用桶的数量,所以是可以超过1或者5的的
2.4 BGSAVE和BGREWIRTEROF
BGSAVE:生成RDB快照时主线程fork出的子进程,用于生成RDB文件
BGREWIRTEROF:AOF日志重写时主线程fork出的子进程
2.5 rehash过程
为了使rehash更高效,redis默认使用两张hash表,开始只往hash1中写入,当需要扩容的时候(负载因子默认1,used / size),设置hash2容量 = hash1 * 2,然后把hash1中的数据rehash到hash2,最后释放hash1,hash1留作下次扩容时使用。
2.6 渐进式hash的过程
因为rehash由主线程来执行,如果数据量过大,会阻塞主线程。所以采用渐进式hash,将每次rehash的操作分摊到后续的读写请求里:即每次复制hash1一个桶中的entries到hash2中。
如果后续一直没有请求进来,redis会有一个后台任务来定时复制数据到hash2。
3. Redis备份
3.1 AOF日志
配置append-only 默认no,即不开启AOF,启用需要改为yes
刷盘策略appendfsync有以下三种配置:
| 策略 | 执行 | 优点 | 缺点 |
|---|---|---|---|
| always | 总是同步写 | 高可靠性 | 影响性能 |
| everysec(默认) | 每秒写 | 性能适中 | 宕机丢失1s数据 |
| no | 由操作系统控制写 | 高性能 | 宕机数据丢失不可控 |
AOF日志恢复比快照慢,因为AOF存的是执行命令。
3.2 快照备份
- redis默认使用bgsave命令来fork一个子线程来创建rdb快照文件。
- 写时复制(Copy-On-Write)技术,子线程共享父线程内存,只有父线程操作某个key的时候,对这个key的内存创建副本,大大节省了内存开销。
- 使用增量快照,在内存中记录两次快照间隔变更的数据,第二次快照只需要基于前一次快照更新变化的那部分数据。
- 快照频率太快,频繁fork子线程会阻塞主线程;频率慢,则宕机丢失的数据会比较多。
- redis4.0后支持aof+rdb快照的模式,两次快照之间的变更使用AOF日志,这样可以节省增量快照内存的开销,而且兼顾快照恢复快速的优势
3.3 混合模式
redis 4.0之后采用了AOF + RDB模式,在AOF重写的时候,会重写成RDB格式,这样一方面实现了AOF压缩,另外一方面又避免了AOF恢复数据慢的缺点,两全其美。
4. 内存回收
通过redis源码可以知道,含过期时间的key和永久key是分开存放到不同的dict中的
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure.
redis 统一维护的key
*/
typedef struct redisDb {
dict *dict; /* The keyspace for this DB 所有的 key 后面分类key */
//定期过期规则 expire.c 的 activeExpireCycle 方法
dict *expires; /* Timeout of keys with a timeout set 设置过期时间的key */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) 阻塞的key */
dict *ready_keys; /* Blocked keys that received a PUSH 可读的key */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS 监测的key */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
4.1 过期策略
4.1.1 惰性过期
过期后不作处理,删除操作延迟到下一次访问的时候,通过expireIfNeeded方法来执行清除。
int expireIfNeeded(redisDb *db, robj *key) {
//如果没过期 返回0
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave, instead of
* evicting the expired key from the database, we return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time. */
//如果配置有masterhost主节点,说明这里是从节点,那么不操作增删改 不然就主从不一致了
if (server.masterhost != NULL) return 1;
/* Delete the key */
server.stat_expiredkeys++;
//广播key过期事件给AOF日志和slave节点
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
//判断 是否有在进行定期过期 两个方法 一个异步,一个非异步
int retval = server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
if (retval) signalModifiedKey(NULL,db,key);
return retval;
}
4.1.2 定期过期
redis.config中 hz 10 表示每10s执行一次清理,不建议设置太大。
默认开启了动态dynamic-hz,当高并发内存消耗过快时redis会适当调大hz,低峰期空闲时又会调小,提供了一种弹性机制。
# By default "hz" is set to 10. Raising the value will use more CPU when
# Redis is idle, but at the same time will make Redis more responsive when
# there are many keys expiring at the same time, and timeouts may be
# handled with more precision.
#
# The range is between 1 and 500, however a value over 100 is usually not
# a good idea. Most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is required.
hz 10
# Normally it is useful to have an HZ value which is proportional to the
# number of clients connected. This is useful in order, for instance, to
# avoid too many clients are processed for each background task invocation
# in order to avoid latency spikes.
#
# Since the default HZ value by default is conservatively set to 10, Redis
# offers, and enables by default, the ability to use an adaptive HZ value
# which will temporary raise when there are many connected clients.
#
# When dynamic HZ is enabled, the actual configured HZ will be used
# as a baseline, but multiples of the configured HZ value will be actually
# used as needed once more clients are connected. In this way an idle
# instance will use very little CPU time while a busy instance will be
# more responsive.
dynamic-hz yes
那么,每10s执行一次,如何获取这些过期的key呢,总不可能全部key扫一遍吧,看下图:
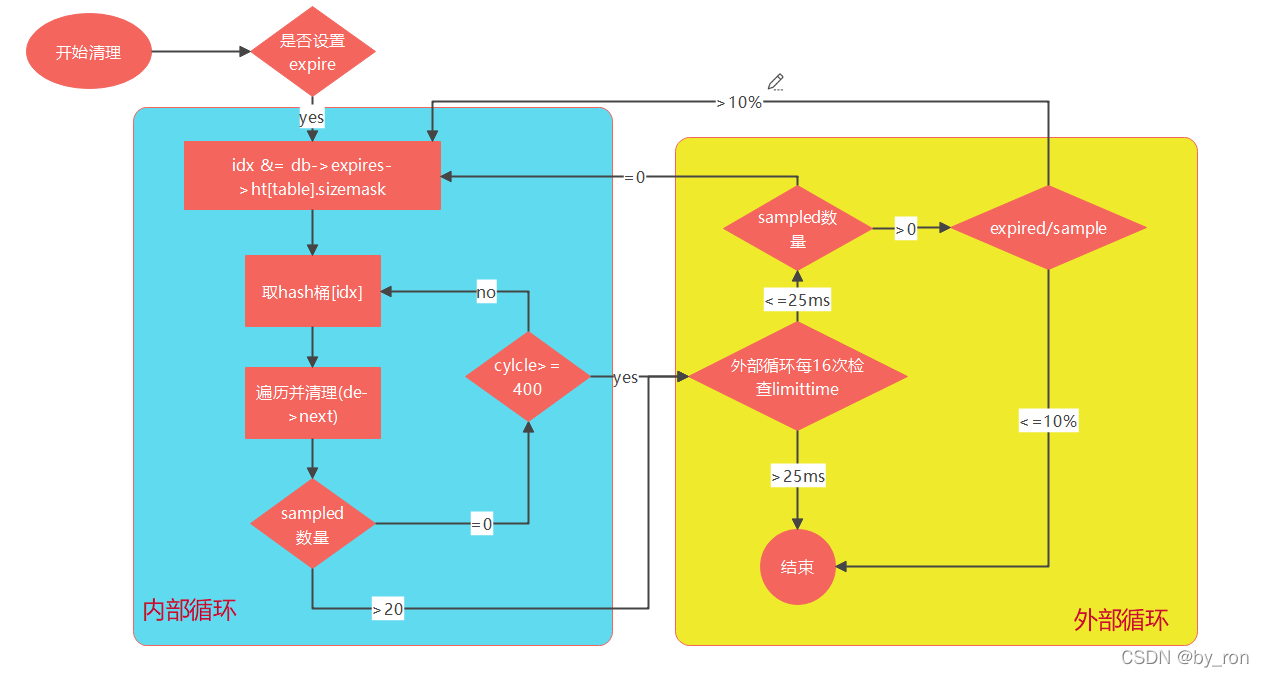
对应源码:
// 活跃过期周期
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
// active_expire_effort 来源于 config.c 配置 active-expire-effort 默认值 redis.conf 看到默认 1
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
// 20 + 20/4*0 还是20
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
//第三步 自循环条件值来源 10 - 0
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Last DB tested. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed. */
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit, unless the percentage of estimated stale keys is
* too high. Also never repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum; //配置文件config.c 配置 dbnum默认16 ,是从databases里面拿的 而databases是redis.conf 配置的
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
* time per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;//方法运行超时时间25*1000000/10/100=25000微秒,即25ms
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
//循环DB,可配,默认16 不是单独的库是所有的都会去过期
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
//do while 死循环
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
//如果没有过期key,循环下一个DB
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
//最多拿20个 config_keys_per_loop 这个往上可找到来源
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;//20*20= 400个桶
long checked_buckets = 0; //检查的hash桶数量
//如果拿到的key大于20 或者 循环的checked_buckets大于400,跳出
while (sampled < num && checked_buckets < max_buckets) {
//检查2个table的原因 ,扩容的时候两个hashtable里面都会有数据
for (int table = 0; table < 2; table++) {
//判断是否 table=1(第二个桶) 并且 没有在rehashing扩容中 说明第二个桶里面没有
//扩容中两个桶都会有数据,扩容之后会第二个桶置空
if (table == 1 && !dictIsRehashing(db->expires)) break;
// db->expires 设置了过期时间的
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
//根据index拿到hash桶
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
//循环hash桶里的key
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
//检查是否过期 第一步 和 第二步的 到此结束
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
//检查16次
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
// 自循 条件 第三步: sampled==0 表示没有拿到设置过期数据 ;config_cycle_acceptable_stale值往上
//过期的*100/拿到过期取样的数据 > 10 是不是超过了百分之10 就继续
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
- 首先会对16个db遍历,因为定期策略针对全部db
- 首先内层的while循环会根据桶的维度去清理过期key,通过masksize随机取桶的idx(idx &= db->expires->ht[table].sizemask本人不太确定是否随机)
- 每拿完一个桶,就去判断是否遍历了超过20个,没拿够就继续下个桶4
- 拿了400个桶后如果依然不够20个,有几个就算几个,直接跳外层循环
- 外层会判断2个极端情况:还是只拿到0个;清理的key超过总样本的10%,满足这两个条件就会接着2→3→4→5
- 外层每循环16次会检查一次执行时间是否>25ms,超时则跳出,否则接着奏乐接着舞
4.2 淘汰策略
当内存使用达到上限时,redis提供了8种淘汰策略:
| 策略 | 说明(volatile是只淘汰设置了expire的key) |
|---|---|
| lru | volatile-lru和allkeys-lru,最近最少使用的优先淘汰 |
| lfu | volatile-lfu和allkeys-lfu:最少使用频率的优先淘汰 |
| random | volatile-random 和allkeys-random:随机淘汰 |
| volatile-ttl | 优先淘汰key快过期的数据 |
| noeviction | 默认noeviction,也就是达到最大内存后写入抛错,依然可读。 |
这里主要分析一下LRU和LFU
4.2.1 LRU
- 首先,redisObject中保留了24位lru时间戳,记录着每个key最近一次的访问时间
- 当需要淘汰的时候会筛选出N个(maxmemory-samples默认5)候选数据进入候选集合pool,pool大小16,根据下面源码计算对象空闲时间idle
- 只有idle大于pool中最小idle时才允许插入,这时就会淘汰头部idle最大的数据
- 通过这种近似LRU的算法,而不是采用hash+doubleLink,极大节省了内存,而且samples调整为10的时候几乎接近真实LRU
/* Given an object returns the min number of milliseconds the object was never
1. requested, using an approximated LRU algorithm. */
//LRU 计算对象的空闲时间
unsigned long long estimateObjectIdleTime(robj *o) {
//获取系统秒单位时间的最后24位
unsigned long long lruclock = LRU_CLOCK();
//因为只有24位,所有最大的值为2的24次方-1,194天
//超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小
//如果当前秒单位大于等于redisObject对象的LRU的话
if (lruclock >= o->lru) {
//如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位ms
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
//lruclock已经预生成
} else {
//否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到lru的值越小,表明越早被访问,则相减值越大越容易被淘汰
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}
4.2.2 LFU
采用LFU的时候,lru的高16位存访问时间戳,单位min;低8位存储访问的频次,上限255。
counter++的源码,在key被访问时调用:
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255.
增加访问次数方法
*/
uint8_t LFULogIncr(uint8_t counter) {
//如果已经到最大值255,返回255 ,8位的最大值
if (counter == 255) return 255;
//得到随机数(0-1)
double r = (double)rand()/RAND_MAX;
//LFU_INIT_VAL表示基数值,默认为5(在server.h配置) 防止刚加入就被干掉
double baseval = counter - LFU_INIT_VAL;
//如果当前counter小于基数,那么p=1,100%加
if (baseval < 0) baseval = 0;
//不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关
//都是在分母,所以2个值越大,加counter几率越小,越大加的几率越小(所以刚才的255够不够的问题解决)
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++; //p越小,几率也就越小
return counter;
}
lfu-log-factor默认10,计算逻辑如下:
- 取0~1之间的随机数r
- 用当前counter - 5得到baseval
- 计算p = 1 / (baseval*lfu_log_factor + 1),显然lfu_log_factor 越大,p就越小,从而越不容易增长
- 如果r < p则counter++
其中,factor的数值对应可访问次数通过redis-benchmark测试结论见下表:
| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
|---|---|---|---|---|---|
| 0 | 104 | 255 | 255 | 255 | 255 |
| 1 | 18 | 49 | 255 | 255 | 255 |
| 10 (默认) | 10 | 18 | 142 | 255 | 255 |
| 100 | 8 | 11 | 49 | 143 | 255 |
counter–的源码,和LRU类似,在计算idle时调用:
/* If the object decrement time is reached decrement the LFU counter but
* do not update LFU fields of the object, we update the access time
* and counter in an explicit way when the object is really accessed.
* And we will times halve the counter according to the times of
* elapsed time than server.lfu_decay_time.
* Return the object frequency counter.
*
* This function is used in order to scan the dataset for the best object
* to fit: as we check for the candidate, we incrementally decrement the
* counter of the scanned objects if needed. */
unsigned long LFUDecrAndReturn(robj *o) {
//object.lru字段右移8位,得到前面16位的时间 (上次衰减时间)
unsigned long ldt = o->lru >> 8;
//lru字段与255进行 &与 运算(255代表8位的最大值),得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了 lfu_decay_time,用 LFUTimeElapsed(ldt) 除以配置的值
//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
//默认得到的就是 一分钟减少一次
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能减少为负数,非负数用couter值减去衰减值
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
lfu-decay-time默认1:LFUTimeElapsed(ldt)得到当前时间与上次访问时间的差,即多少min未访问,也就是默认1min衰减1次。
淘汰和LRU共用一套策略,调用LFUDecrAndReturn返回的counter被用作idle加入到候选集,参考LRU,不再赘述。
5. 主从复制
-
采用读写分离
-
从库使用如下命令和主库建立主从关系
relicaof 主库ip 端口 -
主从首次全量复制流程
-
从库发送psync ? -1命令给主库,表示需要同步;
-
主库回复FULLRESYNC + runId + offSet给从库,确认ok;
-
主库发送RDB文件给从库;
-
主库发送新写命令repl_buffer给从库。
runId-redis实例的唯一id
offSet-同步偏移量
-
-
主从断链恢复后复制流程
-
主从断连后,主库会把断连期间的操作命令写入一个环形缓冲区repli_backlog_buffer;
-
repli_backlog_buffer包含两个偏移量maste_repl_offset和slave_repl_offset,初始位置重合;
-
随着主库不断地写入或者更新,maste_repl_offset会不断增加;
-
恢复连接后,从库发送命令
psync 主库runId slave_repl_offset -
主库把断连期间的数据发送到repli_buffer
-
从库同步后更新slave_repl_offset,跳回d步骤,直至主从偏移量重合。
-
6. 哨兵sentinel
哨兵有两个作用:监控和选主,适用于主从,而redis cluster选主并不依赖哨兵,而是每个master之间维持心跳进行选主。
- 监控是用于判断主库是否处于下线状态
- 选主是选择一个从库作为新的主库
监控使用哨兵集群,少数服从多数,和大多数选主算法一样,为了避免脑裂,N取奇数,当N/2 + 1个都判定主库主观下线,则主库就被客观下线。
选主是通过一定的规则:
- 剔除不健康从库,比如经常和主库断连,超过阈值10次的( 配置down-after-milliseconds * 10)
- 对剩余从库打分,选择top1作为主库,优先级如下:
-可以手动设置slave-priority,这样就会优先选择高优先级的从库
-选择同步偏移量最小的:min(master_repl_offset - slave_repl_offset)
-如果偏移量都是0,则选择从库实例ID最小的
这里其实存疑,因为根据下标确实O(1),但是根据值来查就是O(N) ↩︎
当前一个节点小于255bytes时,pre_entry_length只占用1个字节,超过255bytes时,pre_entry_length会扩大到5个字节,0xFF(1字节)
实际长度(4字节),如果此时当前节点占用253,那又会导致下个节点需要调整pre_entry_length,引发连锁反应。所以实战中我们尽量保持value大小不超过255字节。 ↩︎千万不要理解为3、7、48有2个node存储,实际源码中通过level[]来处理层级和指向的,node是不会重复创建的。 ↩︎
所以如果桶中数据超过20个也是会被清理的,而不是只取20个 ↩︎















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











