









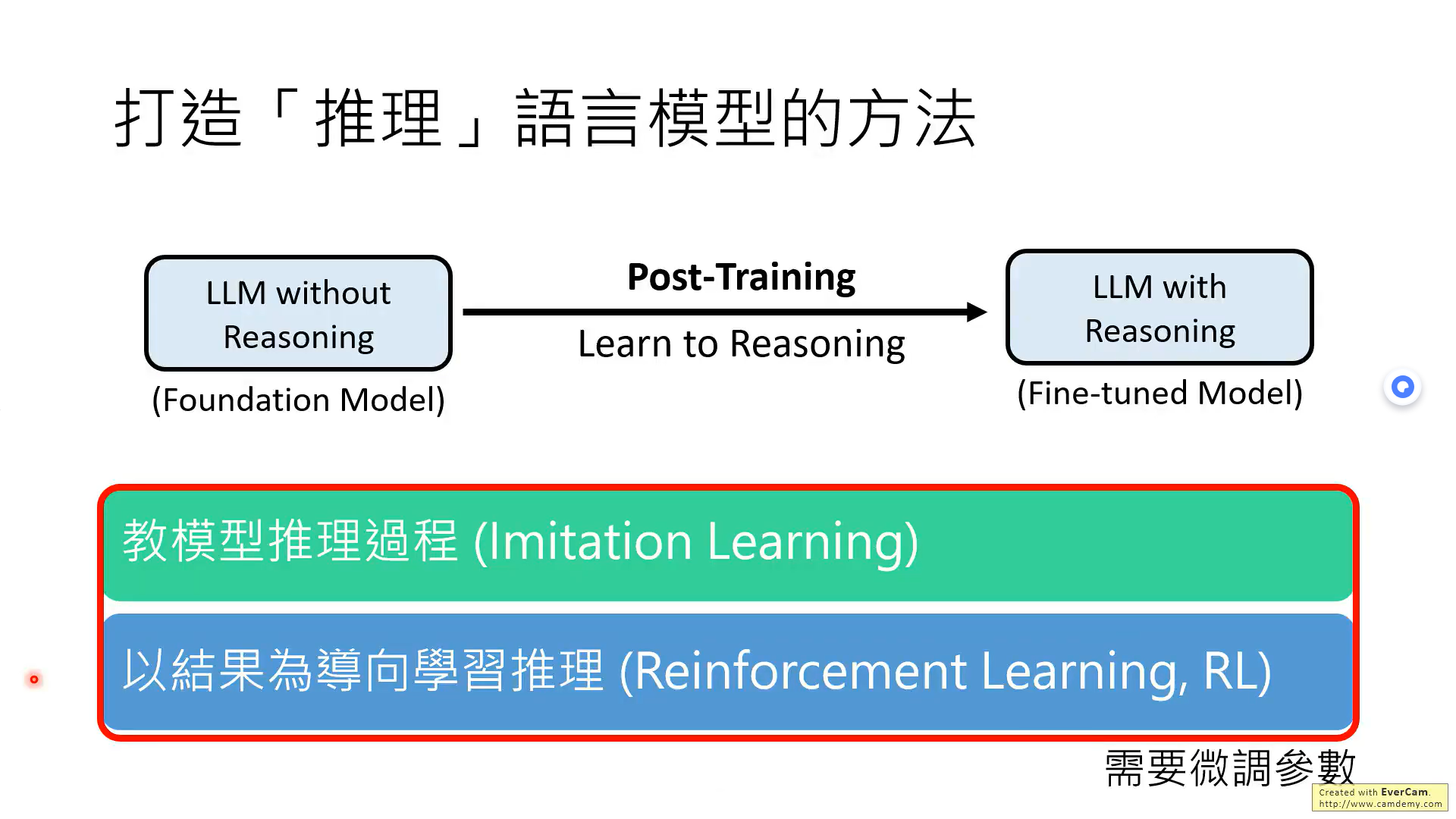
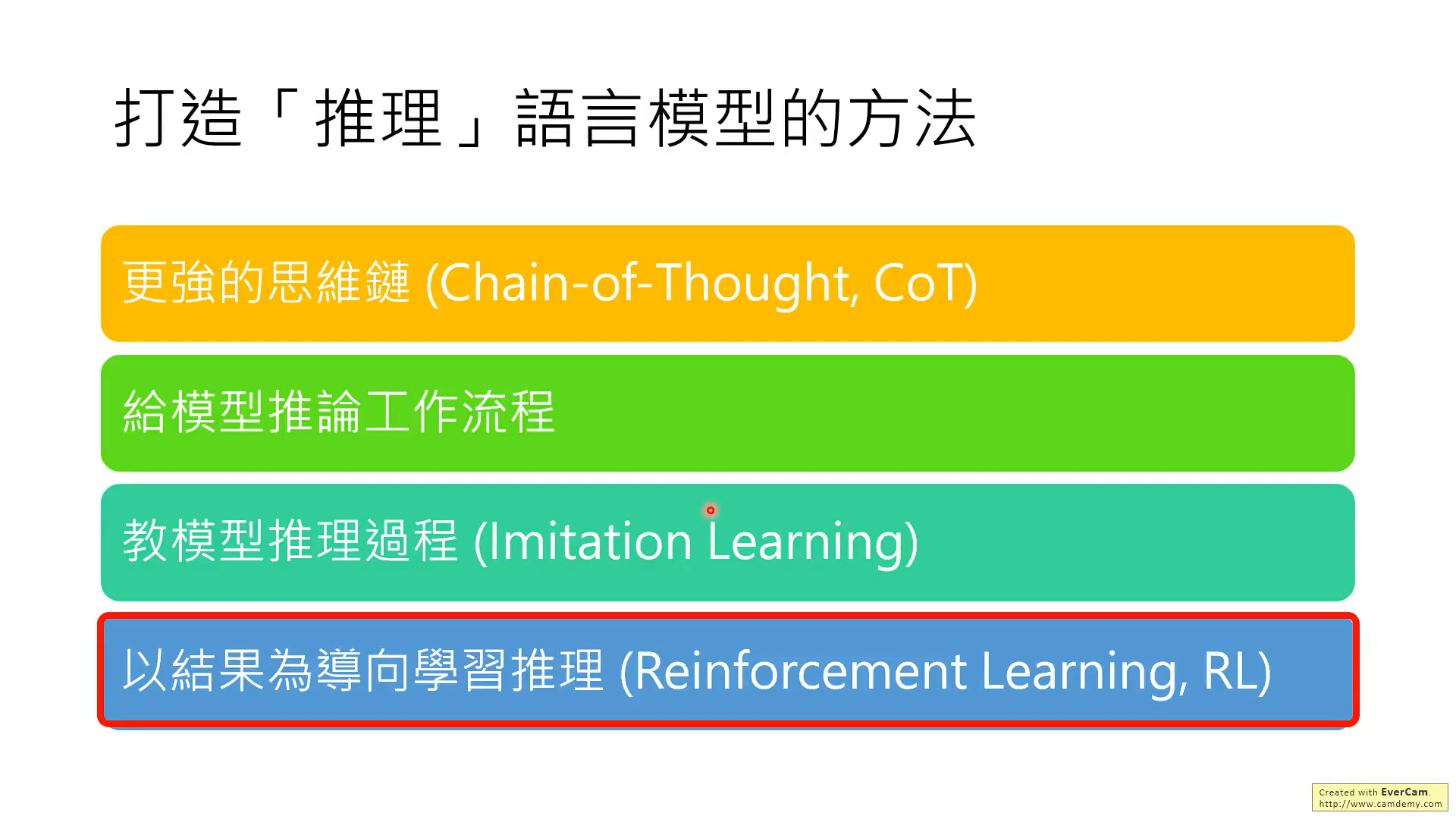
针对推理模型,主要讲了四种方法,两种不需要训练模型,两种需要。

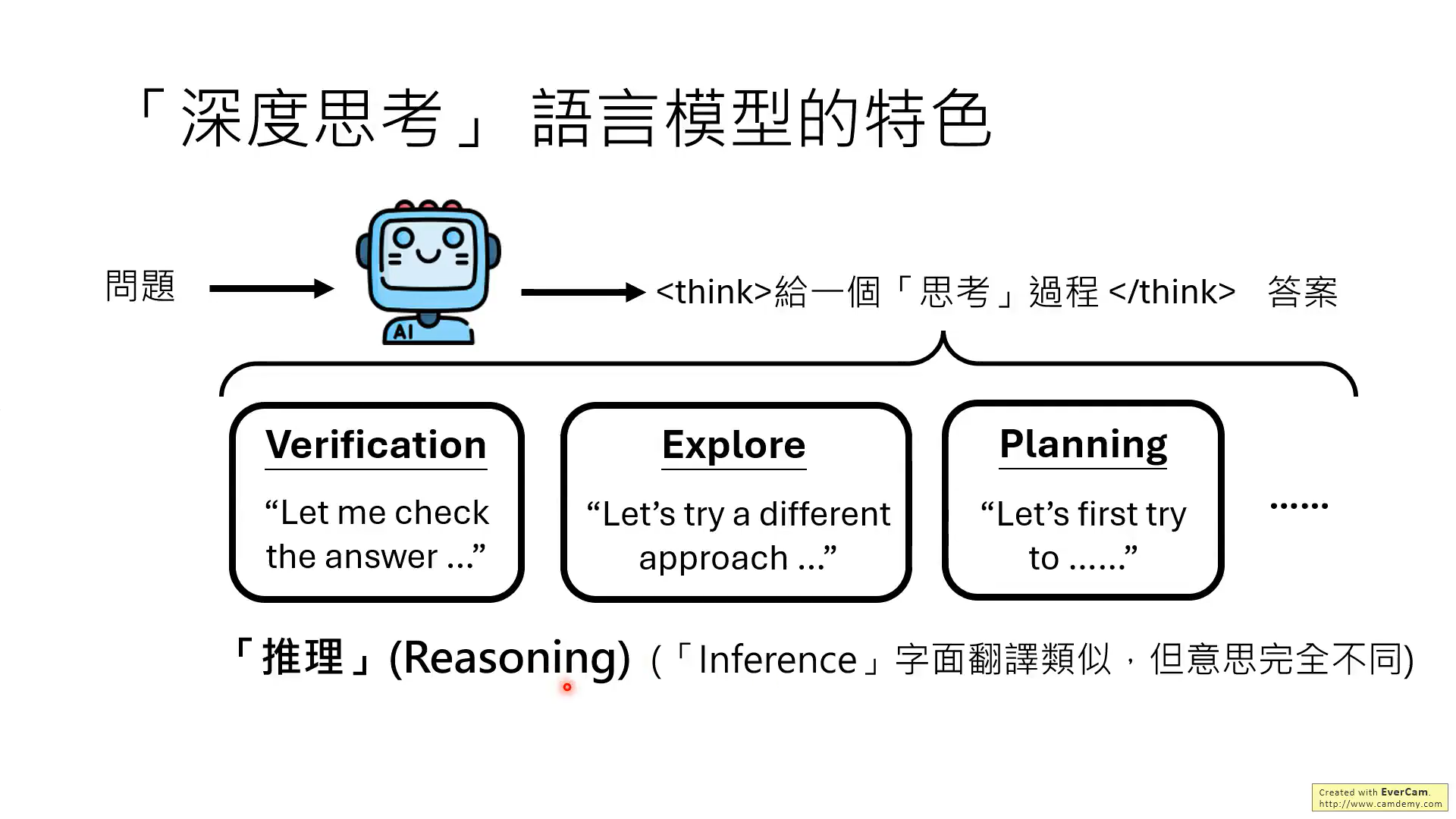
对于reason和inference,这两个词有不同的含义!
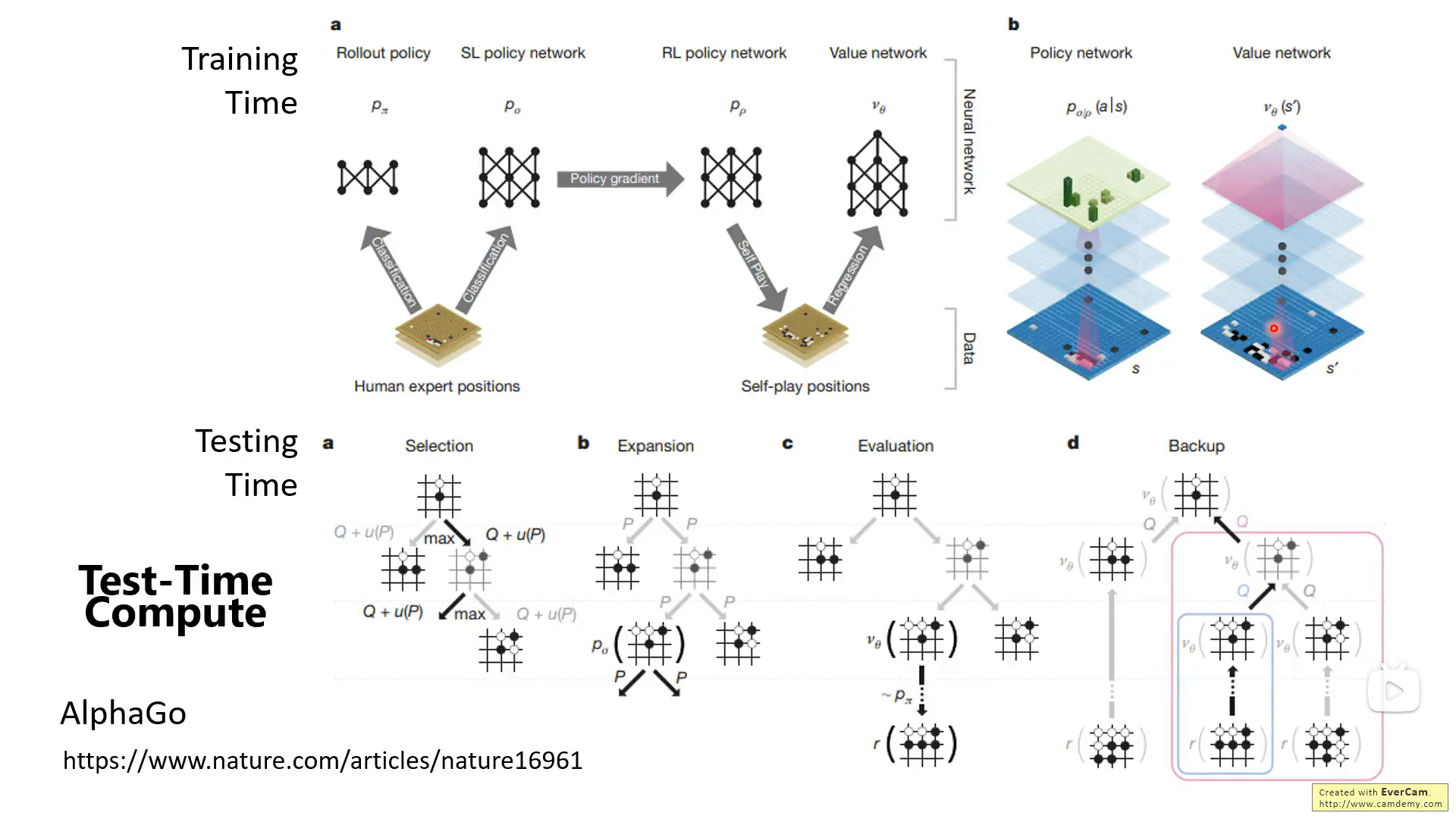
推理时计算不是新鲜事,AlphaGo就是如此。
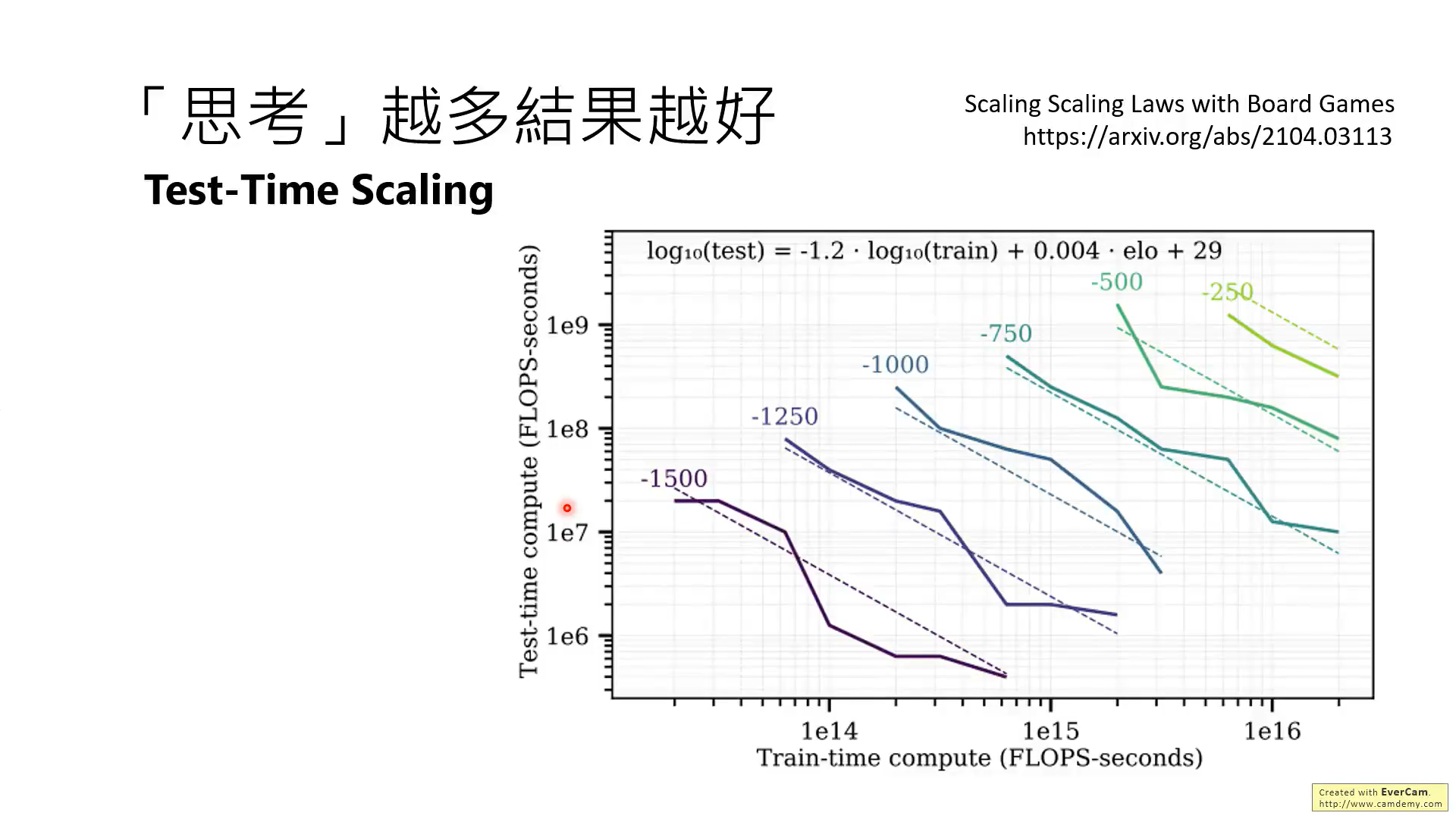
这张图片说明了将训练和推理时计算综合考虑的关系,-1500到-250这些数值表示模型的准确度。
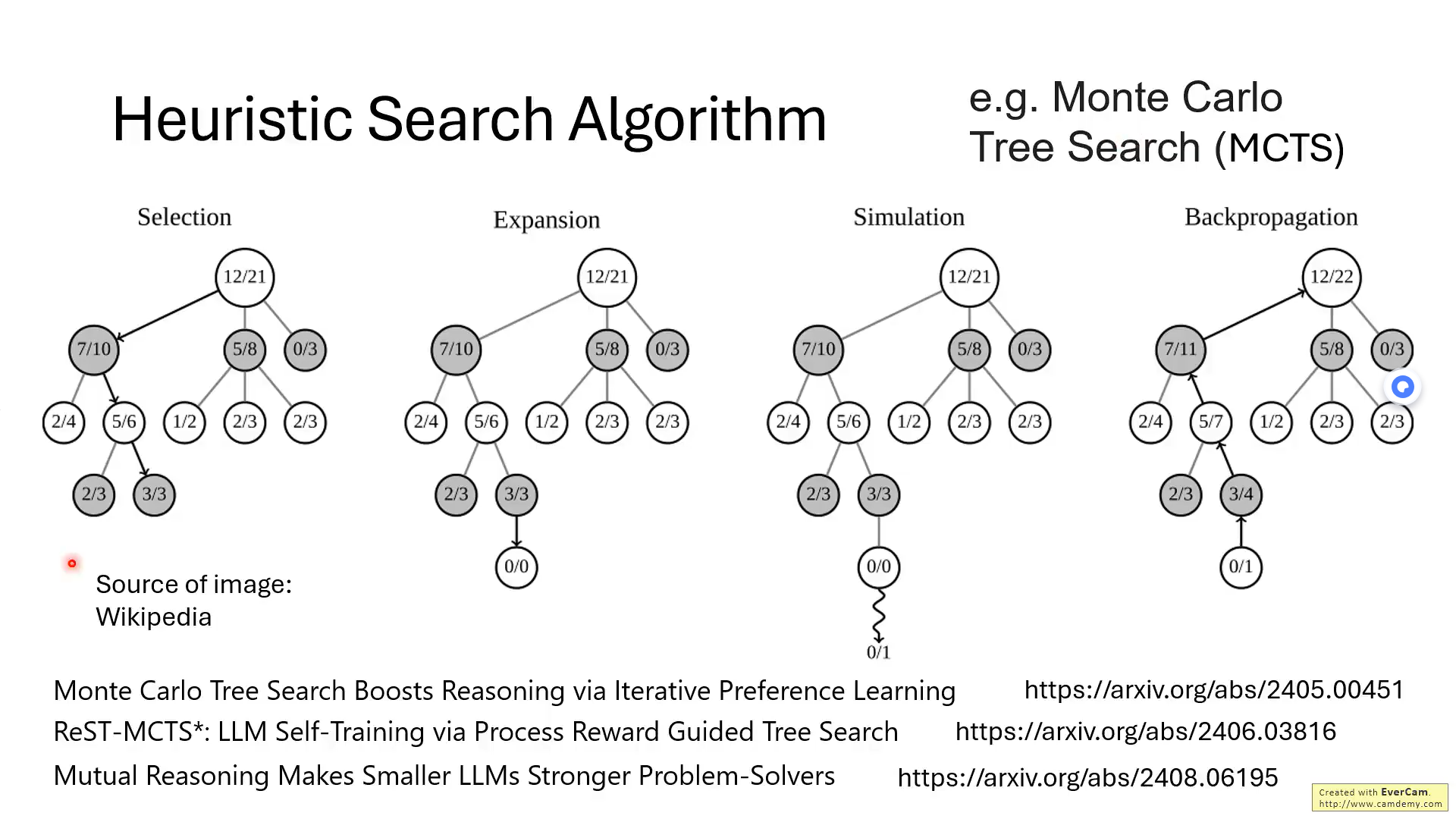
这张图片有关MCTS用于推理模型的几篇主要论文。
下面是两种需要微调模型的方法。
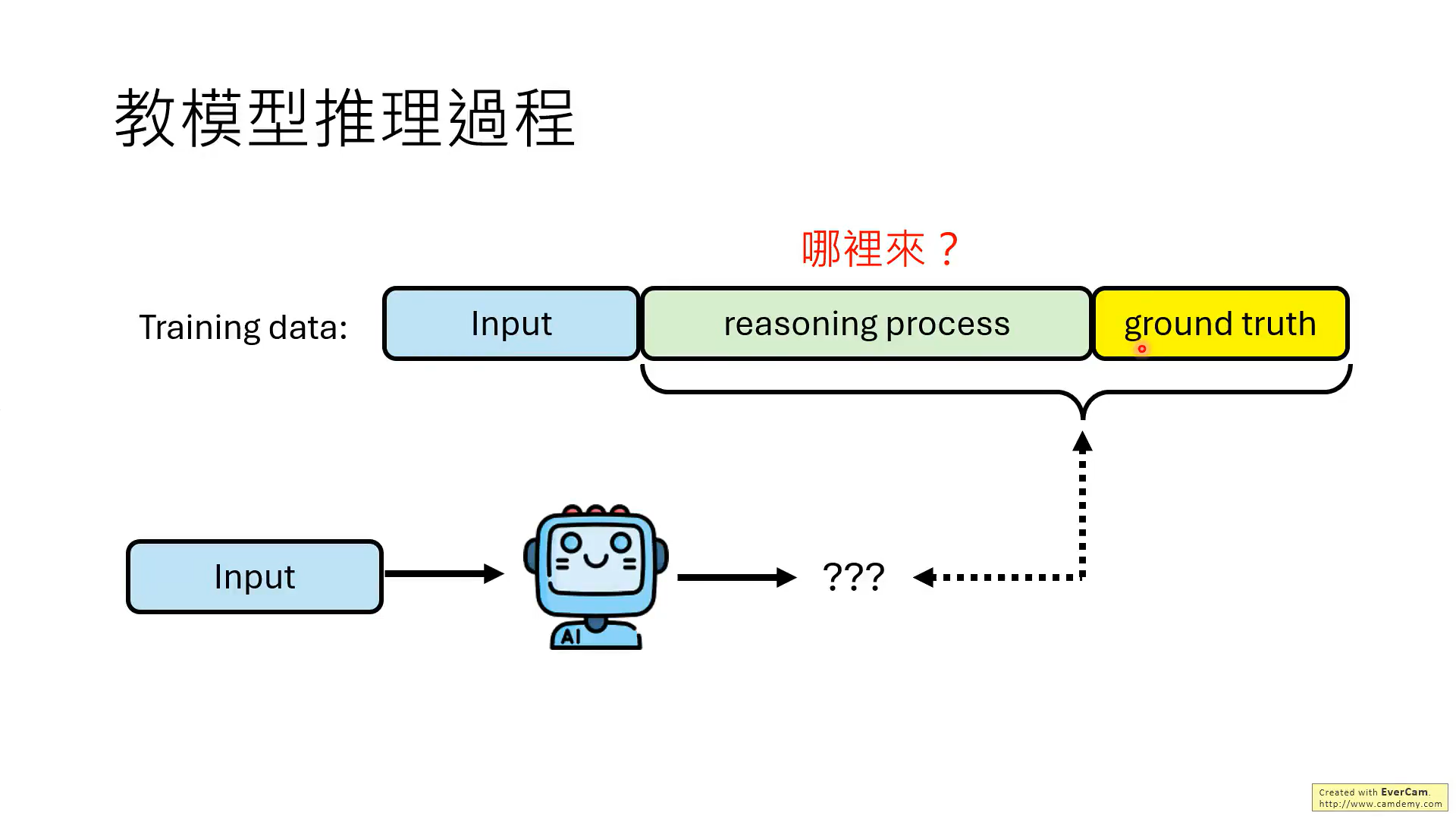
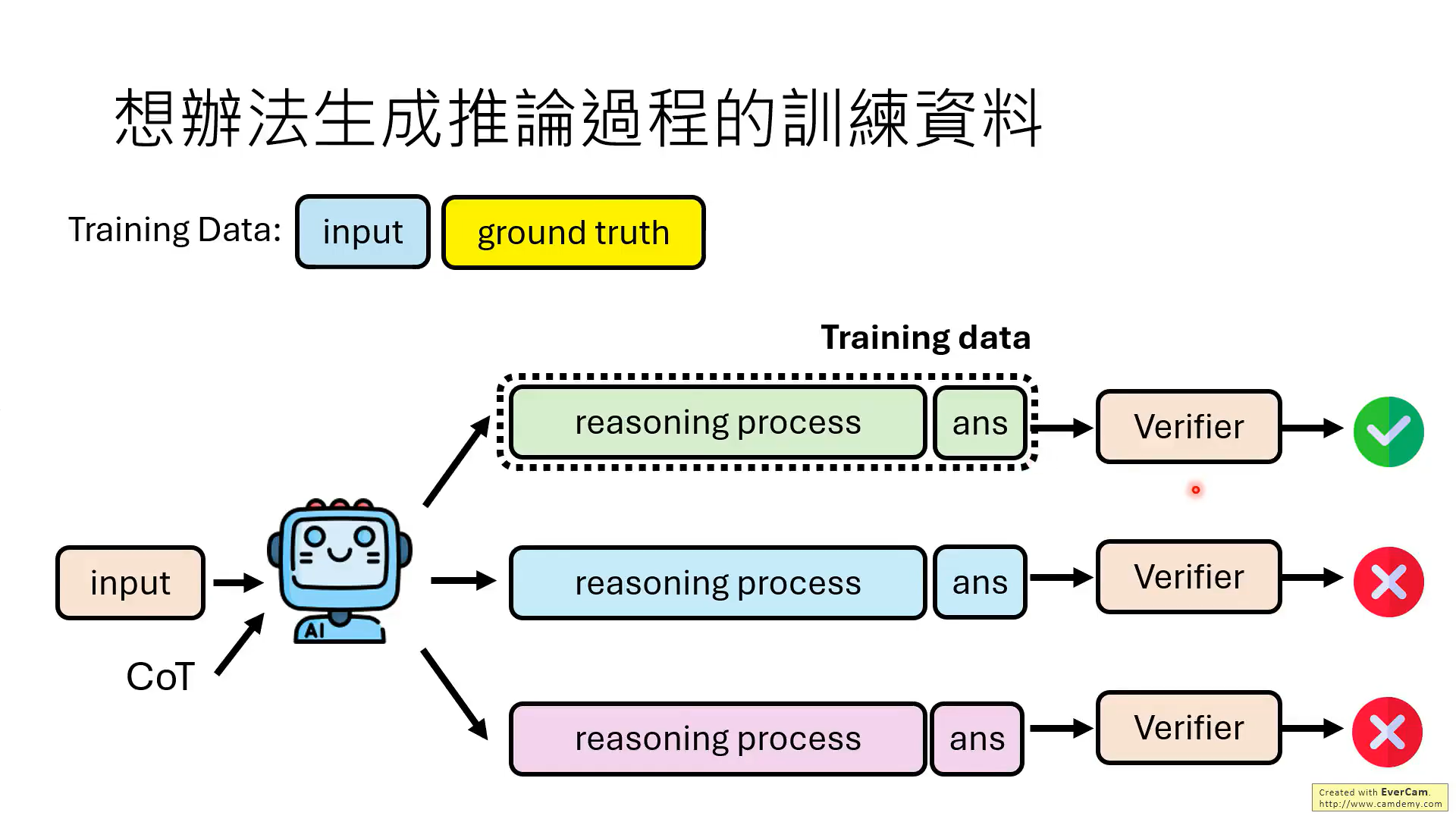
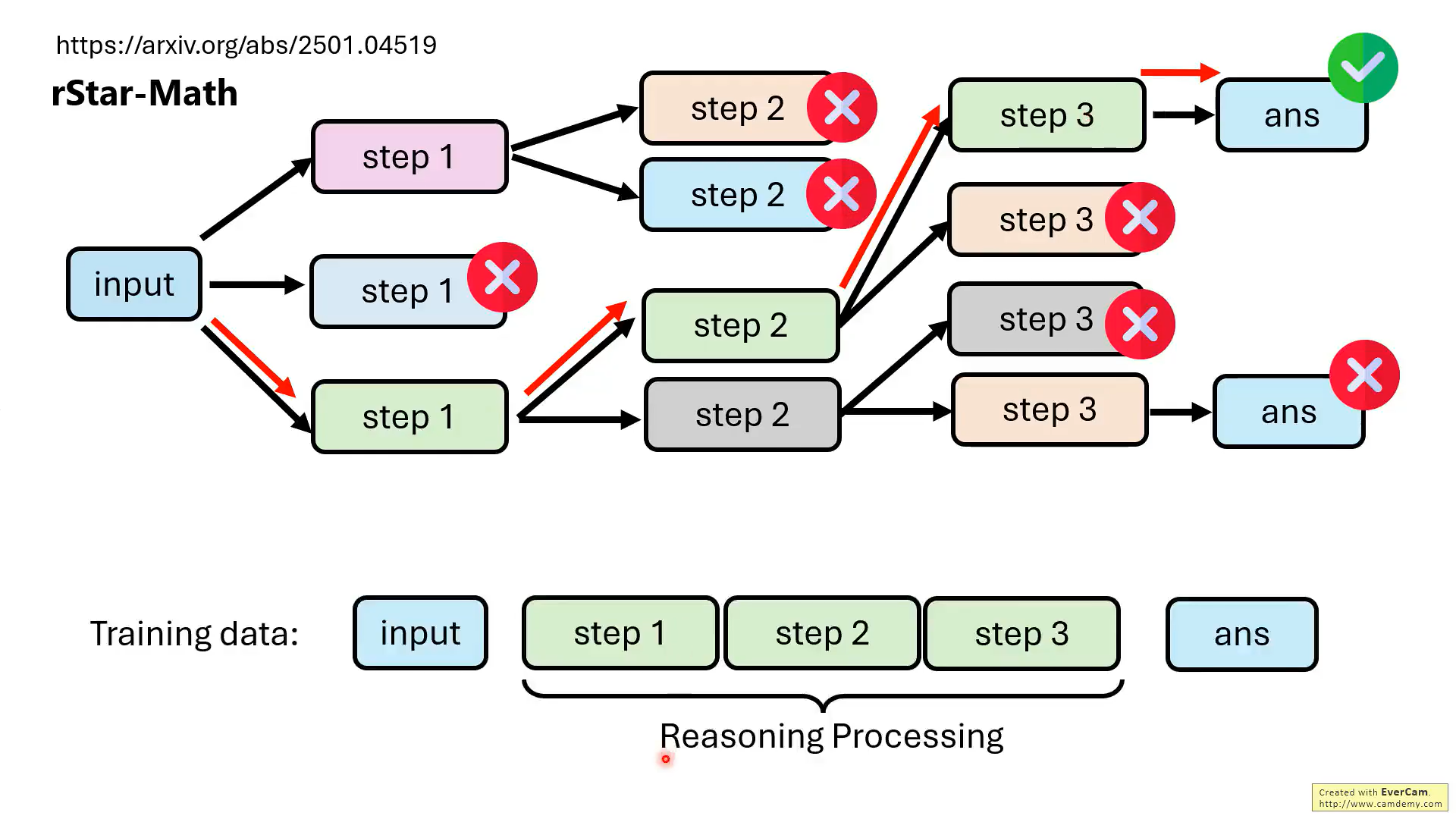
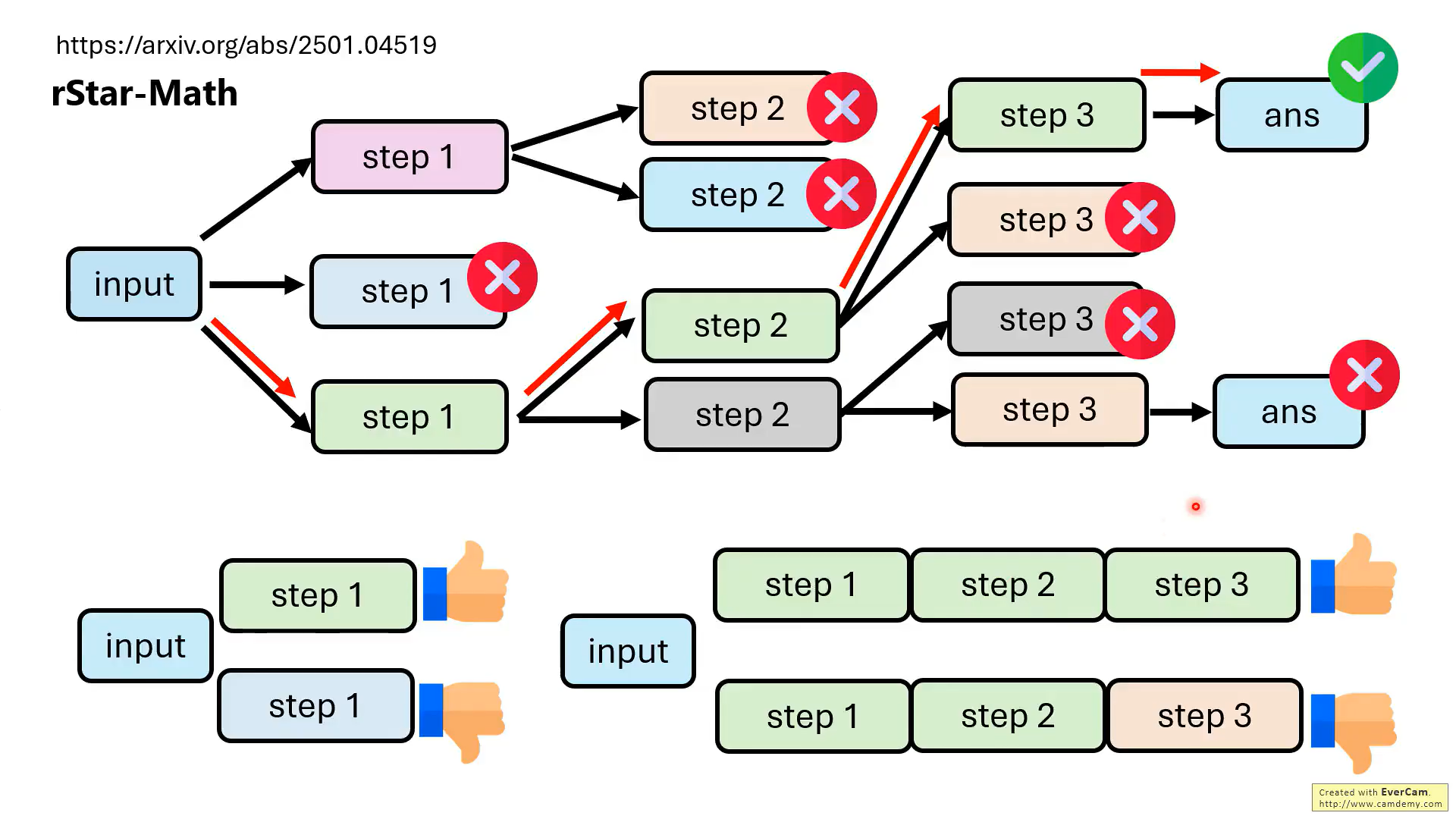

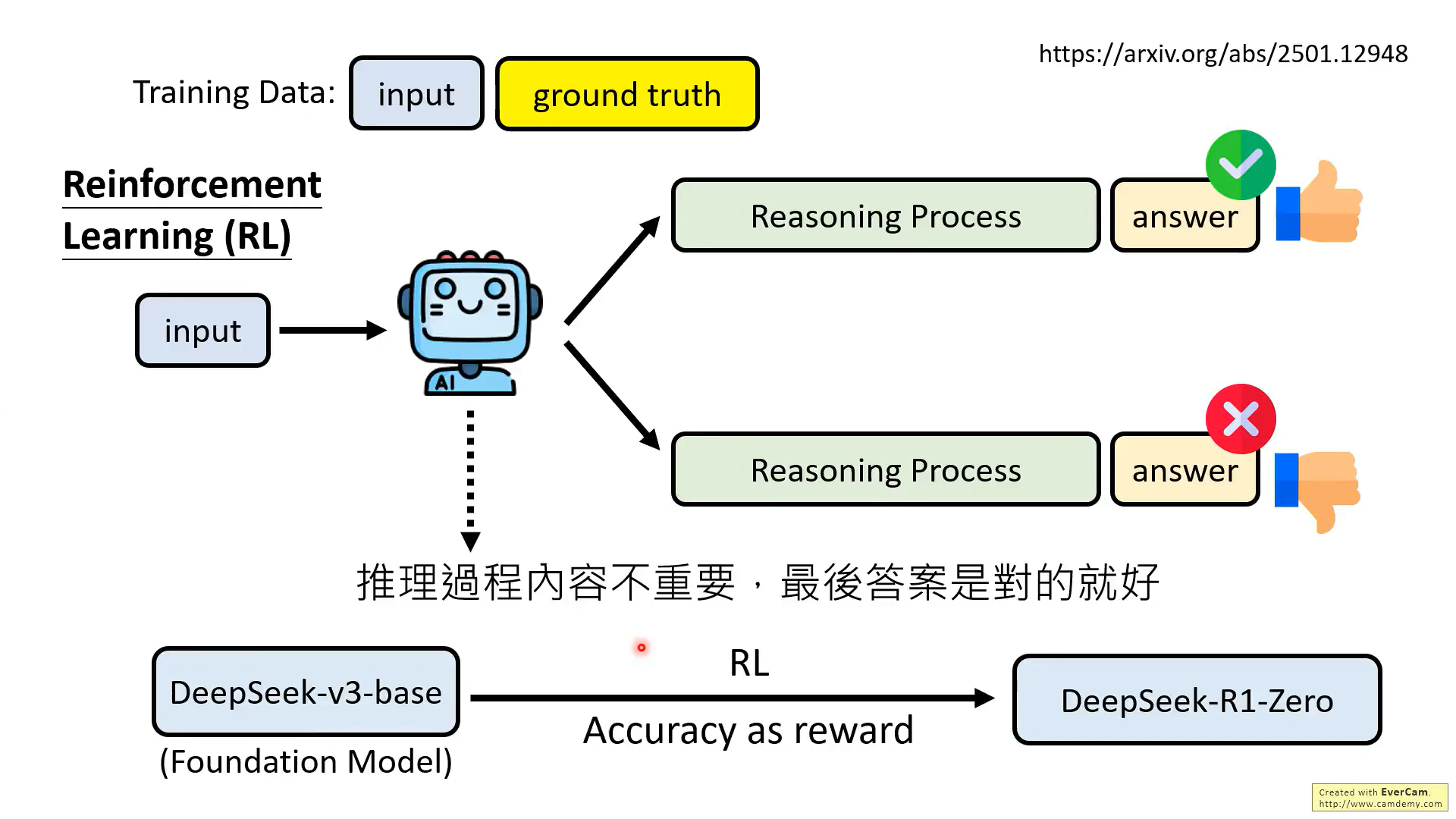
但是,实际上,并不需要模型每一步推理都是对的,最后结果对就可以。
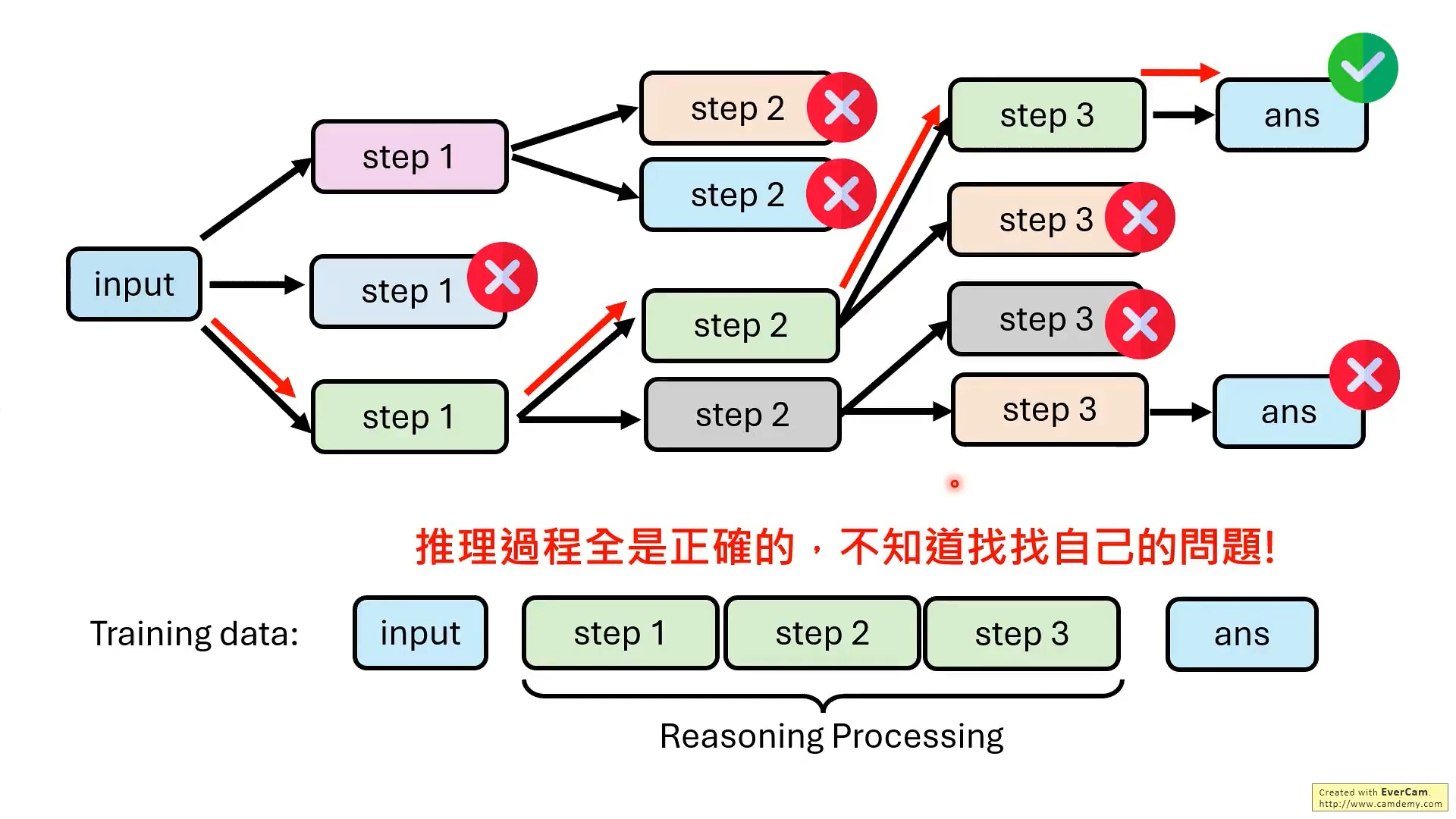
关键是要教会模型知错能改!!那如何教?
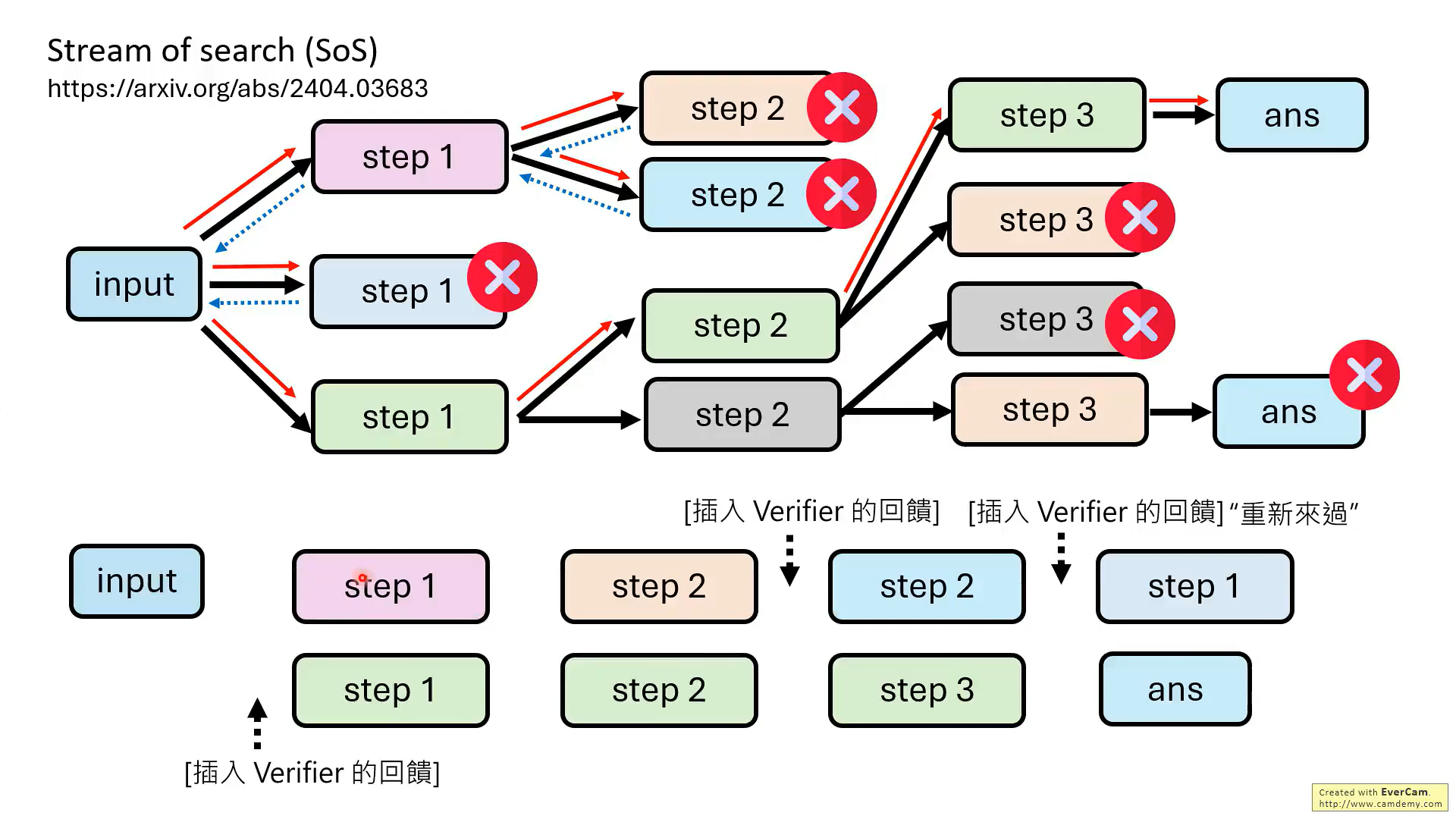
SoS这篇论文的意思,就是把错误的推理过程也加入训练数据,形成带有错误推理步骤的训练数据。
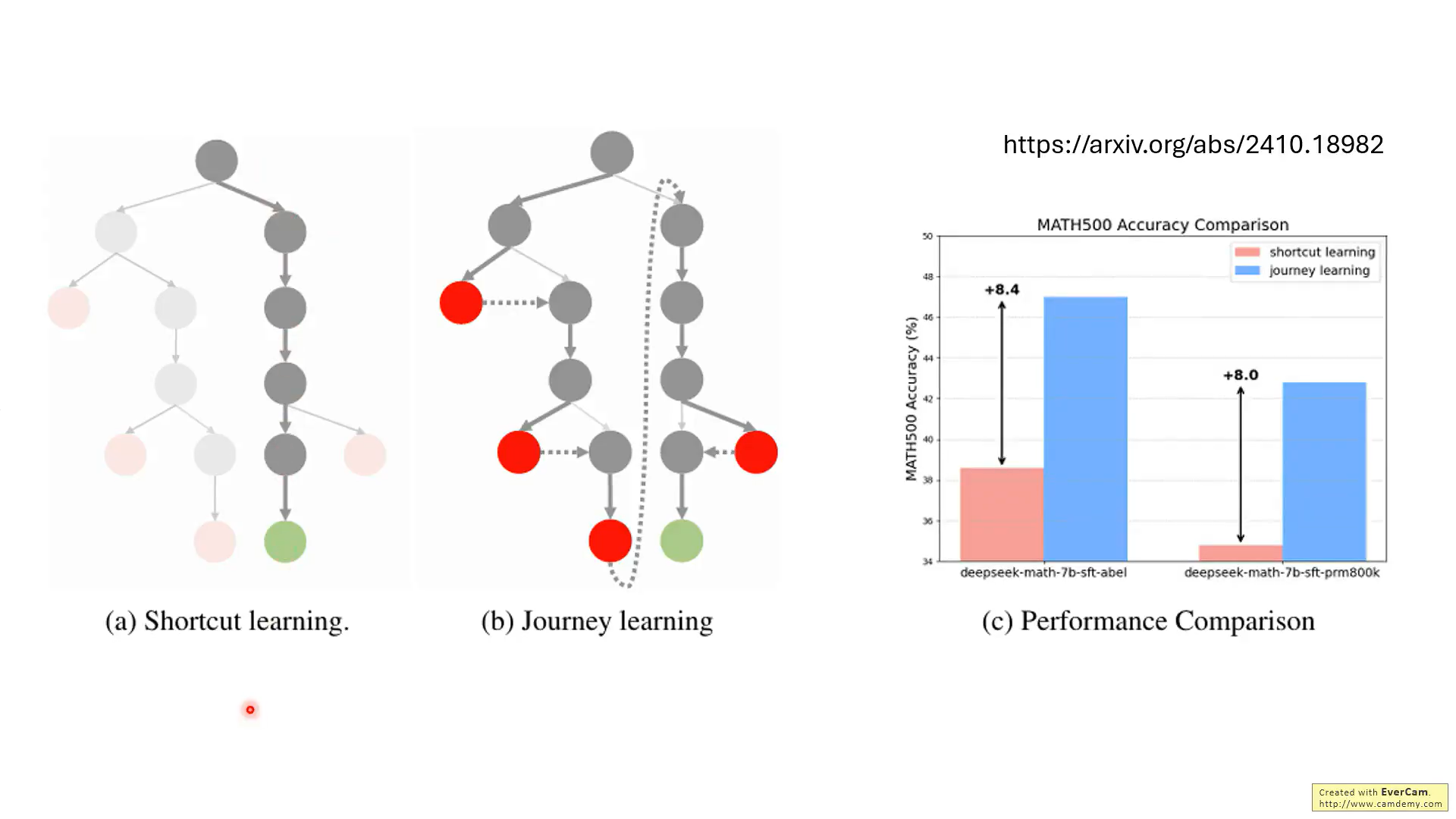
这篇论文也类似,在推理过程中包含错误的步骤。
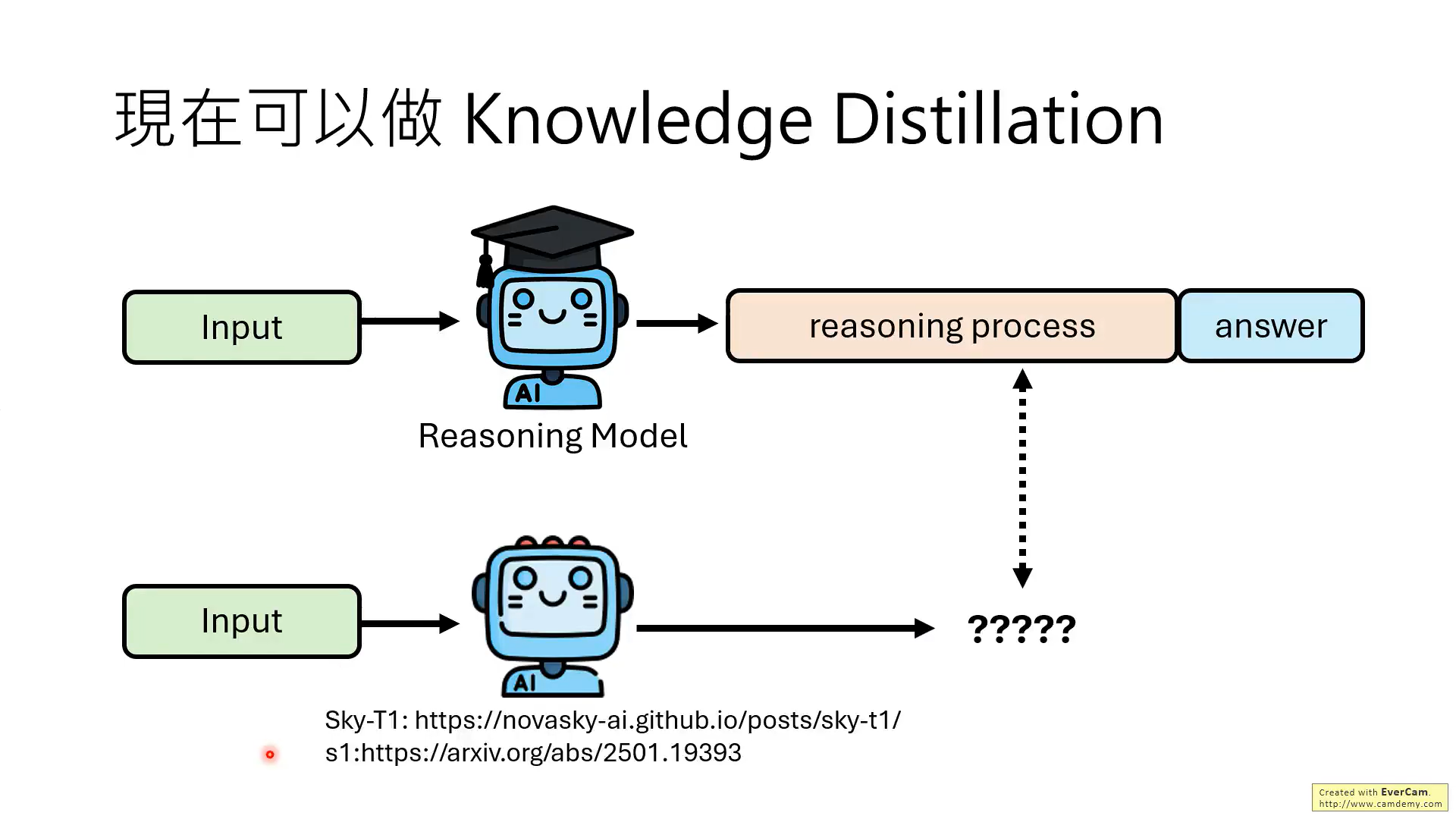
这就是知识蒸馏,如Sky-T1、s1等
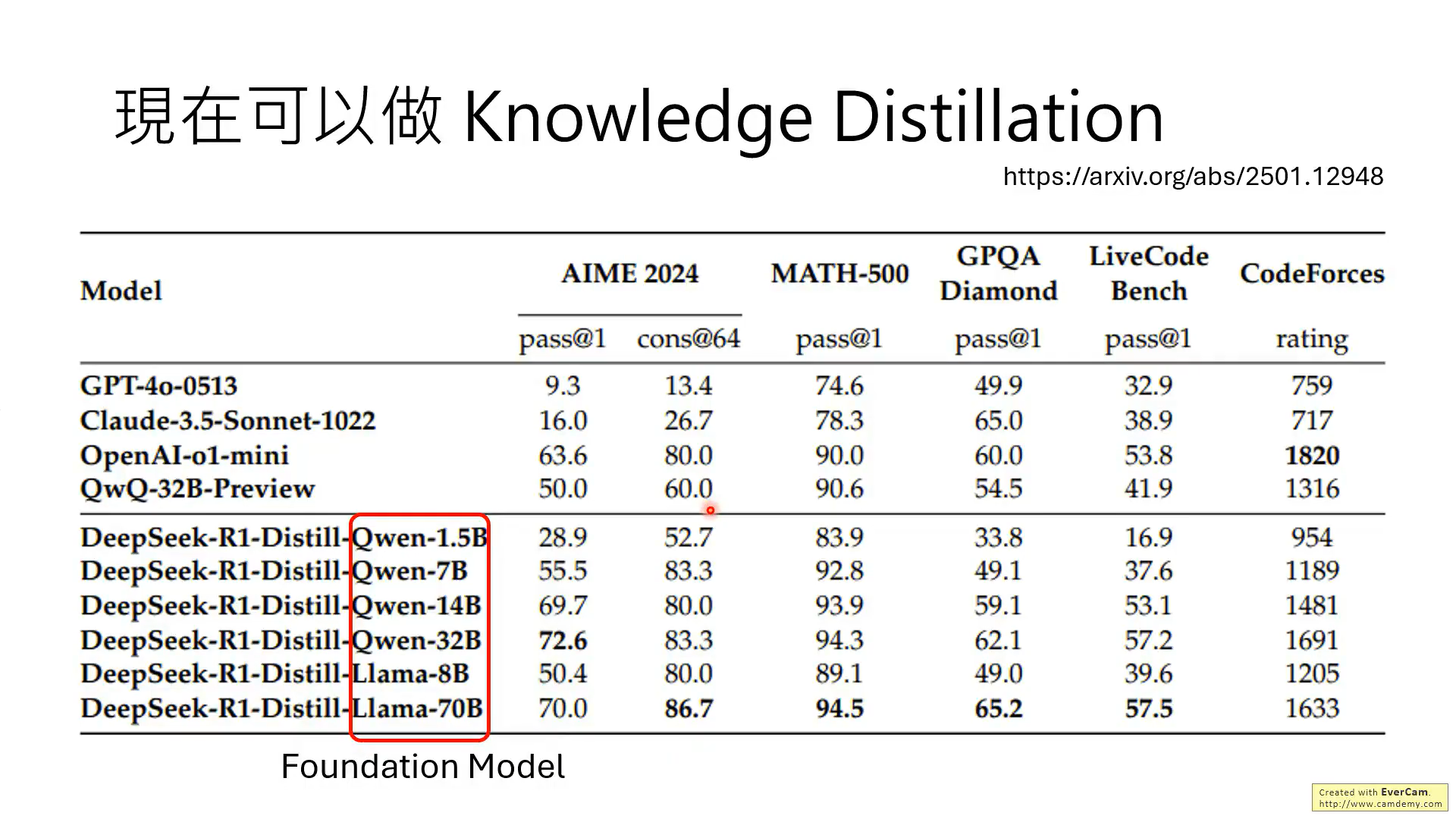
可以看到通过Deepseek-R1蒸馏基础模型后的性能提升。
最后一种方法,只看结果的RL方法,就是DeepSeek的方法
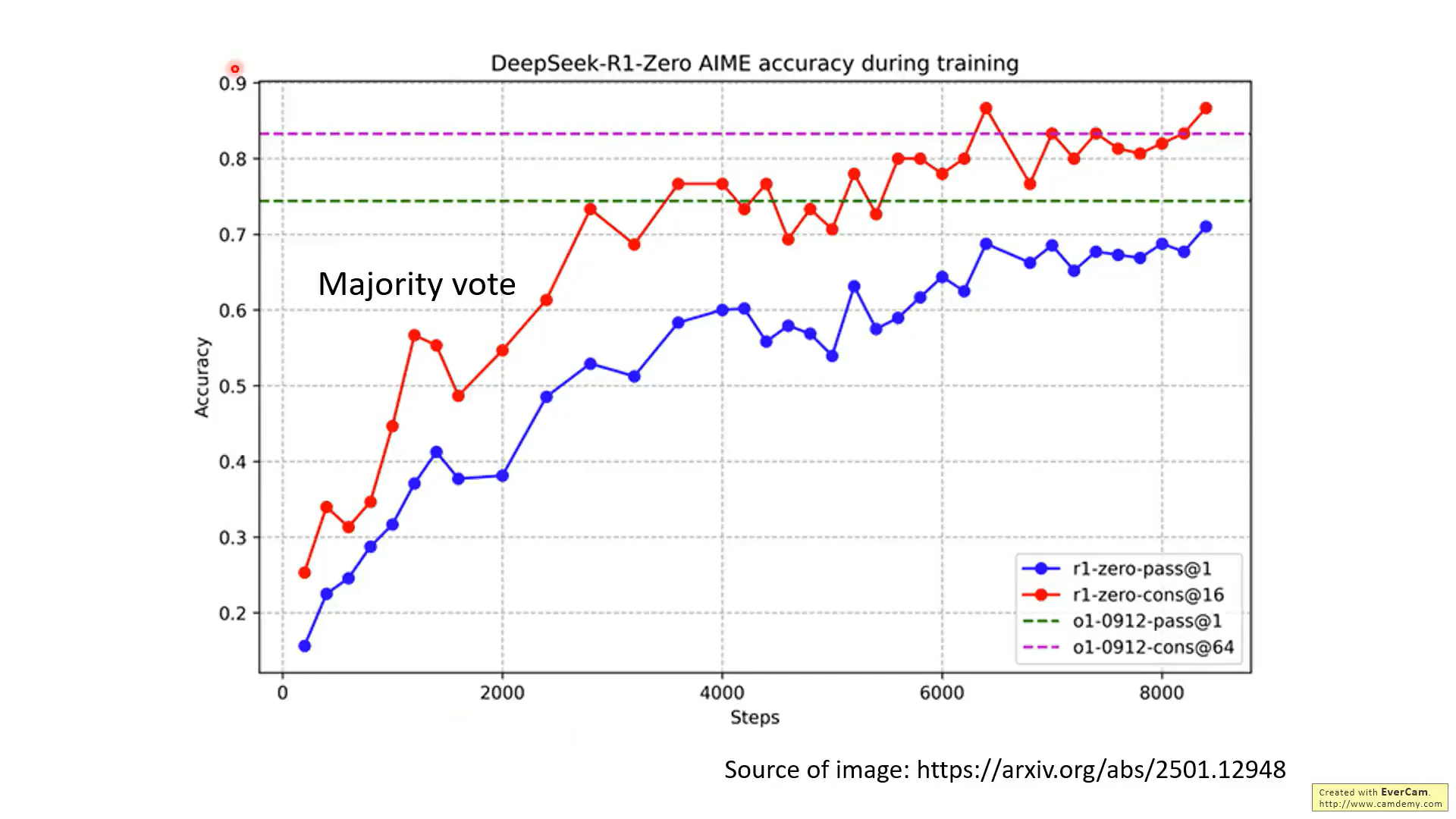
这张图展现了R1推理16次后再通过投票的性能增益,这也说明,深度思考的几种方法,是可以结合的,这里就是把RL和前面的Best of N进行了结合。

Aha时刻
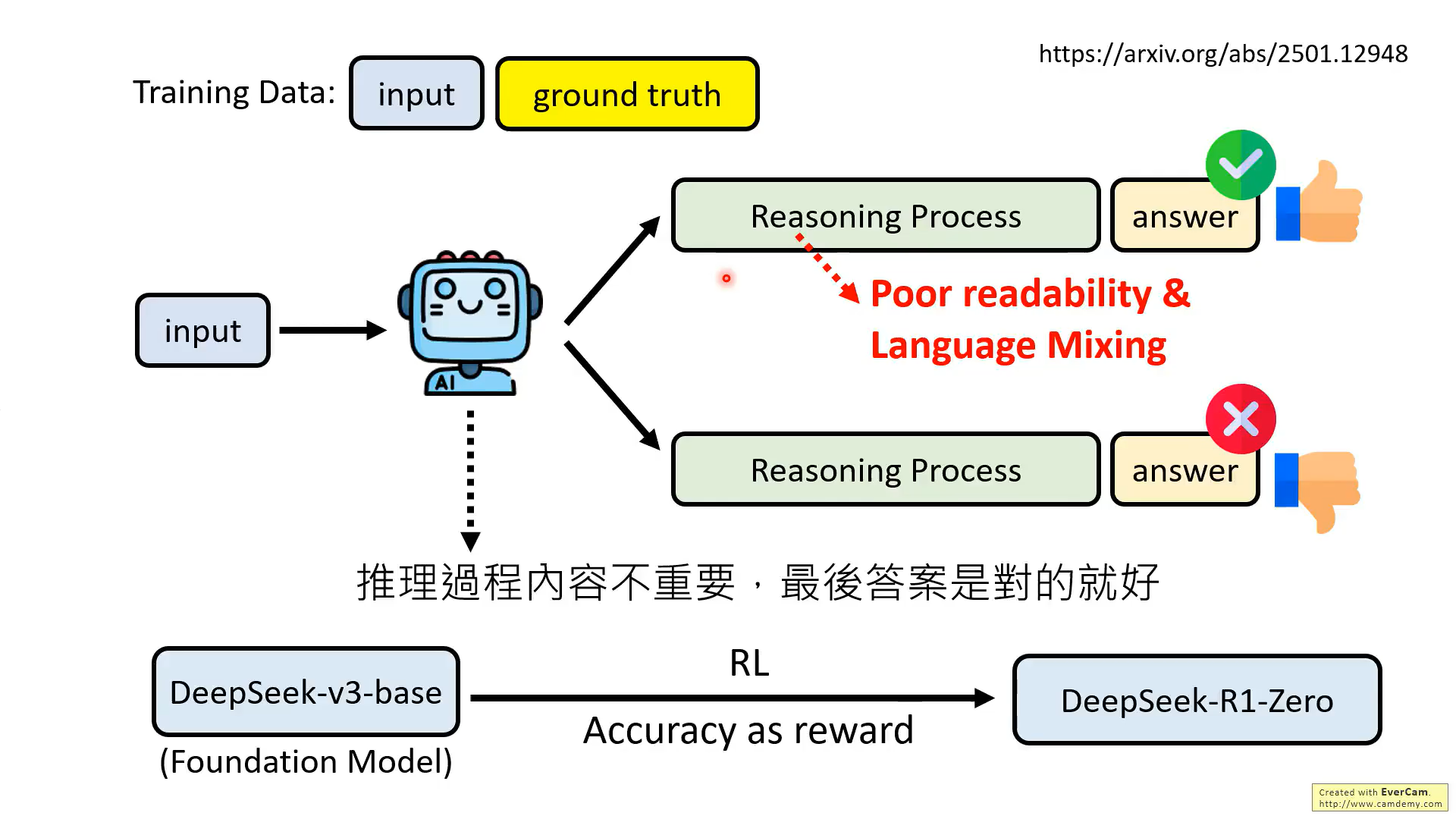
但是R1-zero并没有拿出来用,只看重结果,导致输出的推理过程可读性差
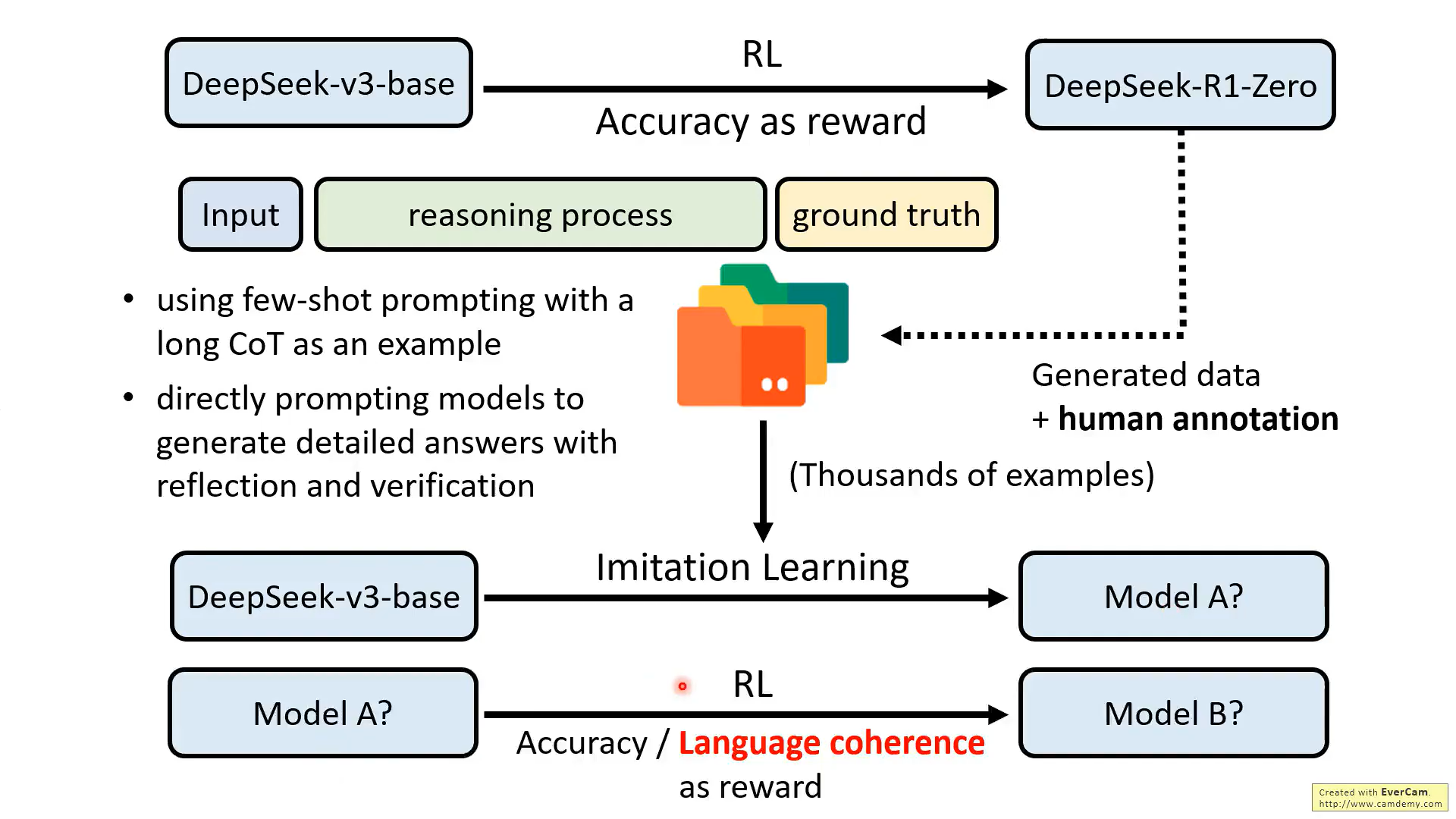
在R1训练中的几个重点:
1、前面的几种方法都有用到,而不是单纯的RL
2、R1-Zero生成推理数据,用于训练下一个模型,但是R1-zero输出的数据可读性差,所以需要大量的人力矫正,而这个过程R1技术报告说得并不清楚
3、另外还需要通过few shot方式的提示和让模型生成带有反思和验证的提示,来由另一个模型产生数据,这个过程的具体情况也不清楚
4、最后模型训练,在准确性的基础上增加了语言一致性的目标,这样会导致性能略微下降,但是增强可读性,所以还是用了这种方式。
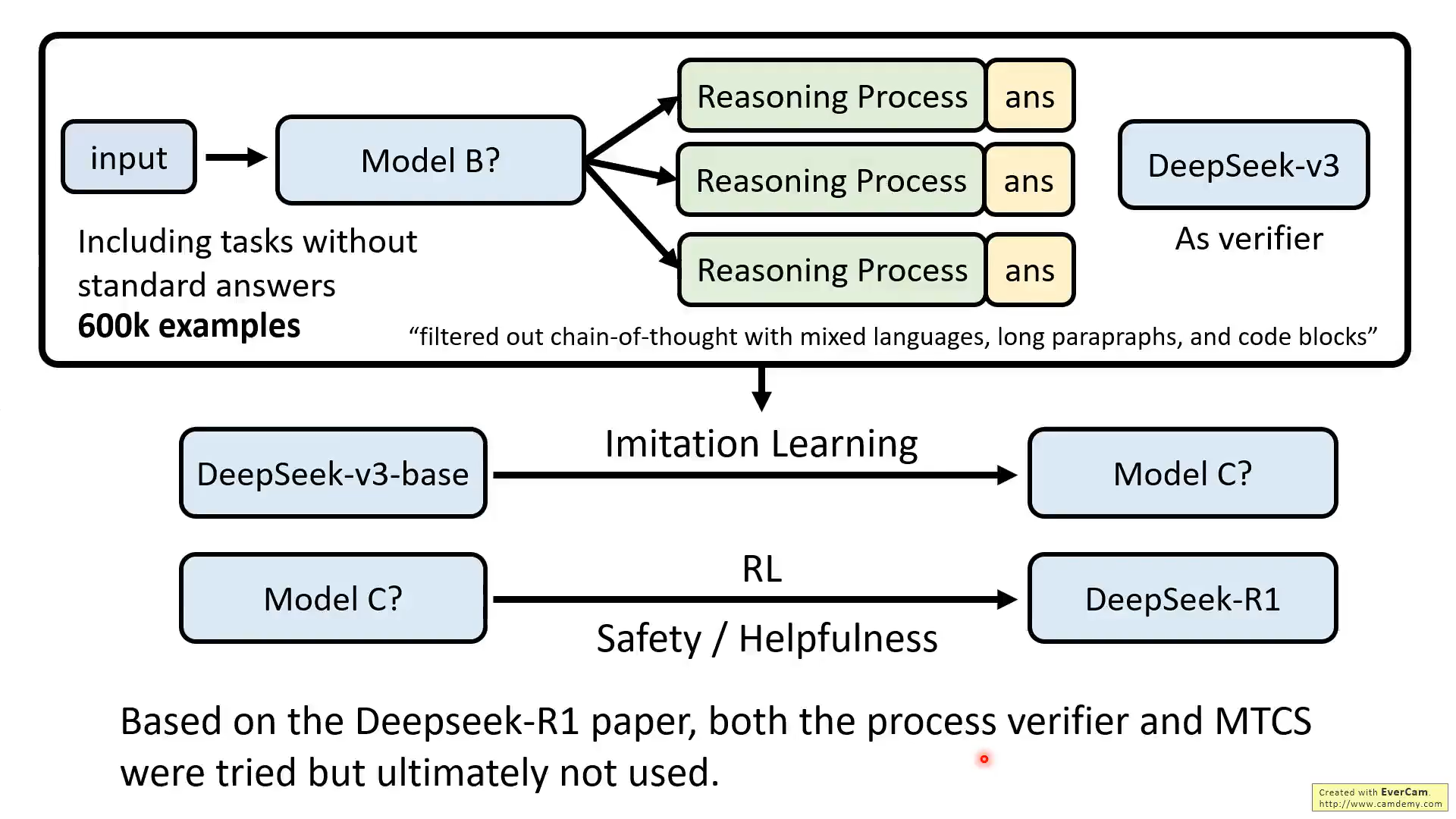
然后这个Model B还是用来生成数据,同时这个数据需要V3作为验证器,评估正确性,以及过滤数据
最后Model C再经过RL获得最终的R1,但是这个RL的过程在技术报告描述的不详细。

R1推理过程中有一些奇怪的输出,例如缺了括号、语言混乱,说明推理过程并没有人的监督
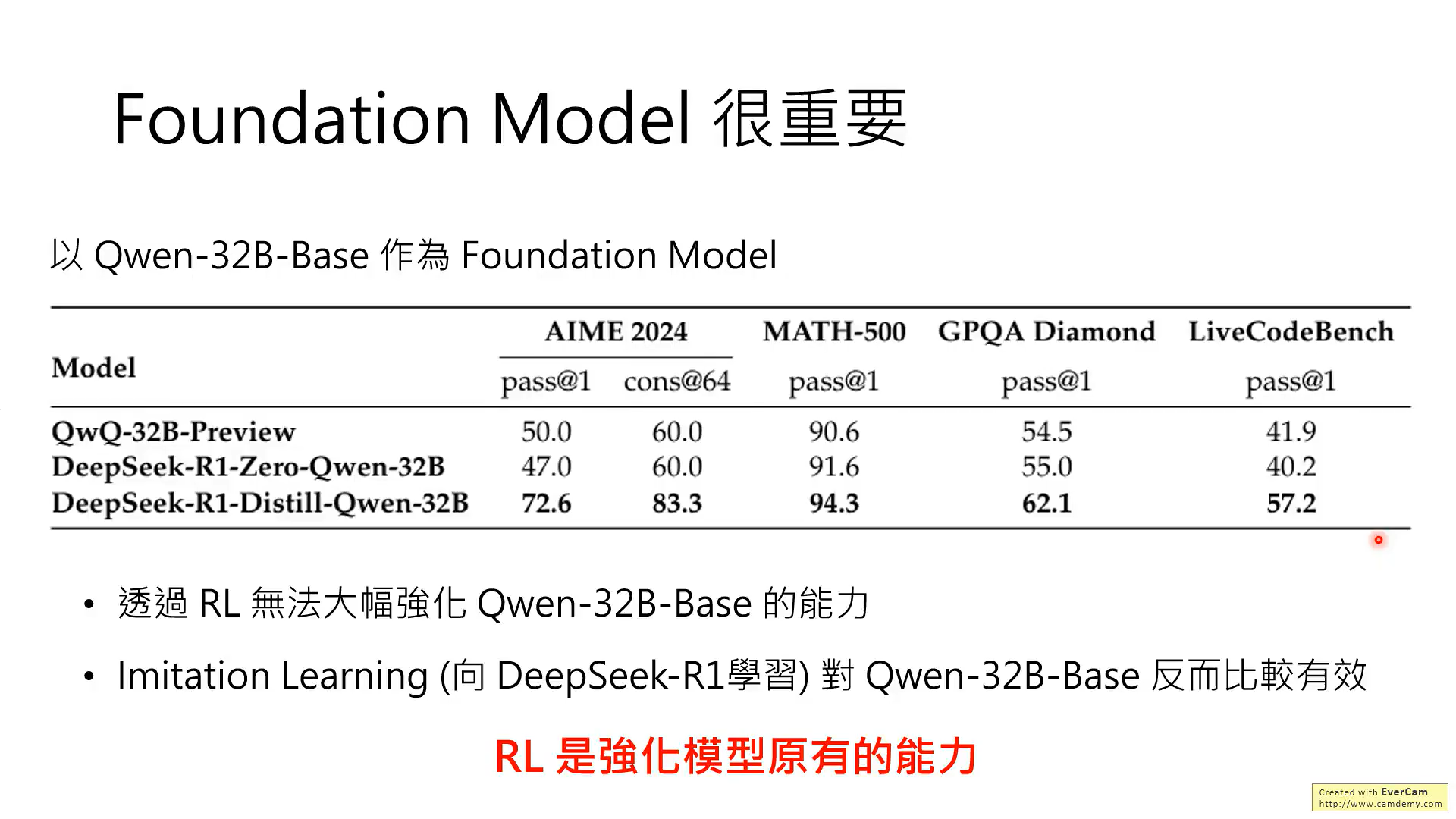
这张图是说,小的模型上使用RL的方法行不通
背后的原因可能性:RL只是强化基础模型的能力,就是说,基础模型作对了,奖励,做错了,惩罚,来强化作对的能力,但是前提是基础模型需要有作对的能力!!
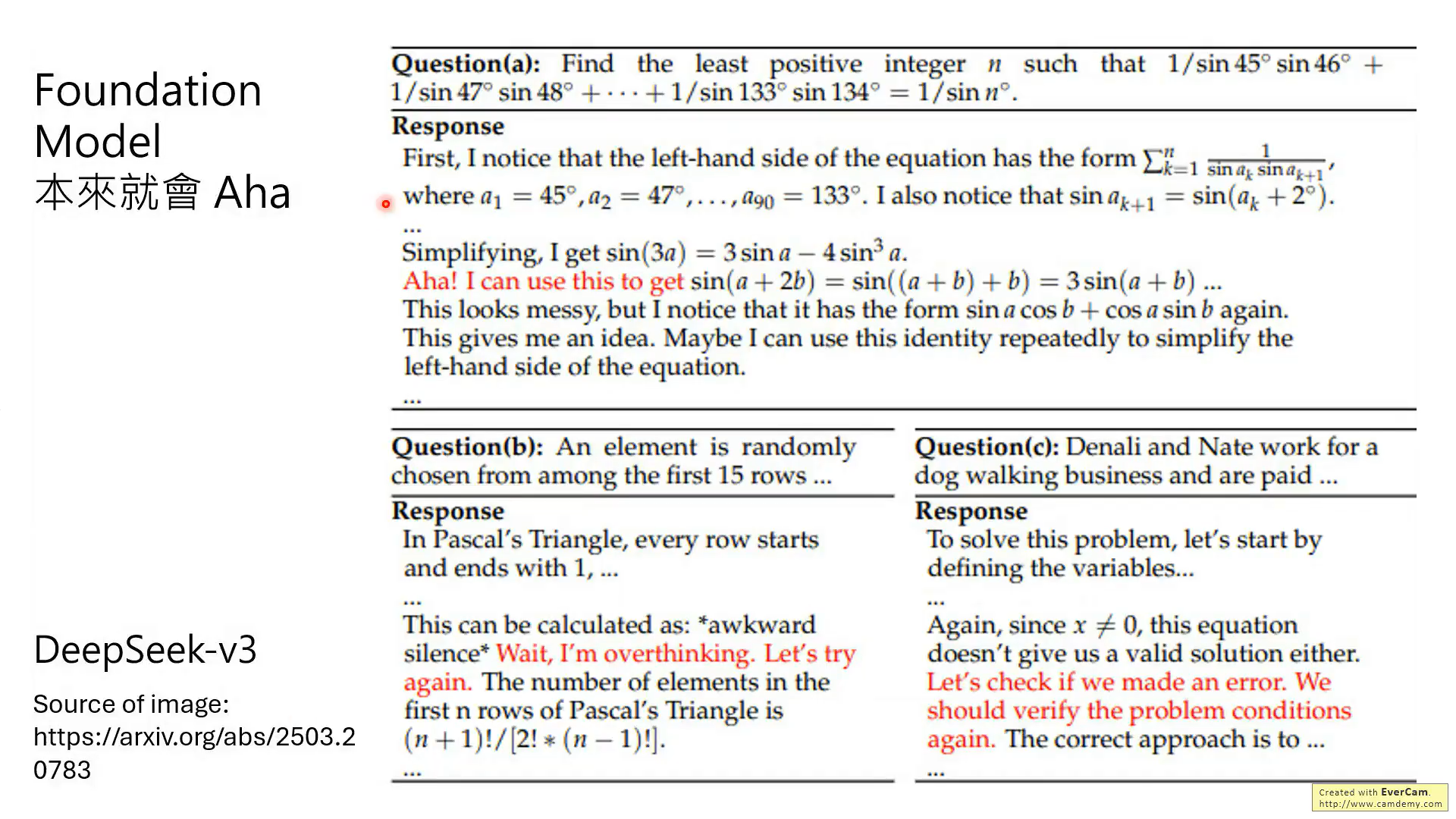
所以,相关论文就发现,V3本身就是有Aha能力,R1只是强化这种能力
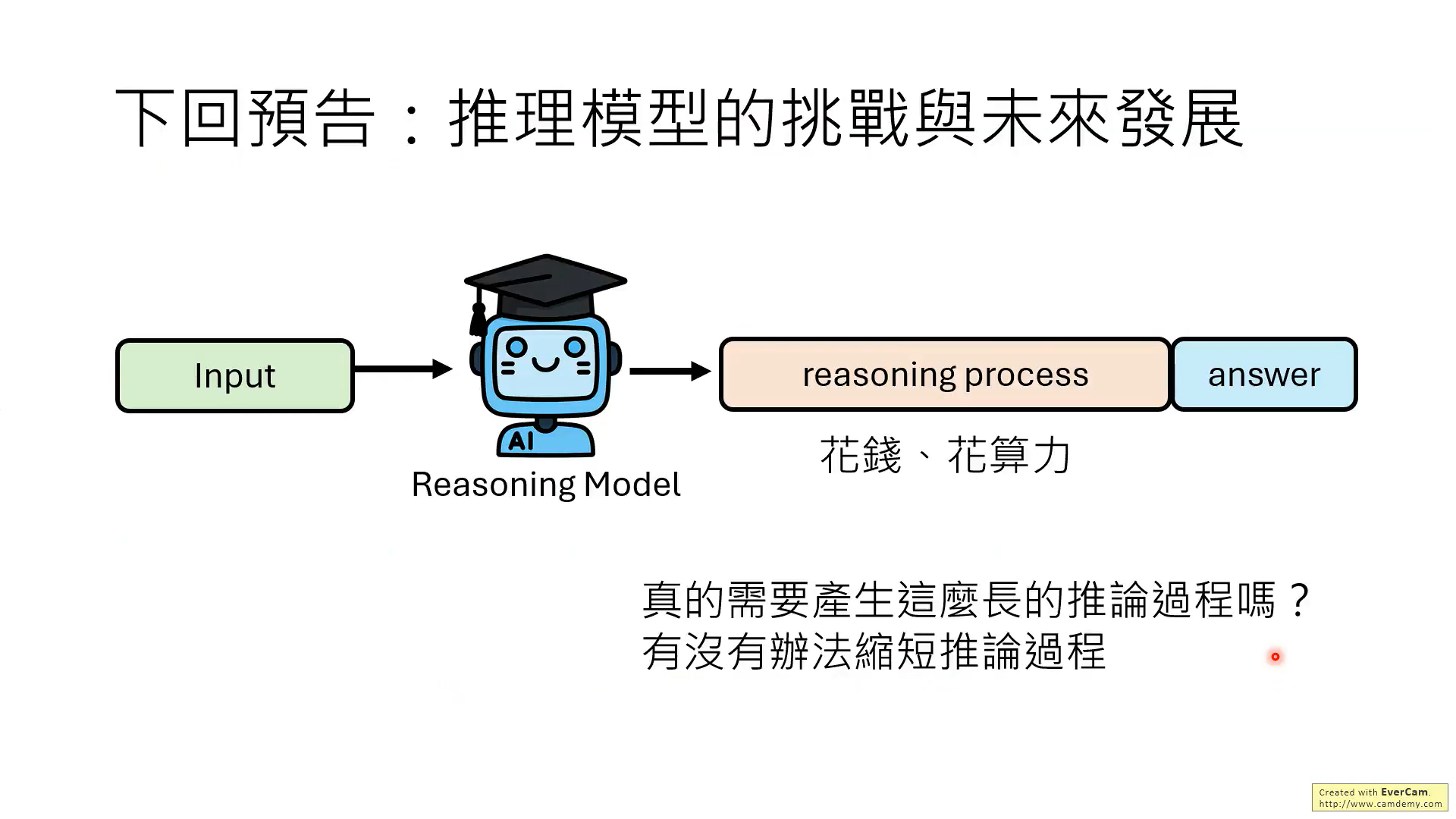
接下来探讨推理模型的问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











