






开胃菜
一些基础的名词解释
BeanDefinition
BeanDefiniton是Spring内部对Bean数据的抽象,一个Bean在Spring中的表现形式即为一个BeanDefiniton
BeanFactory
BeanFactory是Spring中容器的最基本形态,BeanFactory接口定义了一个容器最基本的功能
若我们对水桶进行抽象,最基本的水桶需要的功能就是可以装水,可以有一个把手供我们提起,BeanFactory就类似这个水桶的定义
FactoryBean
FactoryBean很容易和BeanFactory混淆,BeanFactory代表容器本身而FactoryBean代表容器中存储的Bean
也就是BeanFactory是水桶,FactoryBean是水桶中的水
ApplicationContext
ApplicationContext是Spring中容器的高级形态,在BeanFactory的基础上新增了很多功能
BeanFactory是水桶的定义,ApplicationContext就可是桶装水可以装水且拥有更高级的功能
DefaultListableBeanFactory
DefaultListableBeanFactory是Spring中对容器最基本的实现,它间接实现了BeanFactory接口
BeanFactory是水桶的规格参数定义了水桶是什么,DefaultListableBeanFactory就是个木桶,真正的产品
Ioc的流程介绍
测试类编写
编译项目的最后编写了一组简单的测试类,使用了ClassPathXmlApplicationContext类加载xml文件,很显然这个类属于ApplicationContext是一种高级的容器。这次我们用一种低级的方案来编写一组测试类
可以看到代码多了一些,简单分析一下这组代码
public class TestUserMessage {
@Test
public void TestDemo01() {
DefaultListableBeanFactory defaultListableBeanFactory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader xmlBeanDefinitionReader = new XmlBeanDefinitionReader(defaultListableBeanFactory);
xmlBeanDefinitionReader.loadBeanDefinitions(new ClassPathResource("ApplicationContext.xml"));
UserMessage jelly = defaultListableBeanFactory.getBean(UserMessage.class);
System.out.println(jelly);
}
}
- 首先使用DefaultListableBeanFactory的实例作为容器的基础实现,也就是水桶
- 新建XmlBeanDefinitionReader类将defaultListableBeanFactory绑定
- 使用XmlBeanDefinitionReader的实例读取xml配置文件,将加载的Bean(水)放入DefaultListableBeanFactory(水桶)
- 使用defaultListableBeanFactory的getBean方法从容器中获取Bean
执行测试类代码,查看结果,和之前相同
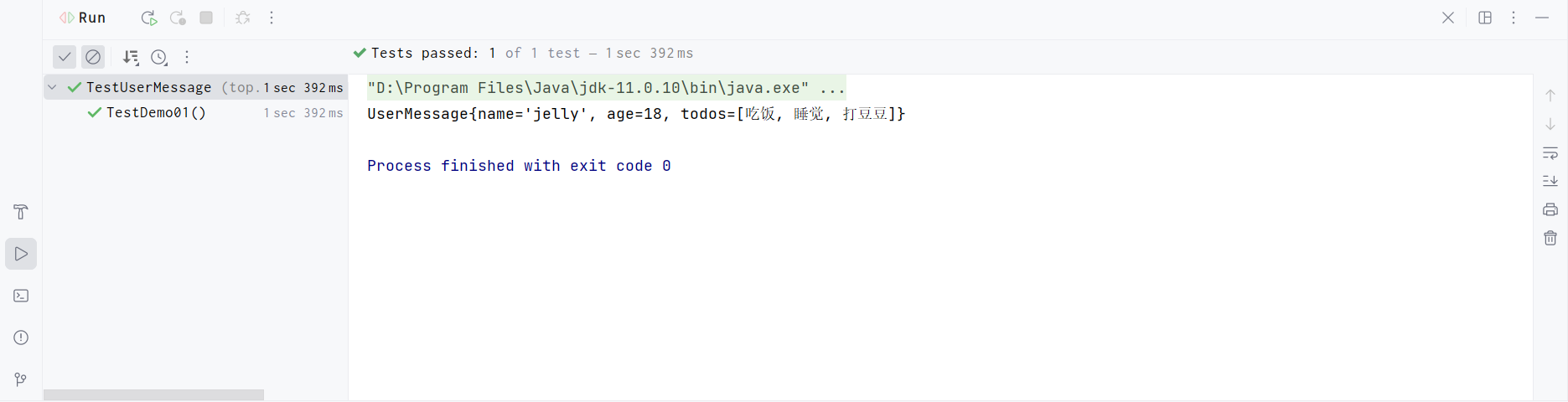
IOC的过程
根据上述的例子可以分析出,SpringIoc的过程大致分三个操作
- 资源的加载
- 资源的解析
- Bean的加载
首先资源的加载,指的是程序通过地址获取到配置文件或者其他资源,将其变为可被解析的类型,交给解析的程序进行解析
资源的解析,通过解析加载好的资源将其解析为BeanDefinition维护到容器当中
Bean的加载,通过容器的getBean方法去容器中查找Bean找到后返回,找不到就通过BeanDefinition创建
本篇就先来挑软柿子捏,介绍资源的定位和加载
ClassPathResource
ClassPathResource是Spring对资源的抽象,通过ClassPathResource可以更方便的操作资源
xmlBeanDefinitionReader.loadBeanDefinitions(new ClassPathResource("ApplicationContext.xml"));
梦开始的地方
Spring将从xml文件中读取BeanDefinition的功能委托给了XmlBeanDefinitionReader类,
进入XmlBeanDefinitionReader类的loadBeanDefinitions方法,本方法即为XmlBeanDefinitionReader读取BeanDefinition的入口方法
本方法的作用仅将Resource使用EncodedResource又包装了一层,通过名字也可以猜到大致含义,EncodedResource是一个带编码类型的资源抽象
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
进入重载的loadBeanDefinitions(EncodedResource encodedResource)方法,为了方便查找核心代码之后的代码片段会减除不重要的代码(断言、校验、异常处理等)
显然的逻辑还在下层方法doLoadBeanDefinitions中,Spring的一个方法命名习惯是:正常的方法名一般用来做数据校验等非实质性工作,实际进行操作的方法一般以do开头
例如这里的:loadBeanDefinitions做了一些数据有效性的校验,doLoadBeanDefinitions才是真正加载BeanDefinition的地方
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
// ...
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// doLoadBeanDefinitions是加载BeanDefinition的入口
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
// ...
}
进入doLoadBeanDefinitions方法,开头这两个方法就很重量级了,doLoadDocument方法就是资源加载的入口了,registerBeanDefinitions是资源解析的入口。本章节先解析doLoadDocument方法至于资源的解析就留给下章节,记住这个位置的代码,下章的开头要用
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 读取Document的操作通过doLoadDocument方法来执行
Document doc = doLoadDocument(inputSource, resource);
// 注册BeanDefinition方法
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
// ...
}
进入doLoadDocument方法,本方法其实还是存在于XmlBeanDefinitionReader类中,在方法中可以看到读取Document的操作是交给了本类的状态documentLoader来做的,这个状态初始化的值是一个实现了DocumentLoader接口的类DefaultDocumentLoader的实例,在前往DefaultDocumentLoader类前我们先解析一下传入loadDocument方法的4个参数的含义
// ...
private DocumentLoader documentLoader = new DefaultDocumentLoader();
// ...
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
- inputSource,资源本身不用多做解释
- getEntityResolver()方法,下面小节单独解读
- getValidationModeForResource()方法,下面小节单独解读
- isNamespaceAware()方法,namespaceAware在xml中指的是对命名空间的感知,该方法取得是当前类的namespaceAware状态,关于命名空间感知的相关问题,可以查阅《Java核心技术第二卷第三章 3.5节》
GetEntityResolver() 方法
getEntityResolver方法会返回EntityResolver接口的实例,EntityResolver接口用于提供一个查找验证文件的方案,先看一下getEntityResolver方法
通常情况下xml的验证文件需要从网络流中获取,网络首先会有延迟,而且有些程序需要在无网络的情况下启动,为xml解析程序设置一个EntityResolver可以通过EntityResolver中的方法将验证文件指向本地文件,更多相关EntityResolver的知识可以查看《Java核心技术第二卷第三章 3.3.1节》
此处咱们先忽略resourceLoader对该方法的影响,观察ResourceEntityResolver和DelegatingEntityResolver,就能发现ResourceEntityResolver继承了DelegatingEntityResolver,可以预见的是ResourceEntityResolver增强了某些功能,我们暂且不去理会增强了啥,先看DelegatingEntityResolver类做的事情
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}
DelegatingEntityResolver实现了EntityResolver接口,此接口是xml解析中规定的规范,上述一直提到的entityResolver实际上指的就是指实现了EntityResolver接口类的实例,EntityResolver接口只有一个方法resolveEntity,此方法规定了去哪里获取验证文件 可以看到spring将获取解析文件的工作交给了两个新的EntityResolver,分别是dtdResolver和schemaResolver它们两个都是EntityResolver的实例,从构造方法中可以看出两个状态实际类型分别是BeansDtdResolver和PluggableSchemaResolver 这里就不再贴代码分析这两个类了,简单的说下结论,对于DTD类型的验证文件,只会去根目录下找spring-beans.dtd这个文件,对于XSD类型的文件会去META-INF/spring.schemas文件中去查找配置的XSD文件位置,记住XSD文件查找的方法和位置,后面自定义标签解析时会用到
public class DelegatingEntityResolver implements EntityResolver {
// ..
public DelegatingEntityResolver(@Nullable ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}
@Override
@Nullable
public InputSource resolveEntity(@Nullable String publicId, @Nullable String systemId)
throws SAXException, IOException {
if (systemId != null) {
if (systemId.endsWith(DTD_SUFFIX)) {
// DTD 从这里解析
return this.dtdResolver.resolveEntity(publicId, systemId);
} else if (systemId.endsWith(XSD_SUFFIX)) {
// XSD 这里解析
return this.schemaResolver.resolveEntity(publicId, systemId);
}
}
// Fall back to the parser's default behavior.
return null;
}
// ...
}
getValidationModeForResource()方法
getValidationModeForResource方法的主要作用是判断xml验证模式,由于spring是支持DTD和XSD的验证模式的,需要根据两种验证模式做一些不同的处理,该方法就是判断验证模式为哪一种,直接进入方法 逻辑也比较简单,设置了就用设置的,没设置就自动判断,判断不出来就默认XSD
protected int getValidationModeForResource(Resource resource) {
int validationModeToUse = getValidationMode();
// 若设定了验证模式,则直接使用设定好的
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
// 未设定验证模式,自动判断
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// Hmm, we didn't get a clear indication... Let's assume XSD,
// since apparently no DTD declaration has been found up until
// detection stopped (before finding the document's root tag).
return VALIDATION_XSD;
}
接着跟入自动判断方法detectValidationMode看一眼,spring如何自动判断xml文档的验证模式。将解析文件判断验证模式的工作交给了validationModeDetector状态,该状态为XmlValidationModeDetector类的实例
protected int detectValidationMode(Resource resource){
// ...
return this.validationModeDetector.detectValidationMode(inputStream);
// ...
}
接着进入detectValidationMode方法,很清晰的结构,只要存在DTD的声明DOCTYPE就判断为DTD如果都不存在就判断为XSD,很简单粗暴的判断方式
public int detectValidationMode(InputStream inputStream) throws IOException {
this.inComment = false;
// Peek into the file to look for DOCTYPE.
try (BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream))) {
boolean isDtdValidated = false;
String content;
while ((content = reader.readLine()) != null) {
content = consumeCommentTokens(content);
// 读取到的行为注释跳过
if (!StringUtils.hasText(content)) {
continue;
}
// 只要有一行中包括DOCTYPE就能确定是DTD验证模式,反之则是XSD
if (hasDoctype(content)) {
isDtdValidated = true;
break;
}
if (hasOpeningTag(content)) {
// End of meaningful data...
break;
}
}
return (isDtdValidated ? VALIDATION_DTD : VALIDATION_XSD);
}
}
至此对loadDocument方法的入参就分析完毕,接下来就直接进入loadDocument方法当中一探究竟
神明陨落之处
上文说过loadDocument实际上调用的是DefaultDocumentLoader类的实例方法,使用createDocumentBuilderFactory构建DocumentBuilderFactory然后使用createDocumentBuilder构建DocumentBuilder,最后用DocumentBuilder解析资源
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
// 用生成的DocumentBuilder解析资源
return builder.parse(inputSource);
}
createDocumentBuilderFactory()方法
此方法我原称之为神陨落的地方,因为spring解析xml用了dom解析方案,在这里我们看到了最原始的代码 就好比核电站这种高级的发电方式,最终的电能转化方案也只能是烧开水;就算spring是神也得用最基础的xml解析方案,此处就是把spring拉入凡间的第一步 这里就用到入参传入的validationMode也就是验证模式,根据验证模式是否为VALIDATION_NONE来确定是否进行验证,比较有意思的是若验证模式为XSD会将命名空间感知强制设置为true
protected DocumentBuilderFactory createDocumentBuilderFactory(int validationMode, boolean namespaceAware)
throws ParserConfigurationException {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(namespaceAware);
if (validationMode != XmlValidationModeDetector.VALIDATION_NONE) {
factory.setValidating(true);
if (validationMode == XmlValidationModeDetector.VALIDATION_XSD) {
// Enforce namespace aware for XSD...
factory.setNamespaceAware(true);
try {
factory.setAttribute(SCHEMA_LANGUAGE_ATTRIBUTE, XSD_SCHEMA_LANGUAGE);
}
// catch ...
}
}
return factory;
}
createDocumentBuilder()方法
如果解析器或异常处理器不为空,也就是用户自己设置了,就会在这里设置给DocumentBuilder
protected DocumentBuilder createDocumentBuilder(DocumentBuilderFactory factory,
@Nullable EntityResolver entityResolver, @Nullable ErrorHandler errorHandler)
throws ParserConfigurationException {
DocumentBuilder docBuilder = factory.newDocumentBuilder();
if (entityResolver != null) {
docBuilder.setEntityResolver(entityResolver);
}
if (errorHandler != null) {
docBuilder.setErrorHandler(errorHandler);
}
return docBuilder;
}
至此对于资源的加载就结束了,我们已经拿到了配置文件的Document,接下来就会回到doLoadBeanDefinitions方法当中,研究它当中第二个方法registerBeanDefinitions,也就是解析xml注册BeanDefinition。















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









